MetaCaptioner: Towards Generalist Visual Captioning with Open-source Suites
作者: Zhenxin Lei, Zhangwei Gao, Changyao Tian, Erfei Cui, Guanzhou Chen, Danni Yang, Yuchen Duan, Zhaokai Wang, Wenhao Li, Weiyun Wang, Xiangyu Zhao, Jiayi Ji, Yu Qiao, Wenhai Wang, Gen Luo
分类: cs.CV
发布日期: 2025-10-14 (更新: 2025-10-16)
💡 一句话要点
提出CapFlow多智能体协作流程,结合MetaCaptioner,实现媲美GPT-4.1的通用视觉描述能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉描述 多智能体协作 开源模型 数据合成 多模态学习
📋 核心要点
- 现有开源视觉描述模型在性能上与商业模型存在较大差距,限制了数据合成等下游任务的应用。
- 论文提出CapFlow多智能体协作流程,利用开源模型,以较低成本实现媲美GPT-4.1的描述质量。
- 通过CapFlow合成高质量数据,微调得到MetaCaptioner,在通用视觉描述任务上达到与商业模型相当的水平。
📝 摘要(中文)
通用视觉描述超越了简单的外观描述,需要将一系列视觉线索整合到描述中,并处理各种视觉领域。目前开源模型与商业模型之间存在巨大的性能差距,限制了数据合成等应用。为了弥合这一差距,本文提出了CapFlow,一种新颖的多智能体协作工作流程。CapFlow首次证明,通过利用开源模型,可以在各种领域实现与GPT-4.1相当的描述质量,同时成本降低89.5%。通过利用CapFlow作为数据合成器,我们大规模地从图像和视频领域生成高质量的视觉描述,并通过微调获得了一个通用视觉描述器,即MetaCaptioner。通过广泛的实验,我们表明MetaCaptioner不仅实现了与商业模型相当的描述能力,而且在开源社区中达到了顶级的多模态性能。我们希望CapFlow和MetaCaptioner能够通过提供强大且经济高效的视觉描述解决方案,使未来的多模态研究受益。
🔬 方法详解
问题定义:通用视觉描述任务需要模型能够整合多种视觉信息,并适应不同的视觉领域。现有开源模型在性能上与商业模型存在较大差距,难以满足实际应用需求,尤其是在数据合成方面。开源模型的痛点在于难以在保证质量的同时兼顾成本和效率。
核心思路:论文的核心思路是利用多智能体协作的方式,将复杂的视觉描述任务分解为多个子任务,并分配给不同的开源模型来完成。通过合理的任务分配和协作机制,可以充分发挥各个模型的优势,从而提高整体的描述质量和效率。这种方法旨在以较低的成本达到甚至超越商业模型的性能。
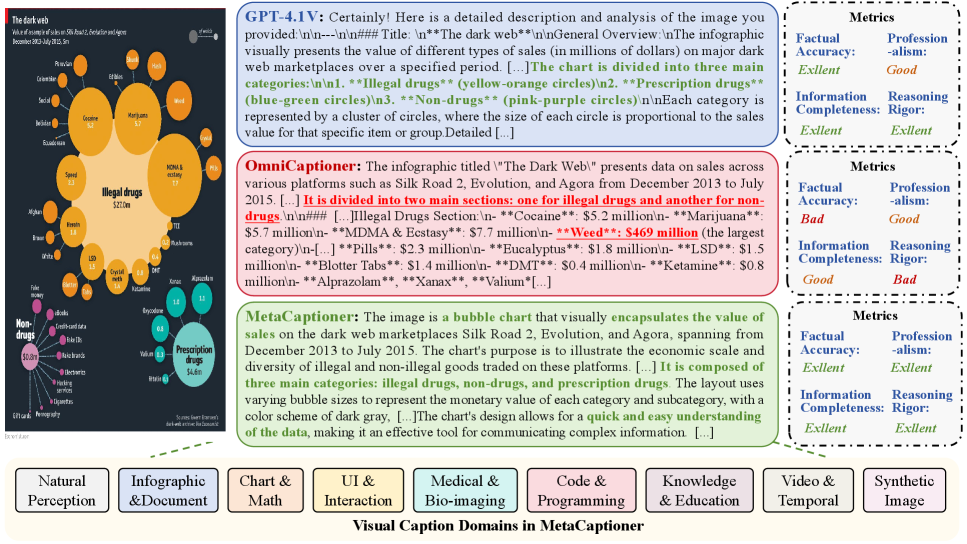
技术框架:CapFlow 的整体框架是一个多智能体协作流程,包含以下主要阶段:1) 图像/视频输入;2) 多个开源模型作为智能体,分别负责不同的子任务,例如目标检测、属性识别、关系推理等;3) 协作机制,用于协调各个智能体的输出,并生成最终的视觉描述;4) MetaCaptioner,一个通过CapFlow合成数据进行微调的通用视觉描述模型。
关键创新:CapFlow 的关键创新在于其多智能体协作的架构,它能够有效地利用现有的开源模型,并通过协作机制将它们整合起来,从而实现高性能的视觉描述。此外,利用CapFlow合成高质量数据,并微调MetaCaptioner,进一步提升了模型的泛化能力和性能。这种方法避免了从头训练大型模型的需要,降低了成本。
关键设计:CapFlow 的关键设计包括:1) 智能体的选择和配置,需要根据不同的子任务选择合适的开源模型,并进行适当的配置;2) 协作机制的设计,需要考虑如何有效地整合各个智能体的输出,并生成一致且准确的视觉描述;3) MetaCaptioner 的训练策略,需要选择合适的损失函数和优化器,并进行充分的训练,以获得最佳的性能。具体的参数设置和网络结构细节在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片


📊 实验亮点
CapFlow首次证明,通过利用开源模型,可以在各种领域实现与GPT-4.1相当的描述质量,同时成本降低89.5%。MetaCaptioner在通用视觉描述任务上达到了与商业模型相当的性能,并在开源社区中取得了领先的多模态性能。这些实验结果表明,CapFlow和MetaCaptioner具有很强的实用价值和竞争力。
🎯 应用场景
该研究成果可广泛应用于数据合成、智能客服、图像/视频检索、辅助驾驶等领域。MetaCaptioner可以作为一种低成本、高性能的视觉描述解决方案,为各种多模态应用提供支持。通过自动生成高质量的视觉描述,可以提高数据标注的效率,降低人工成本,并促进人工智能技术的发展。
📄 摘要(原文)
Generalist visual captioning goes beyond a simple appearance description task, but requires integrating a series of visual cues into a caption and handling various visual domains. In this task, current open-source models present a large performance gap with commercial ones, which limits various applications such as data synthesis. To bridge the gap, this paper proposes CapFlow, a novel multi-agent collaboration workflow. CapFlow demonstrates for the first time that, by capitalizing on open-source models, it is possible to achieve caption quality on par with GPT-4.1 in various domains with an 89.5% reduction in costs. By leveraging CapFlow as the data synthesizer, we produce high-quality visual captions from image and video domains at scale, and obtain a generalist visual captioner via fine-tuning, namely MetaCaptioner. Through extensive experiments, we show that MetaCaptioner not only achieves comparable captioning capabilities with commercial models but also reaches top-tier multimodal performance in the open-source community. We hope CapFlow and MetaCaptioner can benefit future multimodal research by providing a strong and cost-effective visual captioning solution.