ExpVid: A Benchmark for Experiment Video Understanding & Reasoning
作者: Yicheng Xu, Yue Wu, Jiashuo Yu, Ziang Yan, Tianxiang Jiang, Yinan He, Qingsong Zhao, Kai Chen, Yu Qiao, Limin Wang, Manabu Okumura, Yi Wang
分类: cs.CV
发布日期: 2025-10-13
备注: Data & Code: https://github.com/OpenGVLab/ExpVid
💡 一句话要点
ExpVid:用于评估多模态大语言模型在科学实验视频理解与推理能力的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实验视频理解 多模态大语言模型 科学推理 基准测试 视觉中心学习
📋 核心要点
- 现有基准测试忽略了真实实验室环境中细粒度和长时程的特性,无法有效评估MLLMs在科学实验中的能力。
- ExpVid基准通过构建三级任务层次结构,从细粒度感知、程序理解到科学推理,全面评估MLLMs的实验理解能力。
- 实验结果表明,现有MLLMs在细粒度识别、状态跟踪和科学推理方面存在不足,专有模型在高阶推理方面优于开源模型。
📝 摘要(中文)
多模态大语言模型(MLLMs)有望通过解释复杂的实验程序来加速科学发现。然而,由于现有基准忽略了真实实验室工作,特别是湿实验室环境中细粒度和长时程的特性,因此对它们的能力了解不足。为了弥补这一差距,我们推出了ExpVid,这是第一个旨在系统评估MLLMs在科学实验视频上的基准。ExpVid从同行评审的视频出版物中提取,具有一个新的三级任务层次结构,反映了科学过程:(1)对工具、材料和动作的细粒度感知;(2)对步骤顺序和完整性的程序理解;(3)将完整实验与其已发表结论联系起来的科学推理。我们的视觉中心注释流程,结合了自动生成和多学科专家验证,确保任务需要视觉基础。我们在ExpVid上评估了19个领先的MLLMs,发现它们擅长粗粒度识别,但在消除细微细节的歧义、跟踪随时间的状态变化以及将实验程序与科学结果联系起来方面存在困难。我们的结果表明,专有模型和开源模型之间存在显著的性能差距,尤其是在高阶推理方面。ExpVid不仅提供了一个诊断工具,而且还为开发能够成为科学实验中值得信赖的合作伙伴的MLLMs规划了路线图。
🔬 方法详解
问题定义:论文旨在解决现有MLLMs在理解和推理科学实验视频方面的不足。现有基准测试无法充分捕捉真实实验的复杂性,特别是湿实验室环境中的细粒度操作和长时间序列依赖关系。这导致对MLLMs在科学发现中的潜力评估不准确。
核心思路:论文的核心思路是构建一个更具挑战性和代表性的基准数据集ExpVid,该数据集包含从同行评审的科学出版物中提取的实验视频,并设计了三级任务层次结构,以系统地评估MLLMs在不同层次上的理解和推理能力。这种分层评估方法能够更全面地揭示MLLMs的优势和局限性。
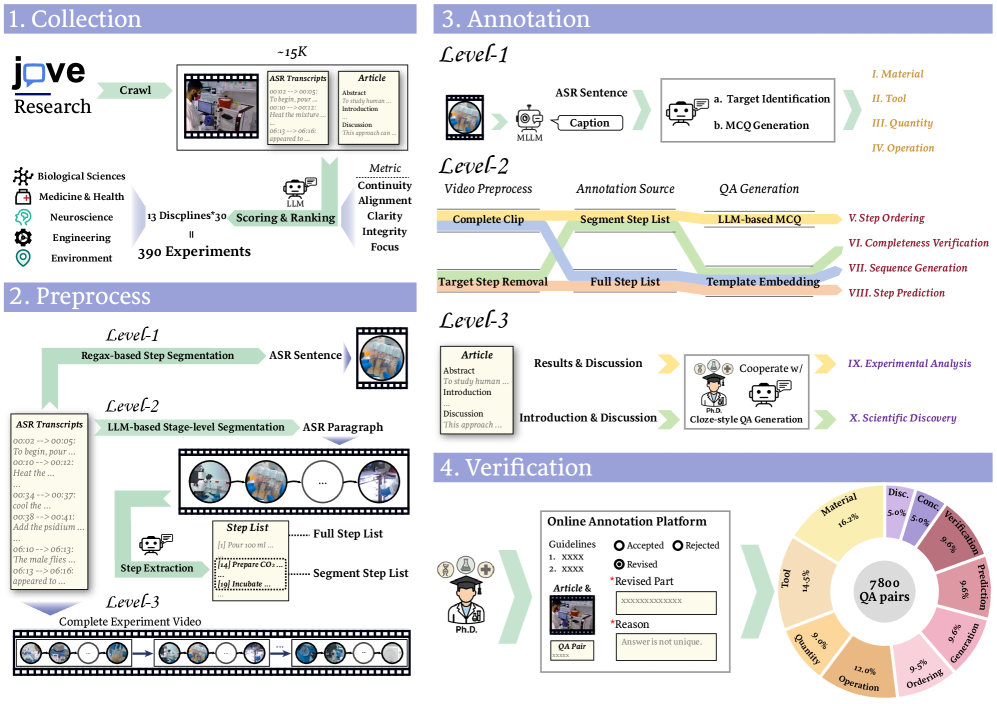
技术框架:ExpVid基准的构建流程包括以下几个主要阶段:1) 从科学出版物中收集实验视频;2) 设计三级任务层次结构,包括细粒度感知、程序理解和科学推理;3) 开发视觉中心注释流程,结合自动生成和专家验证,确保任务的视觉基础;4) 使用ExpVid评估现有的MLLMs,并分析其性能。
关键创新:ExpVid的关键创新在于其数据集的真实性和任务设计的全面性。与现有基准相比,ExpVid更贴近真实的科学实验场景,并且通过分层任务设计,能够更深入地评估MLLMs在不同层次上的理解和推理能力。此外,视觉中心注释流程确保了任务的视觉基础,避免了模型仅仅依赖文本信息进行推理。
关键设计:ExpVid的三级任务层次结构是其关键设计之一。细粒度感知任务要求模型识别实验中的工具、材料和动作;程序理解任务要求模型理解实验步骤的顺序和完整性;科学推理任务要求模型将实验程序与科学结论联系起来。这种分层设计能够更全面地评估MLLMs的实验理解能力。此外,论文还采用了多学科专家验证的注释流程,以确保注释的质量和准确性。
🖼️ 关键图片

