A Large-Language-Model Assisted Automated Scale Bar Detection and Extraction Framework for Scanning Electron Microscopic Images
作者: Yuxuan Chen, Ruotong Yang, Zhengyang Zhang, Mehreen Ahmed, Yanming Wang
分类: cs.CV, cond-mat.mtrl-sci, cs.AI, physics.data-an
发布日期: 2025-10-13
备注: 14 pages, 6 figures
💡 一句话要点
提出一种基于大语言模型的扫描电镜图像比例尺自动检测与提取框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扫描电镜图像分析 比例尺检测 大语言模型 多模态学习 对象检测 光学字符识别 自动数据集生成
📋 核心要点
- 当前扫描电镜图像比例尺的确定主要依赖手动操作,耗时且容易出错,限制了微观结构分析的效率。
- 提出一种基于大语言模型辅助的多模态框架,融合对象检测、文本检测和识别,实现比例尺的自动检测与提取。
- 实验结果表明,该方法在对象检测和文本识别方面均优于现有方法,显著提升了比例尺检测和提取的效率和准确性。
📝 摘要(中文)
本文提出了一种多模态自动比例尺检测与提取框架,用于扫描电子显微镜(SEM)图像分析。该框架利用大语言模型(LLM)代理,实现对象检测、文本检测和文本识别的同步进行。框架包含四个阶段:(i)自动数据集生成(Auto-DG),合成多样化的SEM图像数据集,确保模型的鲁棒性和泛化性;(ii)比例尺对象检测;(iii)使用混合光学字符识别(OCR)系统进行信息提取,该系统结合了基于DenseNet和卷积循环神经网络(CRNN)的算法;(iv)LLM代理分析和验证结果的准确性。实验结果表明,该模型在对象检测方面表现出色,精度为100%,召回率为95.8%,在IoU=0.5时mAP为99.2%,在IoU=0.5:0.95时mAP为69.1%。混合OCR系统在Auto-DG数据集上实现了89%的精度、65%的召回率和75%的F1分数,显著优于几种主流的独立引擎。LLM作为推理引擎和智能助手,可以建议后续步骤并验证结果。该自动化方法显著提高了SEM图像中比例尺检测和提取的效率和准确性。
🔬 方法详解
问题定义:扫描电镜图像分析中,比例尺的准确识别是关键步骤。然而,现有方法主要依赖人工操作,效率低下且容易出错,阻碍了科学研究的进展。因此,需要一种自动、准确的比例尺检测与提取方法。
核心思路:利用大语言模型(LLM)的推理能力,结合计算机视觉技术,构建一个多模态框架,实现比例尺的自动检测、文本识别和结果验证。通过自动生成数据集来增强模型的泛化能力,并使用混合OCR系统提高文本识别的准确性。
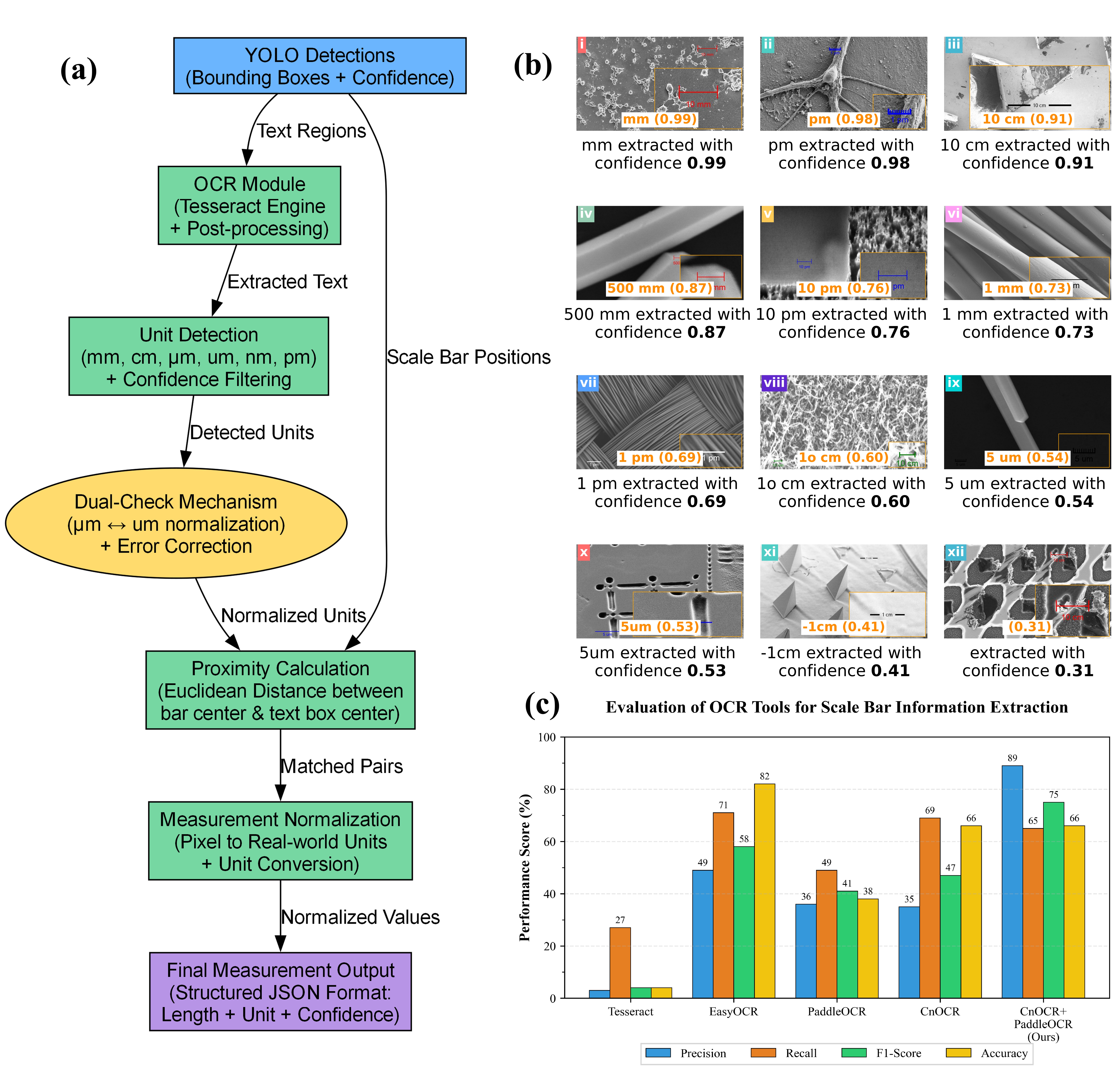
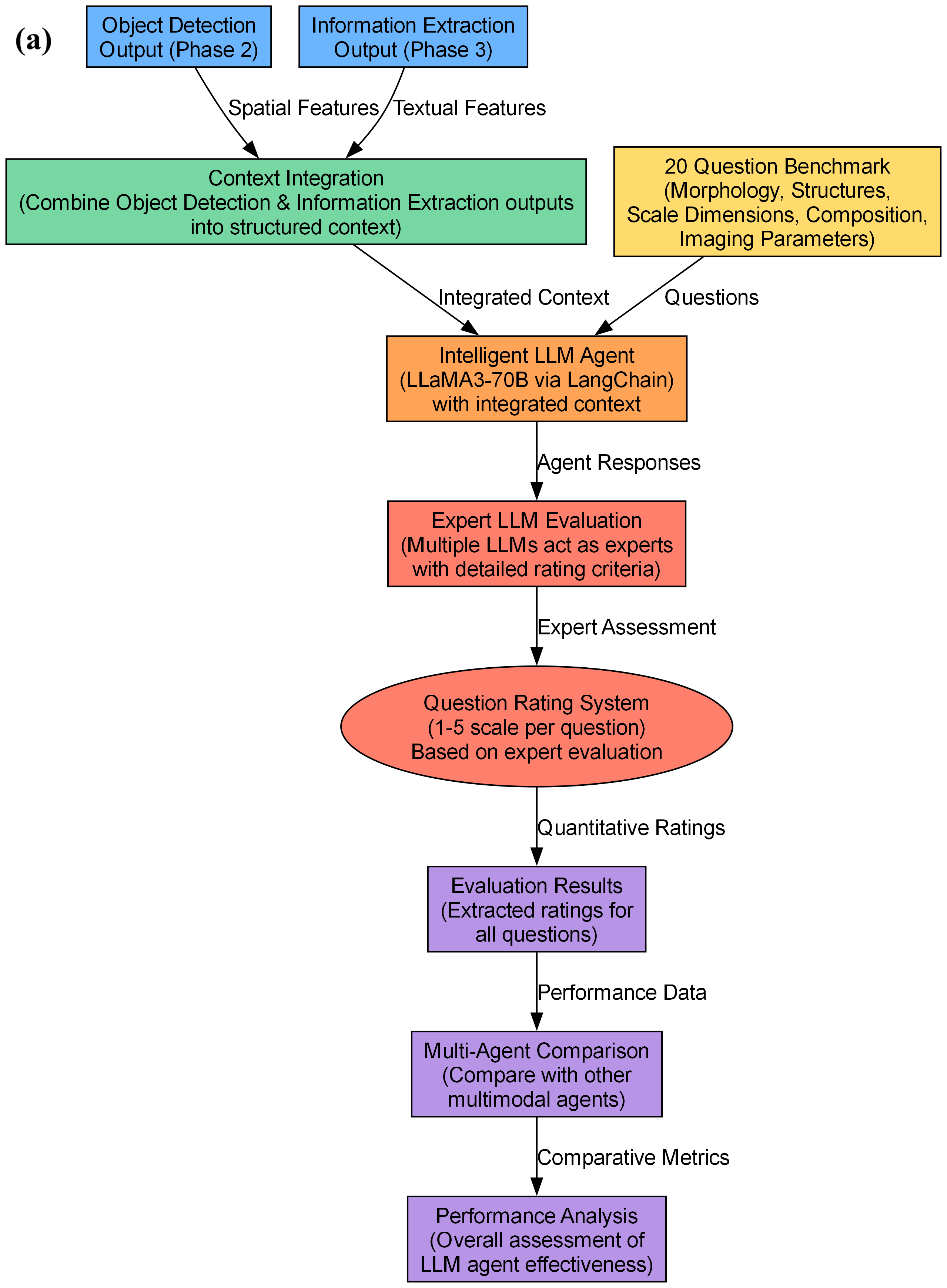
