How many samples to label for an application given a foundation model? Chest X-ray classification study
作者: Nikolay Nechaev, Evgeniia Przhezdzetskaia, Viktor Gombolevskiy, Dmitry Umerenkov, Dmitry Dylov
分类: cs.CV
发布日期: 2025-10-13 (更新: 2025-10-22)
备注: 8 pages, 5 figures
💡 一句话要点
研究胸部X光片分类任务中,如何利用预训练模型减少标注样本需求
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 胸部X光片分类 预训练模型 迁移学习 标注样本量 幂律拟合
📋 核心要点
- 胸部X光片分类依赖大量标注数据,成本高昂,现有方法难以平衡性能与标注成本。
- 利用预训练模型,通过幂律拟合预测达到目标性能所需的最小标注样本量。
- 实验表明,XrayCLIP和XraySigLIP在少量标注下优于ResNet-50,且少量样本即可预测性能上限。
📝 摘要(中文)
胸部X光片分类至关重要,但通常需要大量标注数据以保证诊断准确性,这导致资源消耗巨大。预训练模型可以缓解对大量标注数据的依赖,但所需标注样本数量仍然不明确。本文系统性地评估了使用幂律拟合来预测达到特定ROC-AUC阈值所需的训练数据量。通过测试多种病理和预训练模型,发现XrayCLIP和XraySigLIP仅需少量标注样本即可实现优于ResNet-50基线的性能。更重要的是,仅使用50个标注样本的学习曲线斜率即可准确预测最终性能平台期。研究结果使从业者能够通过仅标注目标性能所需的必要样本来最大限度地降低标注成本。
🔬 方法详解
问题定义:论文旨在解决胸部X光片分类任务中,如何确定使用预训练模型进行微调时所需的最小标注样本数量的问题。现有方法通常需要大量标注数据才能达到理想的性能,这使得标注成本非常高昂。因此,如何在保证模型性能的前提下,尽可能减少标注工作量是一个重要的研究问题。
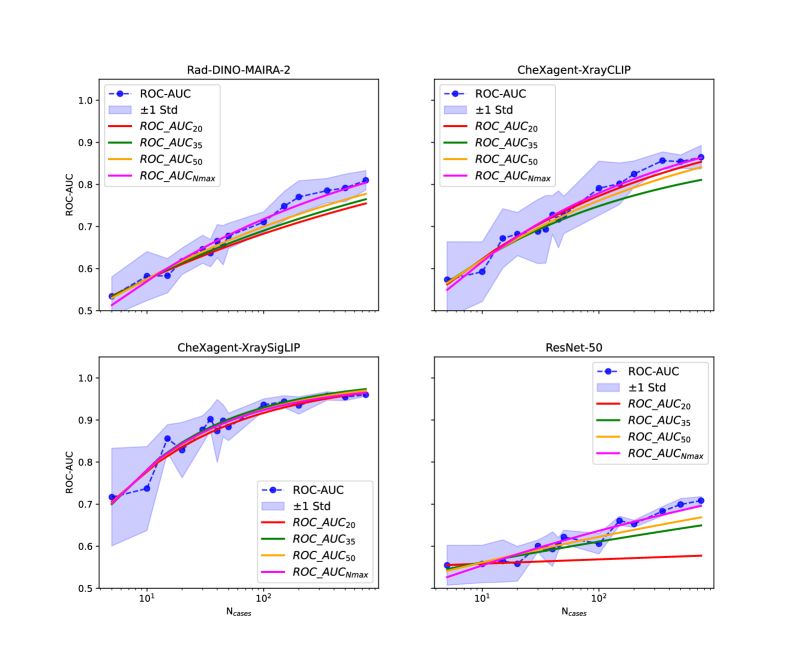
核心思路:论文的核心思路是利用学习曲线的幂律特性,通过少量标注样本(例如50个)构建学习曲线,并拟合幂律函数,从而预测模型在更多数据下的性能表现。这样,就可以在实际标注大量数据之前,预估出达到目标性能所需的样本数量,从而避免不必要的标注工作。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择合适的预训练模型(如XrayCLIP、XraySigLIP和ResNet-50);2) 使用少量标注数据(如50个)对预训练模型进行微调;3) 构建学习曲线,即模型性能(如ROC-AUC)随标注样本数量变化的曲线;4) 使用幂律函数对学习曲线进行拟合;5) 基于拟合结果,预测达到目标性能所需的标注样本数量。
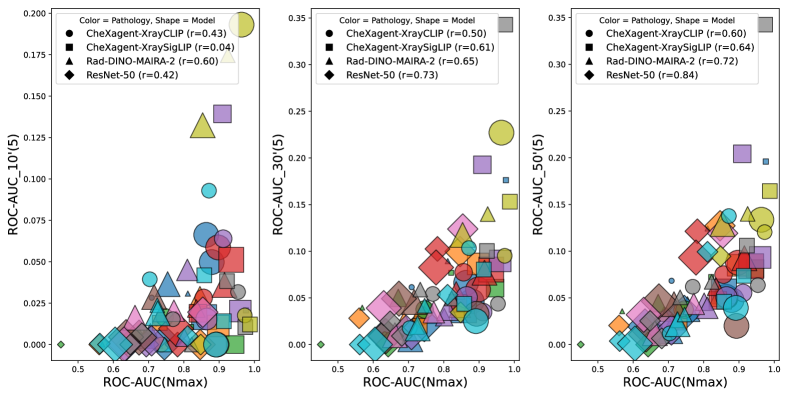
