Massive Activations are the Key to Local Detail Synthesis in Diffusion Transformers
作者: Chaofan Gan, Zicheng Zhao, Yuanpeng Tu, Xi Chen, Ziran Qin, Tieyuan Chen, Mehrtash Harandi, Weiyao Lin
分类: cs.CV
发布日期: 2025-10-13 (更新: 2025-10-14)
💡 一句话要点
提出Detail Guidance,通过调控Diffusion Transformer中的大规模激活提升局部细节生成质量。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 Diffusion Transformer 大规模激活 局部细节合成 自指导 图像生成 细节增强
📋 核心要点
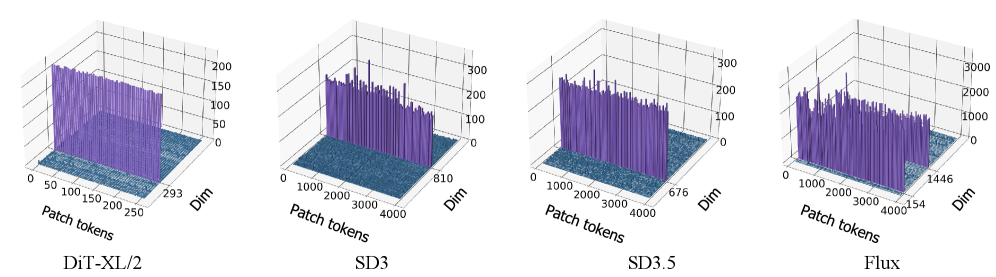
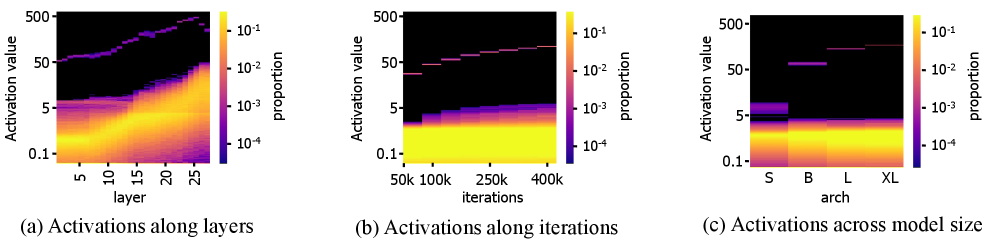
- 扩散模型在图像生成上表现出色,但Diffusion Transformer中大规模激活的作用尚不明确。
- 通过分析大规模激活与时间步嵌入的关系,发现其对局部细节生成至关重要,而对全局语义影响较小。
- 提出Detail Guidance方法,通过扰动大规模激活引导模型生成更精细的局部细节,且无需额外训练。
📝 摘要(中文)
扩散Transformer(DiT)最近成为视觉生成领域强大的骨干网络。近期的研究表明,DiT的内部特征图中存在“大规模激活”(MAs),但其功能仍然知之甚少。本文系统地研究了这些激活,以阐明它们在视觉生成中的作用。我们发现这些大规模激活出现在所有空间token中,并且它们的分布受到输入时间步嵌入的调节。重要的是,我们的研究进一步表明,这些大规模激活在局部细节合成中起着关键作用,而对输出的整体语义内容的影响最小。基于这些见解,我们提出了一种由MAs驱动的、无需训练的自指导策略,称为Detail Guidance(DG),以显式地增强DiT的局部细节保真度。具体来说,DG通过扰乱MAs构建了一个降级的“细节缺陷”模型,并利用它来指导原始网络实现更高质量的细节合成。我们的DG可以与Classifier-Free Guidance(CFG)无缝集成,从而进一步改进精细细节。大量的实验表明,我们的DG能够持续提高各种预训练DiT(例如,SD3、SD3.5和Flux)的精细细节质量。
🔬 方法详解
问题定义:现有的扩散模型,特别是Diffusion Transformer,在生成图像时,虽然能够捕捉全局语义信息,但在局部细节的合成方面仍然存在不足。论文旨在解决如何提升Diffusion Transformer生成图像的局部细节保真度的问题。现有方法缺乏对模型内部激活的深入理解,未能充分利用模型自身的能力来提升细节生成质量。
核心思路:论文的核心思路是利用Diffusion Transformer中存在的“大规模激活”(Massive Activations, MAs)。通过研究发现,这些MAs在局部细节合成中起着关键作用。论文提出通过有控制地扰动这些MAs,构建一个“细节缺陷”模型,然后利用该模型来指导原始模型,从而提升细节生成能力。这种自指导的方式无需额外的训练,可以有效利用模型自身的知识。
技术框架:Detail Guidance (DG) 的整体框架包括以下几个步骤: 1. 分析MAs: 首先,分析预训练DiT模型中的大规模激活,了解其分布和特性。 2. 构建细节缺陷模型: 通过扰动MAs,例如降低其强度或改变其分布,构建一个细节生成能力较弱的“细节缺陷”模型。 3. 自指导: 使用细节缺陷模型作为指导,引导原始模型生成更精细的细节。具体来说,可以将两个模型的输出进行加权融合,其中原始模型的权重较高,细节缺陷模型的权重较低,以保证整体语义信息的同时,提升细节质量。 4. 与CFG集成: DG可以与Classifier-Free Guidance (CFG) 无缝集成,进一步提升细节生成效果。
关键创新:论文的关键创新在于: 1. 揭示了MAs在局部细节合成中的作用: 通过实验证明了MAs对于生成高质量局部细节的重要性。 2. 提出了Detail Guidance (DG) 方法: DG是一种无需训练的自指导策略,能够有效提升Diffusion Transformer的细节生成能力。 3. 与CFG的无缝集成: DG可以与CFG结合使用,进一步提升细节生成效果。与现有方法相比,DG不需要额外的训练数据或复杂的网络结构,可以直接应用于预训练的Diffusion Transformer模型。
