Playmate2: Training-Free Multi-Character Audio-Driven Animation via Diffusion Transformer with Reward Feedback
作者: Xingpei Ma, Shenneng Huang, Jiaran Cai, Yuansheng Guan, Shen Zheng, Hanfeng Zhao, Qiang Zhang, Shunsi Zhang
分类: cs.CV
发布日期: 2025-10-14 (更新: 2025-11-18)
备注: AAAI 2026
💡 一句话要点
Playmate2:基于扩散Transformer和奖励反馈的免训练多角色音频驱动动画
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频驱动动画 扩散模型 Transformer LoRA 奖励反馈 多角色动画 免训练 长视频生成
📋 核心要点
- 现有音频驱动视频生成方法在唇音同步精度、长视频时间一致性以及多角色动画方面存在挑战。
- 提出基于扩散Transformer的框架,结合LoRA训练、位置偏移推理和奖励反馈,提升生成质量和效率。
- 引入Mask-CFG免训练方法,无需额外数据或模型修改,即可实现多角色音频驱动动画。
📝 摘要(中文)
本文提出了一种基于扩散Transformer(DiT)的框架,用于生成任意长度的逼真说话视频,并引入了一种免训练方法用于多角色音频驱动动画。首先,采用基于LoRA的训练策略结合位置偏移推理方法,实现高效的长视频生成,同时保留基础模型的能力。其次,结合部分参数更新与奖励反馈,增强唇音同步和自然的身体运动。最后,提出了一种免训练方法,即Mask Classifier-Free Guidance (Mask-CFG),用于多角色动画,无需专门的数据集或模型修改,支持三个或更多角色的音频驱动动画。实验结果表明,该方法优于现有的最先进方法,以简单、高效和经济的方式实现高质量、时间一致和多角色的音频驱动视频生成。
🔬 方法详解
问题定义:现有音频驱动视频生成方法在唇音同步的准确性、长视频生成的时间连贯性以及多角色动画的实现上存在诸多痛点。传统方法难以兼顾高质量、长时间和多角色的需求,需要大量的训练数据和复杂的模型设计。
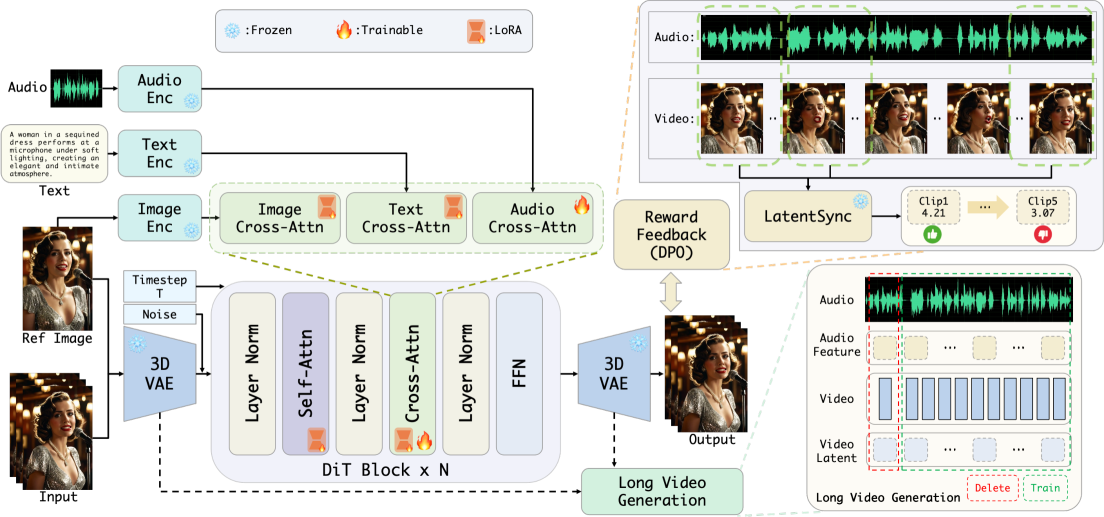
核心思路:论文的核心思路是利用扩散模型强大的生成能力,并结合LoRA高效训练、奖励反馈优化和免训练的多角色控制方法,从而在保证生成质量的同时,降低训练成本和复杂度。通过解耦训练和推理过程,实现更灵活和可控的音频驱动动画生成。
技术框架:整体框架基于扩散Transformer(DiT),主要包含以下几个阶段:1) 使用LoRA对预训练的扩散模型进行微调,以适应音频驱动的任务;2) 采用位置偏移推理方法,增强长视频生成的时间一致性;3) 利用奖励反馈机制,优化唇音同步和身体运动的自然性;4) 引入Mask-CFG,实现多角色动画的免训练控制。
关键创新:论文的关键创新在于:1) 提出了一种基于LoRA和位置偏移推理的高效长视频生成方法;2) 结合奖励反馈,提升了唇音同步和身体运动的自然性;3) 提出了Mask-CFG,实现了多角色动画的免训练控制,无需额外的训练数据或模型修改。
关键设计:在LoRA训练中,只更新部分参数,降低计算成本。位置偏移推理通过调整采样位置,增强时间一致性。奖励反馈基于预训练的唇音同步和动作评估模型,指导生成过程。Mask-CFG通过对不同角色的特征进行掩码,实现独立控制。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Playmate2在唇音同步精度、时间一致性和多角色动画质量方面均优于现有方法。与现有SOTA方法相比,该方法在保证生成质量的同时,显著降低了训练成本和复杂度,实现了高效且经济的音频驱动视频生成。Mask-CFG的免训练特性,极大地简化了多角色动画的制作流程。
🎯 应用场景
该研究成果可广泛应用于虚拟主播、游戏角色动画、电影制作、在线教育等领域。通过音频驱动,可以快速生成逼真且具有表现力的角色动画,降低内容创作成本,提升用户体验。未来,该技术有望进一步扩展到更多模态的驱动,例如文本、手势等,实现更智能和个性化的动画生成。
📄 摘要(原文)
Recent advances in diffusion models have significantly improved audio-driven human video generation, surpassing traditional methods in both quality and controllability. However, existing approaches still face challenges in lip-sync accuracy, temporal coherence for long video generation, and multi-character animation. In this work, we propose a diffusion transformer (DiT)-based framework for generating lifelike talking videos of arbitrary length, and introduce a training-free method for multi-character audio-driven animation. First, we employ a LoRA-based training strategy combined with a position shift inference approach, which enables efficient long video generation while preserving the capabilities of the foundation model. Moreover, we combine partial parameter updates with reward feedback to enhance both lip synchronization and natural body motion. Finally, we propose a training-free approach, Mask Classifier-Free Guidance (Mask-CFG), for multi-character animation, which requires no specialized datasets or model modifications and supports audio-driven animation for three or more characters. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches, achieving high-quality, temporally coherent, and multi-character audio-driven video generation in a simple, efficient, and cost-effective manner.