技术框架:该框架包含四个主要阶段:1) 自动数据集生成(Auto-DG):合成多样化的SEM图像数据集;2) 比例尺对象检测:使用对象检测模型定位图像中的比例尺;3) 信息提取:使用混合OCR系统识别比例尺上的文本信息;4) LLM代理:利用LLM分析和验证结果的准确性,并提供后续步骤建议。
关键创新:该方法的核心创新在于将大语言模型引入到扫描电镜图像分析中,利用LLM的推理能力来验证和修正检测结果,从而提高整体的准确性和可靠性。此外,自动数据集生成技术也提高了模型的泛化能力。
关键设计:混合OCR系统结合了DenseNet和CRNN两种算法的优势,DenseNet用于提取图像特征,CRNN用于序列文本识别。LLM代理使用Prompt Engineering来指导其进行结果验证和后续步骤建议。Auto-DG模型通过随机改变比例尺的位置、大小、字体和背景等参数来生成多样化的数据集。
🖼️ 关键图片

📊 实验亮点
该模型在对象检测方面达到了100%的精度和95.8%的召回率,mAP在IoU=0.5时为99.2%,在IoU=0.5:0.95时为69.1%。混合OCR系统在Auto-DG数据集上实现了89%的精度、65%的召回率和75%的F1分数,显著优于主流的独立OCR引擎,证明了该方法的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于材料科学、生物医学等领域,为扫描电镜图像的自动分析提供了一种高效、准确的解决方案。该方法可以减少人工干预,提高科研效率,加速新材料和新技术的研发进程,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Microscopic characterizations, such as Scanning Electron Microscopy (SEM), are widely used in scientific research for visualizing and analyzing microstructures. Determining the scale bars is an important first step of accurate SEM analysis; however, currently, it mainly relies on manual operations, which is both time-consuming and prone to errors. To address this issue, we propose a multi-modal and automated scale bar detection and extraction framework that provides concurrent object detection, text detection and text recognition with a Large Language Model (LLM) agent. The proposed framework operates in four phases; i) Automatic Dataset Generation (Auto-DG) model to synthesize a diverse dataset of SEM images ensuring robust training and high generalizability of the model, ii) scale bar object detection, iii) information extraction using a hybrid Optical Character Recognition (OCR) system with DenseNet and Convolutional Recurrent Neural Network (CRNN) based algorithms, iv) an LLM agent to analyze and verify accuracy of the results. The proposed model demonstrates a strong performance in object detection and accurate localization with a precision of 100%, recall of 95.8%, and a mean Average Precision (mAP) of 99.2% at IoU=0.5 and 69.1% at IoU=0.5:0.95. The hybrid OCR system achieved 89% precision, 65% recall, and a 75% F1 score on the Auto-DG dataset, significantly outperforming several mainstream standalone engines, highlighting its reliability for scientific image analysis. The LLM is introduced as a reasoning engine as well as an intelligent assistant that suggests follow-up steps and verifies the results. This automated method powered by an LLM agent significantly enhances the efficiency and accuracy of scale bar detection and extraction in SEM images, providing a valuable tool for microscopic analysis and advancing the field of scientific imaging.