Beyond 'Templates': Category-Agnostic Object Pose, Size, and Shape Estimation from a Single View
作者: Jinyu Zhang, Haitao Lin, Jiashu Hou, Xiangyang Xue, Yanwei Fu
分类: cs.CV
发布日期: 2025-10-13
💡 一句话要点
提出一种类别无关的单视图物体位姿、尺寸和形状估计框架。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 6D位姿估计 形状估计 类别无关 零样本学习 Transformer RGB-D 机器人抓取
📋 核心要点
- 现有方法依赖于物体特定的先验知识或在类别泛化方面存在局限性,难以同时估计位姿、尺寸和形状。
- 提出一种类别无关的框架,利用Transformer融合2D视觉特征和3D点云,并行解码位姿-尺寸和形状。
- 在多个数据集上验证了框架的有效性,尤其在未见物体上展现出强大的零样本泛化能力。
📝 摘要(中文)
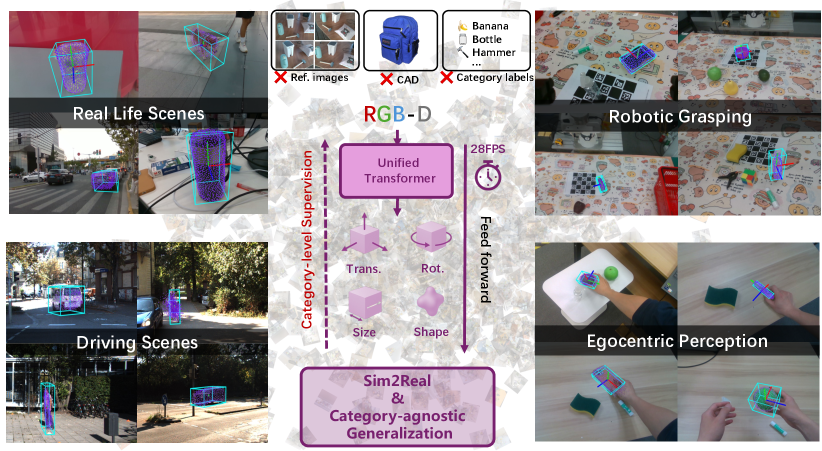
本文提出了一种统一的、类别无关的框架,用于从单个RGB-D图像中同时预测物体的6D位姿、尺寸和稠密形状,无需模板、CAD模型或测试时的类别标签。该模型融合了视觉基础模型的稠密2D特征和部分3D点云,使用Transformer编码器(通过混合专家模型增强),并采用并行解码器进行位姿-尺寸估计和形状重建,实现了28 FPS的实时推理速度。该框架仅在SOPE数据集中149个类别的合成数据上进行训练,并在SOPE、ROPE、ObjaversePose和HANDAL四个不同的基准上进行了评估,涵盖了300多个类别。在已见类别上实现了最先进的精度,同时对未见真实世界物体表现出非常强的零样本泛化能力,为机器人和具身智能中的开放集6D理解建立了一个新的标准。
🔬 方法详解
问题定义:现有方法在估计物体的6D位姿、尺寸和形状时,通常依赖于物体特定的CAD模型或模板,这限制了其在开放环境中的应用。此外,一些方法由于位姿和形状的纠缠以及多阶段流水线的设计,导致类别泛化能力不足。因此,需要一种能够处理未知物体的、类别无关的位姿、尺寸和形状估计方法。
核心思路:本文的核心思路是利用视觉基础模型提取图像的2D特征,并将其与3D点云信息融合,从而实现对物体位姿、尺寸和形状的解耦估计。通过Transformer架构学习2D和3D特征之间的关系,并使用并行解码器分别预测位姿-尺寸和形状,避免了信息纠缠。
技术框架:该框架主要包含三个模块:特征提取模块、Transformer编码器模块和并行解码器模块。首先,使用视觉基础模型提取RGB-D图像的2D特征,并结合3D点云信息。然后,Transformer编码器(通过混合专家模型增强)融合2D和3D特征,学习它们之间的关联。最后,使用两个并行解码器,一个用于预测6D位姿和尺寸,另一个用于重建物体的稠密形状。
关键创新:该方法最重要的创新点在于其类别无关性。通过融合视觉基础模型的2D特征和3D点云信息,并利用Transformer学习特征之间的关系,该方法能够在没有物体特定先验知识的情况下,对未知物体的位姿、尺寸和形状进行估计。与现有方法相比,该方法具有更强的泛化能力和鲁棒性。
关键设计:Transformer编码器中使用了混合专家模型(Mixture-of-Experts),以增强模型的表达能力和泛化能力。并行解码器的设计避免了位姿-尺寸和形状之间的信息纠缠,提高了估计的准确性。损失函数的设计也至关重要,需要平衡位姿、尺寸和形状估计的精度。
🖼️ 关键图片

📊 实验亮点
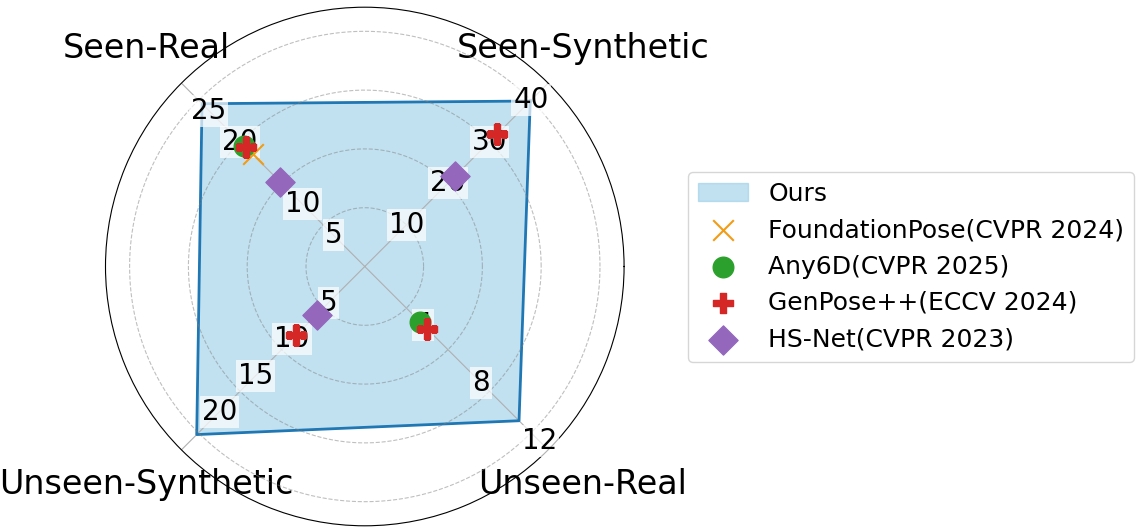
