AndesVL Technical Report: An Efficient Mobile-side Multimodal Large Language Model
作者: Zhiwei Jin, Xiaohui Song, Nan Wang, Yafei Liu, Chao Li, Xin Li, Ruichen Wang, Zhihao Li, Qi Qi, Long Cheng, Dongze Hao, Quanlong Zheng, Yanhao Zhang, Haobo Ji, Jian Ma, Zhitong Zheng, Zhenyi Lin, Haolin Deng, Xin Zou, Xiaojie Yin, Ruilin Wang, Liankai Cai, Haijing Liu, Yuqing Qiu, Ke Chen, Zixian Li, Chi Xie, Huafei Li, Chenxing Li, Chuangchuang Wang, Kai Tang, Zhiguang Zhu, Kai Tang, Wenmei Gao, Rui Wang, Jun Wu, Chao Liu, Qin Xie, Chen Chen, Haonan Lu
分类: cs.CV, cs.AI
发布日期: 2025-10-13 (更新: 2025-12-22)
备注: Tech report of OPPO AndesVL Team
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
AndesVL:面向移动端的高效多模态大语言模型,实现性能与效率的平衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 移动端部署 模型压缩 LoRA微调 量化感知训练 缓存淘汰算法 推测解码
📋 核心要点
- 现有云端MLLM参数量巨大,对移动端设备的内存、功耗和算力提出了严峻挑战。
- AndesVL基于Qwen3,通过优化模型架构和训练流程,构建了参数量在0.6B到4B之间的移动端MLLM。
- 实验表明,AndesVL在多个基准测试中达到一流水平,并通过优化策略显著提升了移动端部署效率。
📝 摘要(中文)
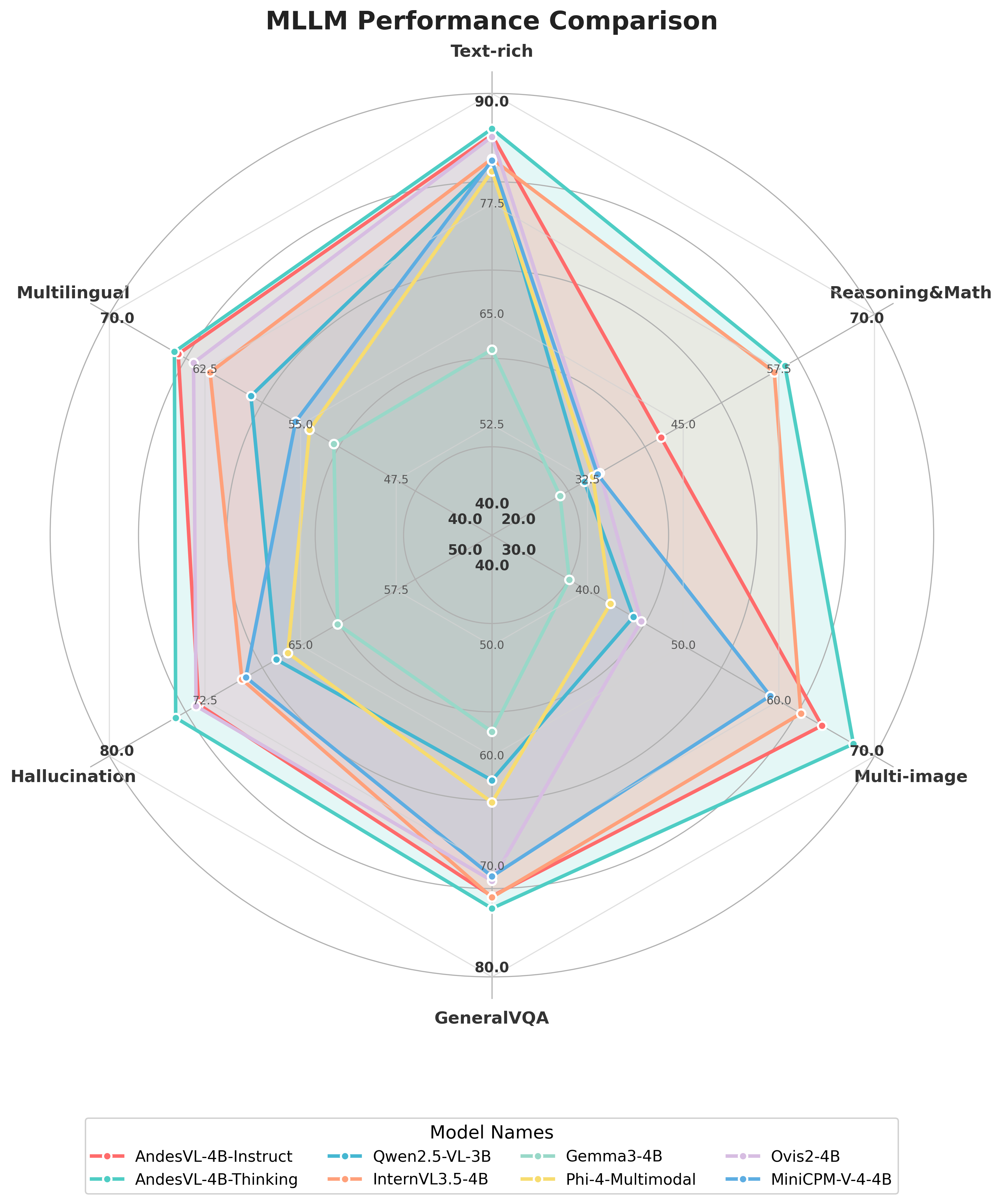
本文介绍了AndesVL,一套基于Qwen3的LLM和多种视觉编码器的移动端多模态大语言模型,参数规模从0.6B到4B。论文全面概述了AndesVL的模型架构、训练流程和训练数据。与同等规模的SOTA模型相比,AndesVL在一系列开源基准测试中取得了领先的性能,涵盖了富文本图像理解、推理与数学、多图像理解、通用VQA、幻觉缓解、多语言理解和GUI相关任务等领域。此外,论文还提出了一种1+N LoRA架构以及量化感知LoRA微调(QALFT)框架,以促进AndesVL在移动端部署期间的有效任务适配和模型压缩。