MS-Mix: Unveiling the Power of Mixup for Multimodal Sentiment Analysis
作者: Hongyu Zhu, Lin Chen, Mounim A. El-Yacoubi, Mingsheng Shang
分类: cs.CV, cs.LG
发布日期: 2025-10-13
备注: Under Review
🔗 代码/项目: GITHUB
💡 一句话要点
提出MS-Mix,通过情感感知的Mixup增强方法提升多模态情感分析性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 数据增强 Mixup 情感感知 跨模态对齐
📋 核心要点
- 多模态情感分析面临标注数据稀缺的挑战,直接应用Mixup会引入标签模糊和语义不一致问题。
- MS-Mix提出情感感知的Mixup增强框架,通过情感感知样本选择和情感强度引导的混合比例计算来优化样本混合。
- 实验结果表明,MS-Mix在多个基准数据集上显著优于现有方法,为多模态情感增强设立了新标准。
📝 摘要(中文)
多模态情感分析(MSA)旨在通过整合文本、视频和音频等异构数据源的信息来识别和解释人类情感。尽管深度学习模型在网络架构设计方面取得了进展,但它们仍然受到多模态标注数据稀缺的严重限制。虽然基于Mixup的增强方法提高了单模态任务的泛化能力,但直接应用于MSA会带来关键挑战:由于缺乏情感感知的混合机制,随机混合通常会放大标签模糊性和语义不一致性。为了克服这些问题,我们提出了一种自适应的、情感敏感的增强框架MS-Mix,该框架自动优化多模态环境中的样本混合。MS-Mix的关键组件包括:(1)一种情感感知样本选择(SASS)策略,可有效防止混合具有矛盾情感的样本引起的语义混淆。(2)一个情感强度引导(SIG)模块,使用多头自注意力来动态计算特定模态的混合比例,该比例基于它们各自的情感强度。(3)一种情感对齐损失(SAL),可对齐跨模态的预测分布,并将基于Kullback-Leibler的损失作为额外的正则化项,以联合训练情感强度预测器和骨干网络。在三个基准数据集上进行的广泛实验以及六个最先进的骨干网络证实,MS-Mix始终优于现有方法,为鲁棒的多模态情感增强建立了新标准。源代码可在https://github.com/HongyuZhu-s/MS-Mix获得。
🔬 方法详解
问题定义:多模态情感分析旨在融合来自不同模态(如文本、音频、视频)的信息来准确识别情感。然而,现有的深度学习模型在多模态情感分析中面临数据稀缺的问题,直接应用Mixup数据增强方法时,由于缺乏对情感信息的考虑,容易混合具有矛盾情感的样本,导致语义混淆和标签模糊,从而损害模型性能。
核心思路:MS-Mix的核心思路是提出一种情感感知的Mixup增强方法,通过在样本混合过程中考虑情感信息,避免混合具有矛盾情感的样本,并根据各模态的情感强度动态调整混合比例。这样可以有效地缓解数据稀缺问题,同时保证混合样本的语义一致性和情感标签的准确性。
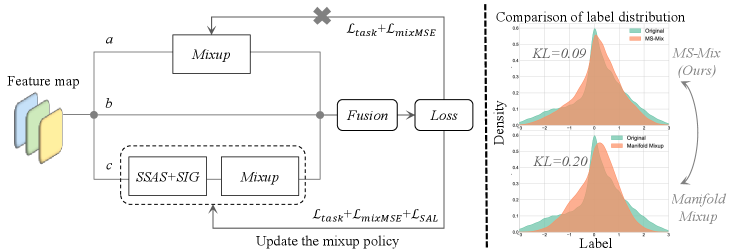
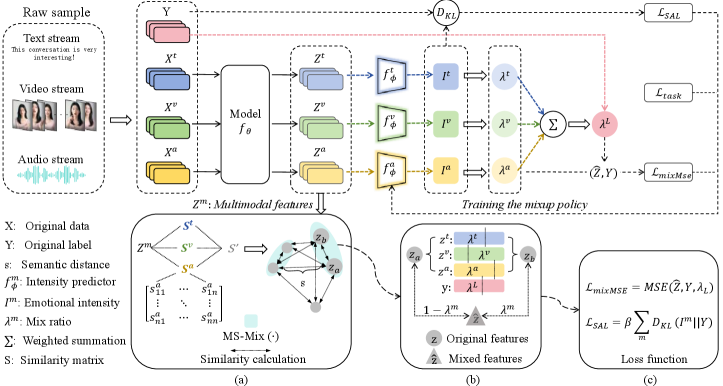
技术框架:MS-Mix框架主要包含三个关键模块:情感感知样本选择(SASS)、情感强度引导(SIG)和情感对齐损失(SAL)。SASS模块负责选择具有相似情感的样本进行混合,避免语义冲突。SIG模块利用多头自注意力机制,根据各模态的情感强度动态计算混合比例。SAL模块通过对齐跨模态的预测分布,并引入Kullback-Leibler散度损失,联合训练情感强度预测器和骨干网络。
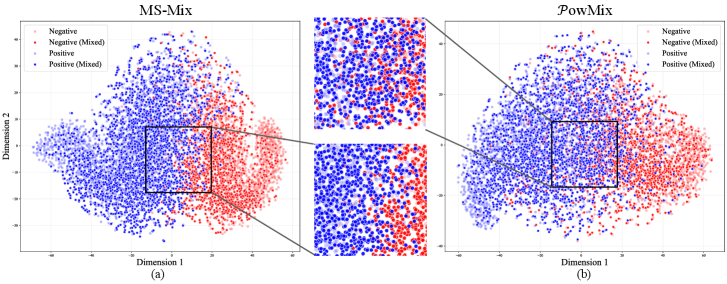
关键创新:MS-Mix的关键创新在于其情感感知的Mixup增强机制。与传统的Mixup方法不同,MS-Mix不是随机混合样本,而是根据样本的情感信息进行选择和混合。这种情感感知的混合方式可以有效地避免语义混淆和标签模糊,从而提高模型的泛化能力。此外,SIG模块动态计算混合比例,使得模型能够更好地利用各模态的情感信息。
关键设计:SASS模块使用情感分类器预测样本的情感标签,并选择具有相同情感标签的样本进行混合。SIG模块使用多头自注意力机制计算各模态的情感强度,并将其作为混合比例。SAL模块使用Kullback-Leibler散度损失对齐跨模态的预测分布,并联合训练情感强度预测器和骨干网络。具体来说,损失函数包含情感分类损失、情感强度预测损失和跨模态对齐损失三部分。
🖼️ 关键图片
📊 实验亮点
