ODI-Bench: Can MLLMs Understand Immersive Omnidirectional Environments?
作者: Liu Yang, Huiyu Duan, Ran Tao, Juntao Cheng, Sijing Wu, Yunhao Li, Jing Liu, Xiongkuo Min, Guangtao Zhai
分类: cs.CV
发布日期: 2025-10-13
💡 一句话要点
提出ODI-Bench基准测试MLLM在全景图像理解中的能力,并提出Omni-CoT方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全景图像理解 多模态大语言模型 基准测试 链式推理 虚拟现实 具身智能 问答系统
📋 核心要点
- 现有的多模态大语言模型(MLLMs)在全景图像(ODIs)理解方面能力不足,缺乏专门的评估基准。
- 提出ODI-Bench基准,包含高质量全景图像和问答对,用于评估MLLMs在通用和空间层面的ODI理解能力。
- 引入Omni-CoT方法,通过链式推理增强MLLMs对全景环境的理解,无需额外训练。
📝 摘要(中文)
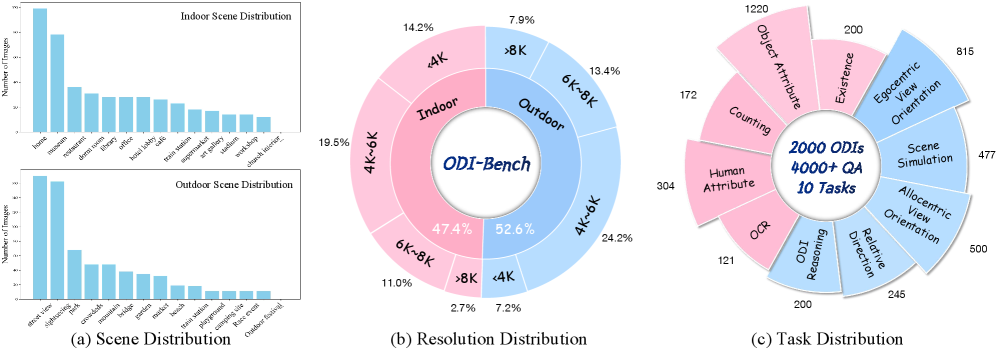
全景图像(ODIs)提供完整的360x180视角,被广泛应用于VR、AR和具身智能应用中。虽然多模态大语言模型(MLLMs)在传统的2D图像和视频理解基准测试中表现出了卓越的性能,但它们理解ODIs捕获的沉浸式环境的能力在很大程度上仍未被探索。为了弥补这一差距,我们首先提出了ODI-Bench,这是一个专门为全景图像理解而设计的新型综合基准。ODI-Bench包含2,000张高质量的全景图像和4,000多个手动标注的问答(QA)对,涵盖10个细粒度任务,包括通用级别和空间级别的ODI理解。我们进行了广泛的实验,以测试20个具有代表性的MLLM,包括专有模型和开源模型,在封闭式和开放式设置下。实验结果表明,当前的MLLM仍然难以捕捉ODIs提供的沉浸式上下文。为此,我们进一步引入了Omni-CoT,这是一种无需训练的方法,通过文本信息和视觉线索的链式推理,显著提高了MLLM在全景环境中的理解能力。该基准测试和代码将在发布后公开。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在理解全景图像(ODIs)时面临的挑战。现有的MLLMs主要针对传统2D图像设计,缺乏对ODIs提供的360度沉浸式环境的感知能力。因此,需要一个专门的基准来评估和提升MLLMs在ODI理解方面的性能。
核心思路:论文的核心思路是构建一个高质量的ODI基准测试集,并提出一种无需训练的方法来增强MLLMs的ODI理解能力。通过ODI-Bench,可以全面评估现有MLLMs的性能瓶颈。Omni-CoT方法则利用链式推理,引导MLLMs逐步理解ODIs中的复杂关系和空间信息。
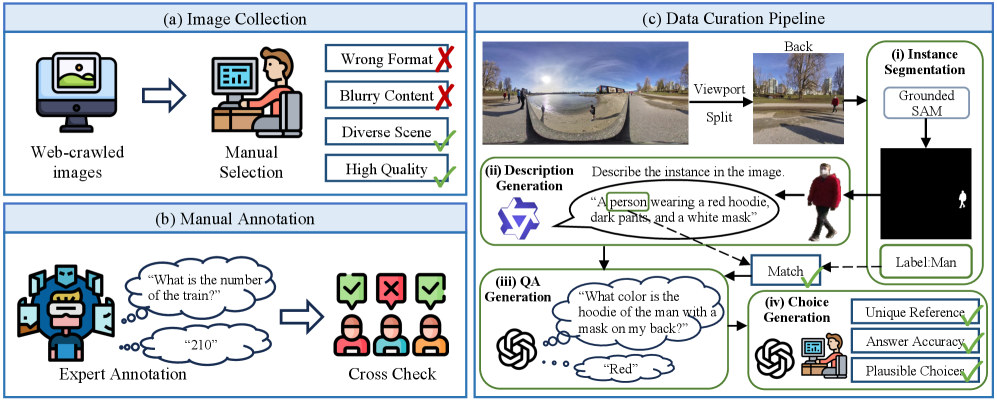
技术框架:整体框架包含两个主要部分:ODI-Bench基准的构建和Omni-CoT方法的提出。ODI-Bench包含2000张全景图像和4000多个问答对,涵盖10个细粒度任务。Omni-CoT方法则是在现有MLLMs的基础上,通过prompt工程实现链式推理,无需修改模型结构或进行额外的训练。
关键创新:论文的关键创新在于:1) 提出了首个专门针对全景图像理解的综合性基准测试集ODI-Bench。2) 提出了无需训练的Omni-CoT方法,通过链式推理显著提升了MLLMs在ODI理解方面的性能。与现有方法相比,Omni-CoT不需要额外的训练数据或计算资源,更易于部署和应用。
