InternSVG: Towards Unified SVG Tasks with Multimodal Large Language Models
作者: Haomin Wang, Jinhui Yin, Qi Wei, Wenguang Zeng, Lixin Gu, Shenglong Ye, Zhangwei Gao, Yaohui Wang, Yanting Zhang, Yuanqi Li, Yanwen Guo, Wenhai Wang, Kai Chen, Yu Qiao, Hongjie Zhang
分类: cs.CV
发布日期: 2025-10-13 (更新: 2026-01-29)
💡 一句话要点
InternSVG:利用多模态大语言模型实现统一的SVG任务处理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: SVG建模 多模态大语言模型 统一建模 数据集 基准测试 SVG理解 SVG编辑 SVG生成
📋 核心要点
- 现有SVG建模方法面临数据集分散、任务间迁移性差以及难以处理结构复杂性等挑战。
- InternSVG利用多模态大语言模型,结合SVG特定token和两阶段训练策略,实现SVG理解、编辑和生成的统一建模。
- 实验表明,InternSVG在SArena和现有基准测试中均取得了显著提升,超越了现有的开源和商业模型。
📝 摘要(中文)
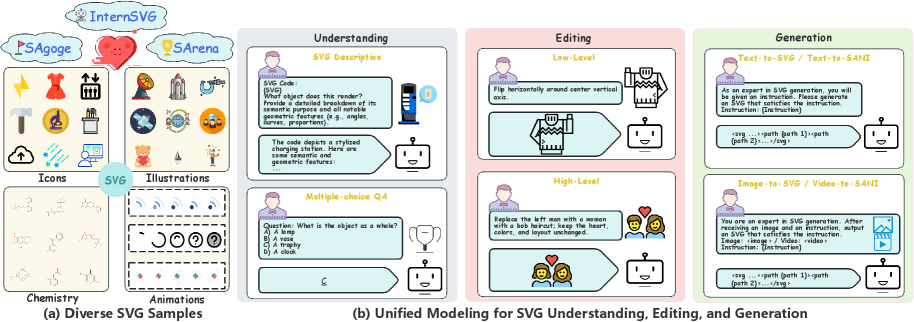
由于数据集分散、方法在任务间的迁移性有限以及结构复杂性难以处理,通用SVG建模仍然具有挑战性。为了解决这些问题,本文利用多模态大语言模型(MLLM)强大的迁移和泛化能力,实现了SVG理解、编辑和生成的统一建模。我们提出了InternSVG系列,这是一个集成的数据-基准-模型套件。其核心是SAgoge,这是最大、最全面的SVG任务多模态数据集,涵盖静态图形和动态动画。它覆盖了图标、长序列插图、科学图表和动态动画,支持不同难度级别的任务,并提供比以前的数据集更深层次的层次结构和更丰富的属性。基于此,我们引入了SArena,这是一个配套基准,具有全面的任务定义和标准化评估,与SAgoge所涵盖的领域和难度范围相一致。在此基础上,我们提出了InternSVG,一个统一的MLLM,用于SVG理解、编辑和生成,具有SVG特定的特殊token、基于子词的嵌入初始化以及一个两阶段训练策略,从短静态SVG到长序列插图和复杂动画。这种统一的公式诱导了正迁移并提高了整体性能。在SArena和之前的基准测试上的实验证实,InternSVG取得了显著的收益,并且始终优于领先的开源和专有模型。
🔬 方法详解
问题定义:论文旨在解决通用SVG建模中数据集分散、方法在不同任务间迁移性差以及难以处理结构复杂性的问题。现有方法难以同时处理SVG的理解、编辑和生成,且在处理复杂结构和长序列动画时性能受限。
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)强大的迁移学习和泛化能力,将SVG理解、编辑和生成任务统一到一个框架下。通过构建大规模数据集和设计特定的训练策略,使MLLM能够有效地处理SVG的结构复杂性和动态特性。
技术框架:InternSVG的技术框架主要包括三个部分:SAgoge数据集、SArena基准和InternSVG模型。SAgoge数据集是用于训练和评估模型的大规模多模态SVG数据集,涵盖静态图形和动态动画。SArena基准定义了全面的SVG任务和标准化评估方法。InternSVG模型是一个基于MLLM的统一模型,用于SVG理解、编辑和生成。模型采用两阶段训练策略,首先在短静态SVG上进行训练,然后逐步过渡到长序列插图和复杂动画。
关键创新:论文的关键创新在于提出了一个统一的MLLM框架,能够同时处理SVG的理解、编辑和生成任务。此外,论文还构建了大规模的SAgoge数据集和SArena基准,为SVG建模研究提供了重要的资源。另一个创新点是采用了SVG特定的特殊token和子词嵌入初始化,以及两阶段训练策略,提高了模型在复杂SVG任务上的性能。
关键设计:InternSVG模型采用了SVG特定的特殊token,用于表示SVG的各种元素和属性。模型使用子词嵌入初始化,以更好地处理SVG中的长词和复杂词汇。两阶段训练策略首先在简单的静态SVG上进行训练,然后逐步过渡到复杂的动态SVG,以提高模型的泛化能力。损失函数方面,可能采用了交叉熵损失或类似的损失函数,用于优化模型的生成和预测能力(具体损失函数细节未知)。
🖼️ 关键图片
📊 实验亮点
InternSVG在SArena基准测试中取得了显著的性能提升,并在多个SVG任务上超越了现有的开源和商业模型。具体性能数据未知,但论文强调InternSVG在理解、编辑和生成SVG方面的整体性能均优于其他方法,证明了其统一建模方法的有效性。
🎯 应用场景
InternSVG具有广泛的应用前景,可用于智能设计、教育、科学可视化、游戏开发等领域。例如,可以用于自动生成图标、编辑科学图表、创建动画内容等。该研究的成果有助于降低SVG内容创作的门槛,提高SVG内容创作的效率,并促进SVG技术在各个领域的应用。
📄 摘要(原文)
General SVG modeling remains challenging due to fragmented datasets, limited transferability of methods across tasks, and the difficulty of handling structural complexity. In response, we leverage the strong transfer and generalization capabilities of multimodal large language models (MLLMs) to achieve unified modeling for SVG understanding, editing, and generation. We present the InternSVG family, an integrated data-benchmark-model suite. At its core is SAgoge, the largest and most comprehensive multimodal dataset for SVG tasks, encompassing both static graphics and dynamic animations. It covers icons, long-sequence illustrations, scientific diagrams, and dynamic animations, supporting tasks of varied difficulty levels and providing deeper hierarchies with richer attributes compared to previous datasets. Based on this resource, we introduce SArena, a companion benchmark with comprehensive task definitions and standardized evaluation that aligns with the domains and difficulty spectrum covered by SAgoge. Building on these foundations, we propose InternSVG, a unified MLLM for SVG understanding, editing, and generation with SVG-specific special tokens, subword-based embedding initialization, and a two-stage training strategy that progresses from short static SVGs to long-sequence illustrations and complex animations. This unified formulation induces positive transfer and improves overall performance. Experiments on SArena and prior benchmark confirm that InternSVG achieves substantial gains and consistently outperforms leading open and proprietary counterparts.