CoPRS: Learning Positional Prior from Chain-of-Thought for Reasoning Segmentation
作者: Zhenyu Lu, Liupeng Li, Jinpeng Wang, Yan Feng, Bin Chen, Ke Chen, Yaowei Wang
分类: cs.CV, cs.MM
发布日期: 2025-10-13 (更新: 2025-12-10)
备注: 20 pages, 8 figures, 7 tables
🔗 代码/项目: GITHUB
💡 一句话要点
CoPRS:提出基于思维链的位置先验学习方法,用于提升推理分割任务的性能与可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理分割 思维链 位置先验 多模态学习 可解释性
📋 核心要点
- 现有推理分割方法缺乏可解释性,且语义细节不足,限制了模型性能。
- CoPRS利用多模态思维链生成位置先验热图,连接语言推理和分割,提升可解释性。
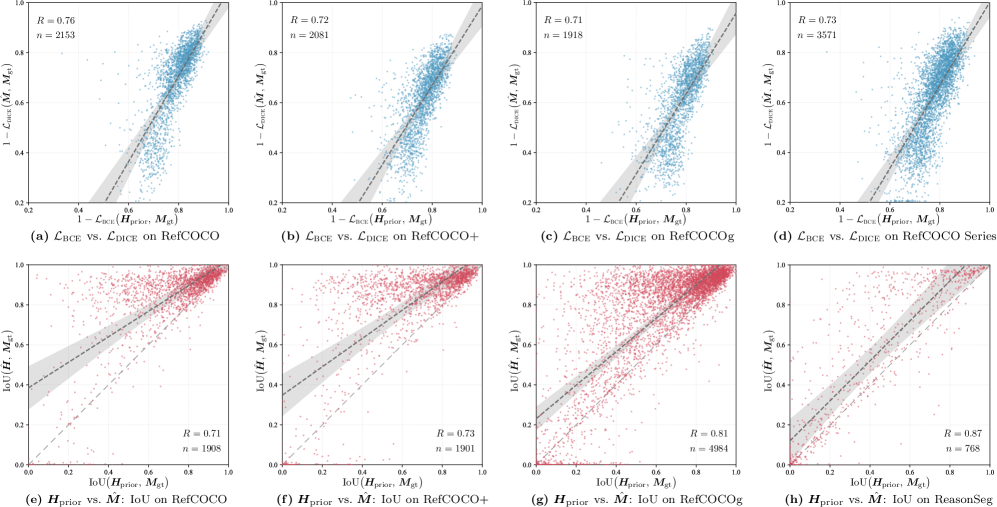
- 实验表明,CoPRS在RefCOCO和ReasonSeg数据集上达到或超过了当前最佳性能。
📝 摘要(中文)
本文提出了一种基于多模态思维链(MCoT)的位置感知模型CoPRS,旨在通过可微且可解释的位置先验(以热图形式呈现)来桥接语言推理和分割任务。通过MCoT明确推理过程,并将其表达为密集的、可微的热图,该接口增强了解释性和诊断分析,并在目标上产生更集中的证据。一个可学习的注意力token聚合图像和推理文本的特征,以生成位置先验,并通过轻量级解码器将其解码为精确的掩码,从而在推理和分割之间建立直接联系。在RefCOCO系列和ReasonSeg数据集上,CoPRS在可比协议下匹配或超过了每个标准分割上报告的最佳指标,在验证和测试集上的性能均达到或超过了先前的最先进水平。大量实验表明,CoT轨迹、生成的热图和解码的掩码之间存在很强的正相关性,支持推理输出和下游掩码生成之间的可解释对齐。这些发现共同支持了这种范式在桥接推理和分割方面的效用,并展示了推理驱动的注意力和更精确的掩码预测方面的优势。
🔬 方法详解
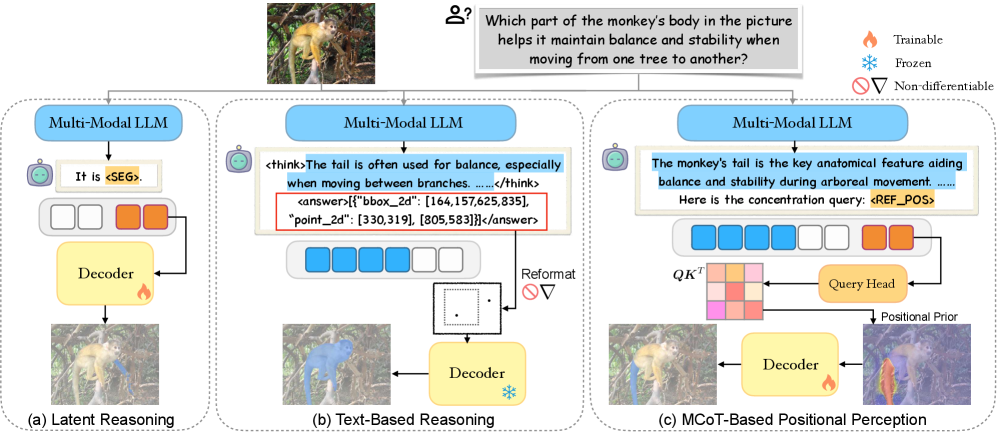
问题定义:现有推理分割方法主要存在两个痛点:一是直接将语言模型的隐藏特征连接到掩码解码器,缺乏明确的推理过程;二是仅在文本中表示位置信息,忽略了图像中的空间关系,导致语义细节不足,可解释性较差。这些限制阻碍了模型性能的进一步提升,也难以进行诊断分析。
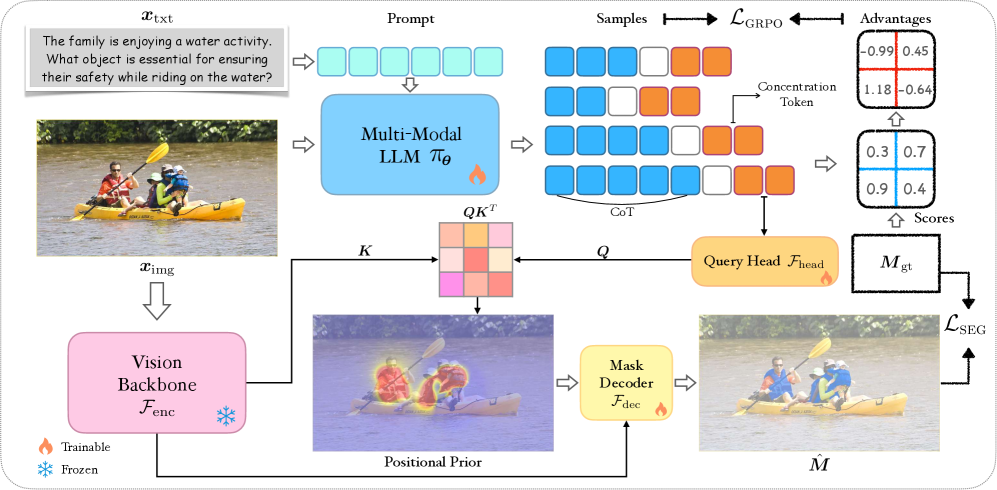
核心思路:CoPRS的核心思路是通过引入一个可学习的位置先验,以热图的形式显式地表达推理过程中的位置信息。该热图由多模态思维链(MCoT)驱动,将语言推理过程转化为图像上的空间注意力分布,从而将语言推理和分割任务联系起来。这种设计使得模型具有更强的可解释性,并能更有效地利用图像和文本信息。
技术框架:CoPRS的整体框架包含以下几个主要模块:1) 多模态思维链(MCoT)模块,用于生成推理文本;2) 注意力Token模块,用于聚合图像和推理文本的特征;3) 位置先验生成模块,将聚合后的特征转化为位置先验热图;4) 轻量级解码器,将位置先验热图解码为精确的分割掩码。整个流程是端到端可训练的。
关键创新:CoPRS的关键创新在于引入了基于思维链的位置先验学习方法。与现有方法相比,CoPRS通过MCoT显式地建模推理过程,并将推理结果转化为可解释的位置先验热图,从而实现了语言推理和分割任务的有效桥接。此外,CoPRS还设计了一个可学习的注意力Token,用于聚合图像和推理文本的特征,从而更好地利用多模态信息。
关键设计:CoPRS的关键设计包括:1) MCoT模块的具体实现,例如使用的语言模型类型和推理策略;2) 注意力Token的结构和训练方式;3) 位置先验热图的生成方式,例如使用的卷积神经网络结构和激活函数;4) 轻量级解码器的结构和损失函数。论文中可能还涉及一些超参数的设置,例如学习率、batch size等。
🖼️ 关键图片
📊 实验亮点
CoPRS在RefCOCO系列和ReasonSeg数据集上取得了显著的性能提升,匹配或超过了现有最佳方法。实验结果表明,CoPRS生成的热图与CoT轨迹和分割掩码之间存在很强的正相关性,验证了其可解释性。此外,CoPRS在推理驱动的注意力和精确掩码预测方面表现出优势。