通过使用缓存淘汰算法OKV,以及定制的推测解码和压缩策略,在联发科天玑9500芯片上部署AndesVL-4B时,实现了高达6.7倍的峰值解码速度提升,高达30.9%的内存减少,以及1.8 bits-per-weight的模型压缩。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLM),如QwenVL、InternVL、GPT-4o、Gemini和Claude Sonnet,虽然在云端表现出色,但由于模型参数巨大,对移动端设备的内存、功耗和计算能力提出了极高的要求。如何在移动端部署高性能的MLLM是一个关键问题。
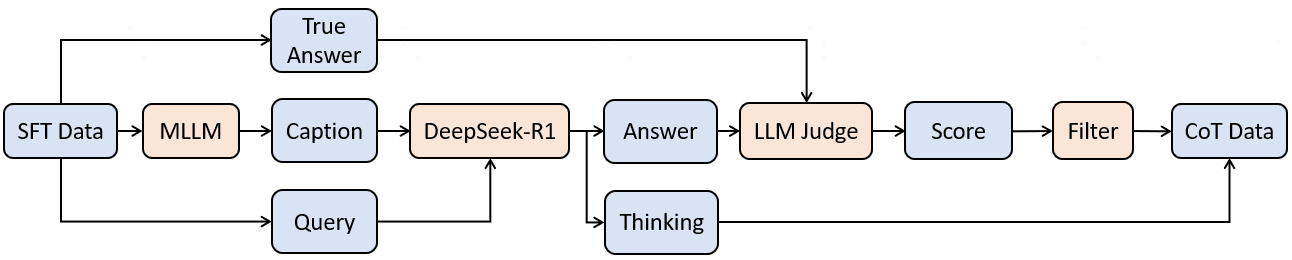
核心思路:AndesVL的核心思路是在保证模型性能的前提下,尽可能地减小模型尺寸,并针对移动端设备的特点进行优化。这包括选择合适的模型架构、设计高效的训练流程、采用有效的模型压缩和加速技术。
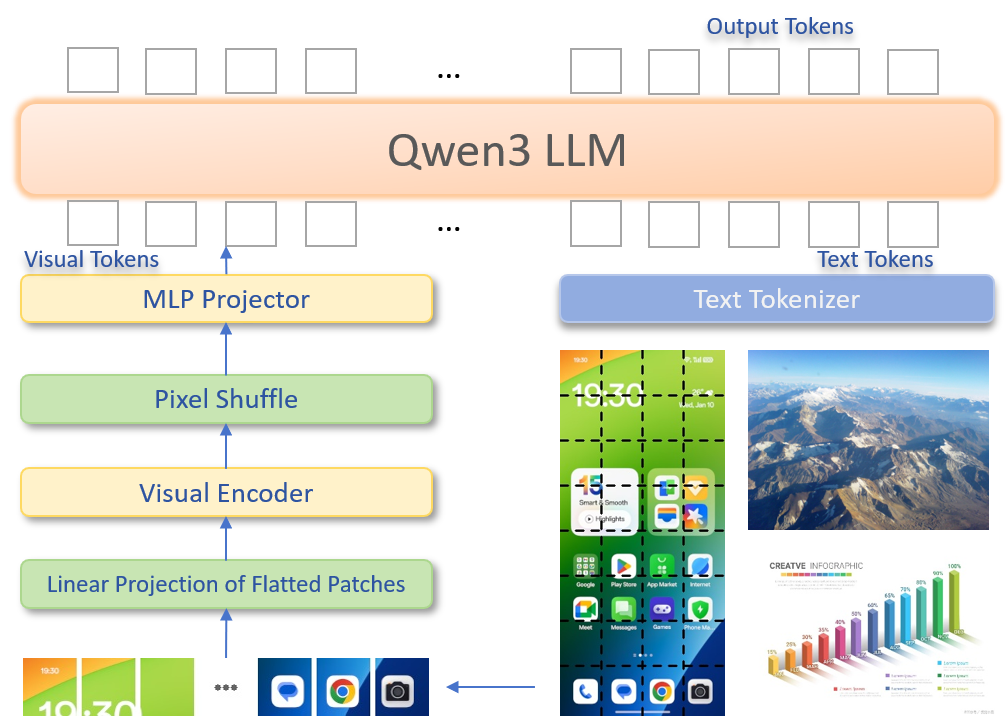
技术框架:AndesVL的技术框架主要包括以下几个部分:1) 基于Qwen3的LLM作为基础语言模型;2) 多种视觉编码器用于处理图像输入;3) 1+N LoRA架构用于任务适配;4) 量化感知LoRA微调(QALFT)框架用于模型压缩;5) 缓存淘汰算法OKV以及定制的推测解码和压缩策略用于加速推理。
关键创新:AndesVL的关键创新点在于:1) 针对移动端设备特点,设计了参数量较小的MLLM;2) 提出了1+N LoRA架构和QALFT框架,实现了高效的任务适配和模型压缩;3) 开发了OKV缓存淘汰算法和定制的推测解码策略,显著提升了推理速度。
关键设计:1+N LoRA架构允许为每个任务训练一个LoRA模块,并在推理时动态选择。QALFT框架在微调过程中考虑了量化的影响,从而减少了量化带来的性能损失。OKV算法根据token的使用频率和重要性进行缓存淘汰,提高了缓存命中率。推测解码策略通过预测下一个token来减少计算量。
🖼️ 关键图片
📊 实验亮点
AndesVL在多个开源基准测试中取得了领先的性能,与同等规模的SOTA模型相比,在富文本图像理解、推理与数学、多图像理解、通用VQA、幻觉缓解、多语言理解和GUI相关任务等领域均表现出色。在联发科天玑9500芯片上部署AndesVL-4B时,实现了高达6.7倍的峰值解码速度提升,高达30.9%的内存减少,以及1.8 bits-per-weight的模型压缩。
🎯 应用场景
AndesVL可广泛应用于移动设备上的各种多模态应用,如智能助手、图像搜索、视觉问答、文档理解、GUI自动化等。它能够在离线或低延迟环境下提供强大的多模态理解和生成能力,提升用户体验,并为移动端AI应用开辟新的可能性。
📄 摘要(原文)
