G4Splat: Geometry-Guided Gaussian Splatting with Generative Prior
作者: Junfeng Ni, Yixin Chen, Zhifei Yang, Yu Liu, Ruijie Lu, Song-Chun Zhu, Siyuan Huang
分类: cs.CV
发布日期: 2025-10-14
备注: Project page: https://dali-jack.github.io/g4splat-web/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
G4Splat:利用生成先验和几何引导的高质量高斯溅射重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景重建 高斯溅射 生成先验 几何引导 深度估计
📋 核心要点
- 现有方法利用生成先验进行3D重建时,缺乏可靠的几何监督,导致重建质量不高,尤其是在未观测区域。
- G4Splat利用平面结构推导精确深度图,提供几何引导,并将其融入生成流程,提升多视角一致性。
- 实验表明,G4Splat在Replica、ScanNet++和DeepBlending数据集上优于现有基线,尤其在未观测区域。
📝 摘要(中文)
本文提出了一种名为G4Splat的方法,旨在利用预训练扩散模型的生成先验进行3D场景重建。现有方法在缺乏可靠几何监督的情况下,难以生成高质量的重建结果,尤其是在未观测区域。此外,它们缺乏有效机制来缓解生成图像中的多视角不一致性,导致严重的形状-外观模糊和退化的场景几何。本文认为精确的几何是有效利用生成模型增强3D场景重建的基本前提。首先,利用平面结构的普遍性来导出精确的度量尺度深度图,从而在观测和未观测区域提供可靠的监督。其次,将这种几何引导融入到生成流程中,以改善可见性掩码估计,引导新视角选择,并增强视频扩散模型修复时的多视角一致性,从而实现精确和一致的场景补全。在Replica、ScanNet++和DeepBlending上的大量实验表明,该方法在几何和外观重建方面始终优于现有基线,尤其是在未观测区域。此外,该方法自然支持单视角输入和无姿态视频,在室内和室外场景中具有很强的泛化能力和实际应用价值。
🔬 方法详解
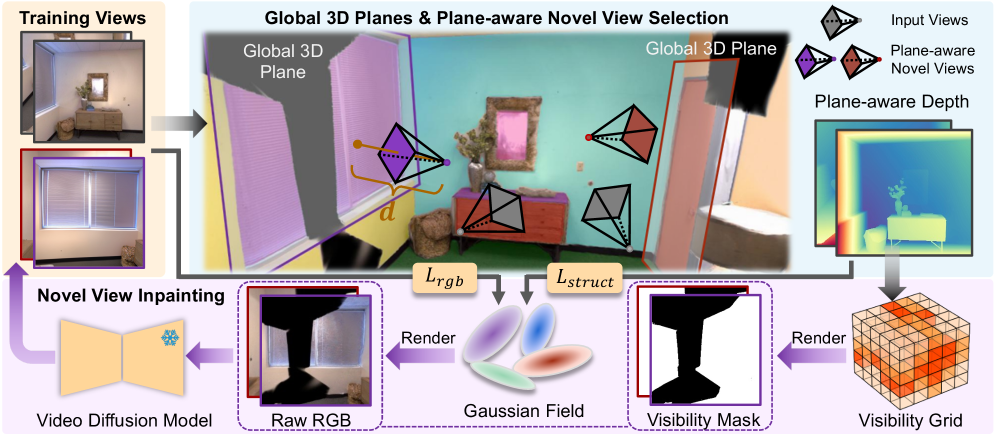
问题定义:现有方法在利用预训练扩散模型进行3D场景重建时,面临两个主要问题:一是缺乏可靠的几何监督,导致重建质量不高,尤其是在未观测区域;二是缺乏有效机制来缓解生成图像中的多视角不一致性,导致形状和外观模糊。这些问题限制了生成先验在3D重建中的应用。
核心思路:本文的核心思路是认为精确的几何信息是有效利用生成模型进行3D场景重建的关键。通过引入几何引导,可以提供更强的约束,从而提高重建质量和一致性。具体来说,利用场景中普遍存在的平面结构来估计精确的深度图,并将其作为几何监督信号,指导生成过程。
技术框架:G4Splat的整体框架包含以下几个主要阶段:1) 利用平面结构推导精确的度量尺度深度图;2) 将几何引导融入生成流程,改进可见性掩码估计;3) 基于几何引导进行新视角选择;4) 使用视频扩散模型进行图像修复,并增强多视角一致性。这些阶段协同工作,最终实现高质量的3D场景重建。
关键创新:G4Splat的关键创新在于将精确的几何信息作为先验知识,并将其有效地融入到基于生成模型的3D重建流程中。与现有方法相比,G4Splat更加注重几何信息的利用,从而能够生成更准确、更一致的重建结果。此外,该方法还提出了一种新的几何引导策略,用于改进可见性掩码估计和新视角选择。
关键设计:G4Splat的关键设计包括:1) 使用平面结构进行深度估计,具体方法未知;2) 设计了几何引导模块,用于改进可见性掩码估计和新视角选择,具体实现方式未知;3) 使用视频扩散模型进行图像修复,并设计了损失函数来增强多视角一致性,具体损失函数形式未知。
🖼️ 关键图片


📊 实验亮点
G4Splat在Replica、ScanNet++和DeepBlending数据集上进行了广泛的实验,结果表明该方法在几何和外观重建方面始终优于现有基线,尤其是在未观测区域。具体性能提升数据未知,但论文强调了在未观测区域的显著改进,证明了几何引导的有效性。
🎯 应用场景
G4Splat具有广泛的应用前景,包括虚拟现实、增强现实、机器人导航、自动驾驶等领域。该方法可以用于生成高质量的3D场景模型,从而为这些应用提供更逼真的环境感知和交互体验。此外,G4Splat还可以用于场景编辑、内容创作等领域,为用户提供更强大的3D建模工具。
📄 摘要(原文)
Despite recent advances in leveraging generative prior from pre-trained diffusion models for 3D scene reconstruction, existing methods still face two critical limitations. First, due to the lack of reliable geometric supervision, they struggle to produce high-quality reconstructions even in observed regions, let alone in unobserved areas. Second, they lack effective mechanisms to mitigate multi-view inconsistencies in the generated images, leading to severe shape-appearance ambiguities and degraded scene geometry. In this paper, we identify accurate geometry as the fundamental prerequisite for effectively exploiting generative models to enhance 3D scene reconstruction. We first propose to leverage the prevalence of planar structures to derive accurate metric-scale depth maps, providing reliable supervision in both observed and unobserved regions. Furthermore, we incorporate this geometry guidance throughout the generative pipeline to improve visibility mask estimation, guide novel view selection, and enhance multi-view consistency when inpainting with video diffusion models, resulting in accurate and consistent scene completion. Extensive experiments on Replica, ScanNet++, and DeepBlending show that our method consistently outperforms existing baselines in both geometry and appearance reconstruction, particularly for unobserved regions. Moreover, our method naturally supports single-view inputs and unposed videos, with strong generalizability in both indoor and outdoor scenarios with practical real-world applicability. The project page is available at https://dali-jack.github.io/g4splat-web/.