🎯 应用场景
CoPRS具有广泛的应用前景,例如在视觉导航、机器人操作、医学图像分析等领域。通过结合语言推理和视觉分割,CoPRS可以帮助机器人理解人类指令并执行复杂任务,辅助医生进行疾病诊断和治疗规划,提升视觉导航系统的智能化水平。该研究对于推动人工智能在实际场景中的应用具有重要意义。
📄 摘要(原文)
Existing works on reasoning segmentation either connect hidden features from a language model directly to a mask decoder or represent positions in text, which limits interpretability and semantic detail. To solve this, we present CoPRS, a Multi-modal Chain-of-Thought (MCoT)-based positional perception model that bridges language reasoning to segmentation through a differentiable and interpretable positional prior instantiated as a heatmap. By making the reasoning process clear via MCoT and expressing it as a dense, differentiable heatmap, this interface enhances interpretability and diagnostic analysis and yields more concentrated evidence on the target. A learnable concentration token aggregates features of the image and reasoning text to generate this positional prior, which is decoded to precise masks through a lightweight decoder, providing a direct connection between reasoning and segmentation. Across the RefCOCO series and ReasonSeg, CoPRS matches or surpasses the best reported metrics on each standard split under comparable protocols, with performance at or above the prior state of the art across both validation and test partitions. Extensive experiments demonstrate a strong positive correlation among the CoT trajectory, the generated heatmap, and the decoded mask, supporting an interpretable alignment between the reasoning output and downstream mask generation. Collectively, these findings support the utility of this paradigm in bridging reasoning and segmentation and show advantages in concentration driven by reasoning and in more precise mask prediction. Code, checkpoints and logs are released at https://github.com/ZhenyuLU-Heliodore/CoPRS.git.