In recent years, while cloud-based MLLMs such as QwenVL, InternVL, GPT-4o, Gemini, and Claude Sonnet have demonstrated outstanding performance with enormous model sizes reaching hundreds of billions of parameters, they significantly surpass the limitations in memory, power consumption, and computing capacity of edge devices such as mobile phones. This paper introduces AndesVL, a suite of mobile-side MLLMs with 0.6B to 4B parameters based on Qwen3's LLM and various visual encoders. We comprehensively outline the model architectures, training pipeline, and training data of AndesVL, which achieves first-tier performance across a wide range of open-source benchmarks, including fields such as text-rich image understanding, reasoning and math, multi-image comprehension, general VQA, hallucination mitigation, multilingual understanding, and GUI-related tasks when compared with state-of-the-art models of a similar scale. Furthermore, we introduce a 1+N LoRA architecture alongside a Quantization-Aware LoRA Fine-Tuning (QALFT) framework to facilitate efficient task adaptation and model compression during mobile-side deployment of AndesVL. Moreover, utilizing our cache eviction algorithm -- OKV -- along with customized speculative decoding and compression strategies, we achieve a 6.7x peak decoding speedup ratio, up to 30.9% memory reduction, and 1.8 bits-per-weight when deploying AndesVL-4B on MediaTek Dimensity 9500 chips. We release all models on https://huggingface.co/OPPOer.