📊 实验亮点
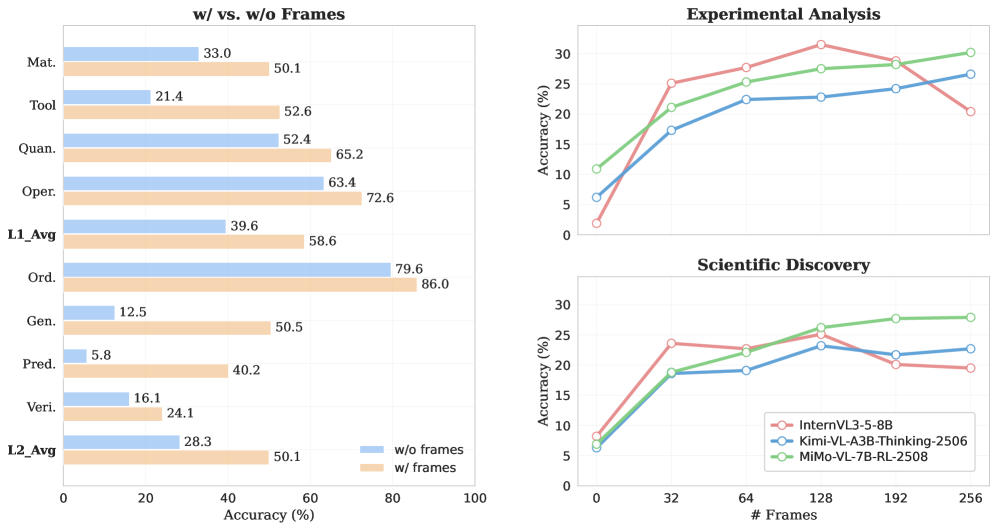
ExpVid基准测试评估了19个领先的MLLMs,结果表明,虽然它们在粗粒度识别方面表现出色,但在细粒度细节区分、时间状态跟踪以及实验程序与科学结果的关联方面存在困难。专有模型在高阶推理方面明显优于开源模型,揭示了现有模型在科学推理能力上的差距。
🎯 应用场景
ExpVid的研究成果可应用于开发能够辅助科学家进行实验设计、数据分析和结果解释的智能系统。这些系统可以帮助科学家更高效地进行科学研究,加速科学发现的进程。此外,该基准还可以促进多模态大语言模型在科学领域的应用,例如自动化实验流程、智能实验室助手等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) hold promise for accelerating scientific discovery by interpreting complex experimental procedures. However, their true capabilities are poorly understood, as existing benchmarks neglect the fine-grained and long-horizon nature of authentic laboratory work, especially in wet-lab settings. To bridge this gap, we introduce ExpVid, the first benchmark designed to systematically evaluate MLLMs on scientific experiment videos. Curated from peer-reviewed video publications, ExpVid features a new three-level task hierarchy that mirrors the scientific process: (1) Fine-grained Perception of tools, materials, and actions; (2) Procedural Understanding of step order and completeness; and (3) Scientific Reasoning that connects the full experiment to its published conclusions. Our vision-centric annotation pipeline, combining automated generation with multi-disciplinary expert validation, ensures that tasks require visual grounding. We evaluate 19 leading MLLMs on ExpVid and find that while they excel at coarse-grained recognition, they struggle with disambiguating fine details, tracking state changes over time, and linking experimental procedures to scientific outcomes. Our results reveal a notable performance gap between proprietary and open-source models, particularly in high-order reasoning. ExpVid not only provides a diagnostic tool but also charts a roadmap for developing MLLMs capable of becoming trustworthy partners in scientific experimentation.