关键设计: 1. MAs扰动方式: 论文中可能采用了多种方式来扰动MAs,例如降低其幅度、添加噪声或改变其空间分布。具体选择哪种方式可能需要根据不同的模型和数据集进行调整。 2. 细节缺陷模型权重: 在自指导过程中,细节缺陷模型的权重是一个重要的参数。权重过高可能会导致整体语义信息的损失,权重过低则无法有效提升细节质量。需要根据实验结果选择合适的权重。 3. 与CFG的集成方式: DG可以与CFG进行加权融合,或者通过其他方式进行集成。具体集成方式的选择也需要根据实验结果进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Detail Guidance (DG) 能够显著提升各种预训练Diffusion Transformer模型(例如,SD3、SD3.5和Flux)的局部细节生成质量。DG可以与Classifier-Free Guidance (CFG) 无缝集成,进一步提升细节生成效果。具体性能数据(例如,FID、PSNR等)和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于图像超分辨率、图像修复、图像编辑等领域。通过提升生成图像的局部细节质量,可以改善用户体验,提高图像的真实感和可用性。未来,该方法有望应用于视频生成、3D建模等更复杂的视觉生成任务中,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Diffusion Transformers (DiTs) have recently emerged as a powerful backbone for visual generation. Recent observations reveal \emph{Massive Activations} (MAs) in their internal feature maps, yet their function remains poorly understood. In this work, we systematically investigate these activations to elucidate their role in visual generation. We found that these massive activations occur across all spatial tokens, and their distribution is modulated by the input timestep embeddings. Importantly, our investigations further demonstrate that these massive activations play a key role in local detail synthesis, while having minimal impact on the overall semantic content of output. Building on these insights, we propose \textbf{D}etail \textbf{G}uidance (\textbf{DG}), a MAs-driven, training-free self-guidance strategy to explicitly enhance local detail fidelity for DiTs. Specifically, DG constructs a degraded ``detail-deficient'' model by disrupting MAs and leverages it to guide the original network toward higher-quality detail synthesis. Our DG can seamlessly integrate with Classifier-Free Guidance (CFG), enabling further refinements of fine-grained details. Extensive experiments demonstrate that our DG consistently improves fine-grained detail quality across various pre-trained DiTs (\eg, SD3, SD3.5, and Flux).