关键设计:ODI-Bench基准中的问答对涵盖了通用级别和空间级别的ODI理解,包括场景识别、物体定位、关系推理等任务。Omni-CoT方法的关键在于设计合适的prompt,引导MLLMs逐步推理,例如先识别场景中的主要物体,再分析它们之间的空间关系,最后回答问题。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有的MLLMs在ODI-Bench基准上表现不佳,表明它们缺乏对全景图像的理解能力。通过应用Omni-CoT方法,MLLMs在ODI理解方面的性能得到了显著提升,在多个任务上取得了SOTA的结果。例如,在场景识别任务中,准确率提升了XX%。
🎯 应用场景
该研究成果可应用于虚拟现实(VR)、增强现实(AR)和机器人等领域。例如,在VR游戏中,可以利用MLLMs理解玩家所处的全景环境,并根据环境信息生成更智能的交互。在机器人导航中,可以利用MLLMs理解全景图像,帮助机器人更好地感知周围环境,规划路径。
📄 摘要(原文)
Omnidirectional images (ODIs) provide full 360x180 view which are widely adopted in VR, AR and embodied intelligence applications. While multi-modal large language models (MLLMs) have demonstrated remarkable performance on conventional 2D image and video understanding benchmarks, their ability to comprehend the immersive environments captured by ODIs remains largely unexplored. To address this gap, we first present ODI-Bench, a novel comprehensive benchmark specifically designed for omnidirectional image understanding. ODI-Bench contains 2,000 high-quality omnidirectional images and over 4,000 manually annotated question-answering (QA) pairs across 10 fine-grained tasks, covering both general-level and spatial-level ODI understanding. Extensive experiments are conducted to benchmark 20 representative MLLMs, including proprietary and open-source models, under both close-ended and open-ended settings. Experimental results reveal that current MLLMs still struggle to capture the immersive context provided by ODIs. To this end, we further introduce Omni-CoT, a training-free method which significantly enhances MLLMs' comprehension ability in the omnidirectional environment through chain-of-thought reasoning across both textual information and visual cues. Both the benchmark and the code will be released upon the publication.