该框架在SOPE、ROPE、ObjaversePose和HANDAL四个数据集上进行了评估,并在已见类别上取得了state-of-the-art的精度。更重要的是,该框架在未见类别上表现出了强大的零样本泛化能力,证明了其在开放环境中的有效性。该方法能够以28 FPS的速率进行实时推理,满足了实际应用的需求。
🎯 应用场景
该研究成果可广泛应用于机器人抓取与操作、增强现实、自动驾驶等领域。例如,机器人可以利用该技术识别并抓取未知物体,从而实现更智能化的操作。在AR应用中,可以准确地估计虚拟物体与真实场景的相对位置和大小,提升用户体验。自动驾驶系统则可以利用该技术识别周围的车辆、行人等物体,并估计其位姿,从而做出更安全的决策。
📄 摘要(原文)
Estimating an object's 6D pose, size, and shape from visual input is a fundamental problem in computer vision, with critical applications in robotic grasping and manipulation. Existing methods either rely on object-specific priors such as CAD models or templates, or suffer from limited generalization across categories due to pose-shape entanglement and multi-stage pipelines. In this work, we propose a unified, category-agnostic framework that simultaneously predicts 6D pose, size, and dense shape from a single RGB-D image, without requiring templates, CAD models, or category labels at test time. Our model fuses dense 2D features from vision foundation models with partial 3D point clouds using a Transformer encoder enhanced by a Mixture-of-Experts, and employs parallel decoders for pose-size estimation and shape reconstruction, achieving real-time inference at 28 FPS. Trained solely on synthetic data from 149 categories in the SOPE dataset, our framework is evaluated on four diverse benchmarks SOPE, ROPE, ObjaversePose, and HANDAL, spanning over 300 categories. It achieves state-of-the-art accuracy on seen categories while demonstrating remarkably strong zero-shot generalization to unseen real-world objects, establishing a new standard for open-set 6D understanding in robotics and embodied AI.