MS-Mix在CMU-MOSI、CMU-MOSEI和SIMS数据集上进行了广泛的实验,并与六个最先进的基线模型进行了比较。实验结果表明,MS-Mix在所有数据集上均取得了显著的性能提升,例如在CMU-MOSI数据集上,MS-Mix的准确率提高了超过3%。这些结果证明了MS-Mix在多模态情感分析任务中的有效性和优越性。
🎯 应用场景
MS-Mix在多模态情感分析领域具有广泛的应用前景,例如在线评论情感分析、客户服务对话情感识别、社交媒体舆情监控等。该研究可以提升情感识别的准确性和鲁棒性,帮助企业更好地理解用户情感,优化产品和服务,并及时发现和应对潜在的舆情风险。未来,该方法可以扩展到其他多模态学习任务中,例如多模态机器翻译、多模态对话系统等。
📄 摘要(原文)
Multimodal Sentiment Analysis (MSA) aims to identify and interpret human emotions by integrating information from heterogeneous data sources such as text, video, and audio. While deep learning models have advanced in network architecture design, they remain heavily limited by scarce multimodal annotated data. Although Mixup-based augmentation improves generalization in unimodal tasks, its direct application to MSA introduces critical challenges: random mixing often amplifies label ambiguity and semantic inconsistency due to the lack of emotion-aware mixing mechanisms. To overcome these issues, we propose MS-Mix, an adaptive, emotion-sensitive augmentation framework that automatically optimizes sample mixing in multimodal settings. The key components of MS-Mix include: (1) a Sentiment-Aware Sample Selection (SASS) strategy that effectively prevents semantic confusion caused by mixing samples with contradictory emotions. (2) a Sentiment Intensity Guided (SIG) module using multi-head self-attention to compute modality-specific mixing ratios dynamically based on their respective emotional intensities. (3) a Sentiment Alignment Loss (SAL) that aligns the prediction distributions across modalities, and incorporates the Kullback-Leibler-based loss as an additional regularization term to train the emotion intensity predictor and the backbone network jointly. Extensive experiments on three benchmark datasets with six state-of-the-art backbones confirm that MS-Mix consistently outperforms existing methods, establishing a new standard for robust multimodal sentiment augmentation. The source code is available at: https://github.com/HongyuZhu-s/MS-Mix.