关键创新:论文的关键创新在于提出了一种基于幂律拟合的学习曲线预测方法,可以有效地预测预训练模型在胸部X光片分类任务中达到目标性能所需的最小标注样本数量。与现有方法相比,该方法只需要少量标注样本即可进行预测,从而大大降低了标注成本。
关键设计:论文的关键设计包括:1) 选择了XrayCLIP和XraySigLIP等专门针对X光片设计的预训练模型,这些模型在医学图像领域具有更好的泛化能力;2) 使用ROC-AUC作为模型性能的评价指标,ROC-AUC能够综合评价模型在不同阈值下的分类性能;3) 使用幂律函数(Power Law)对学习曲线进行拟合,幂律函数能够较好地描述模型性能随数据量增加的变化趋势。
🖼️ 关键图片
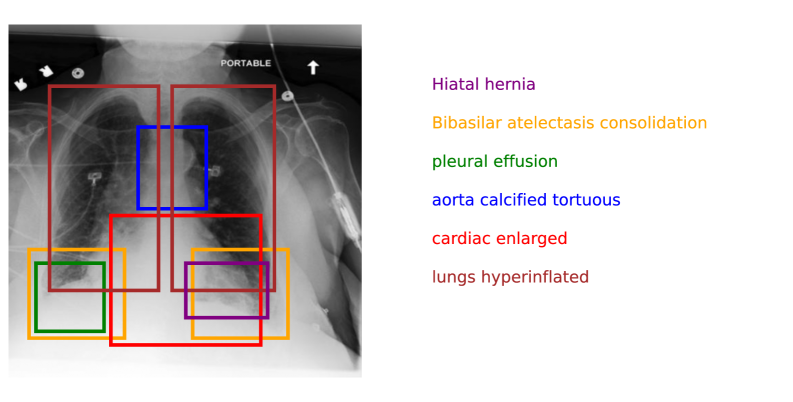
📊 实验亮点
实验结果表明,XrayCLIP和XraySigLIP等预训练模型在少量标注样本下(如50个)即可达到优于ResNet-50基线的性能。更重要的是,仅使用50个标注样本的学习曲线斜率即可准确预测最终性能平台期。例如,通过幂律拟合,可以预测达到特定ROC-AUC阈值所需的标注样本数量,从而指导实际的标注工作。
🎯 应用场景
该研究成果可应用于医疗影像诊断领域,帮助医生和研究人员在有限的标注资源下,快速有效地训练胸部X光片分类模型。通过预测所需的最小标注样本量,可以显著降低标注成本,加速模型开发和部署,从而提高诊断效率和准确性,最终改善患者的医疗服务质量。未来,该方法还可以推广到其他医学影像分类任务中。
📄 摘要(原文)
Chest X-ray classification is vital yet resource-intensive, typically demanding extensive annotated data for accurate diagnosis. Foundation models mitigate this reliance, but how many labeled samples are required remains unclear. We systematically evaluate the use of power-law fits to predict the training size necessary for specific ROC-AUC thresholds. Testing multiple pathologies and foundation models, we find XrayCLIP and XraySigLIP achieve strong performance with significantly fewer labeled examples than a ResNet-50 baseline. Importantly, learning curve slopes from just 50 labeled cases accurately forecast final performance plateaus. Our results enable practitioners to minimize annotation costs by labeling only the essential samples for targeted performance.