video-SALMONN S: Memory-Enhanced Streaming Audio-Visual LLM
作者: Guangzhi Sun, Yixuan Li, Xiaodong Wu, Yudong Yang, Wei Li, Zejun Ma, Chao Zhang
分类: cs.CV, cs.AI
发布日期: 2025-10-13 (更新: 2026-02-03)
💡 一句话要点
提出video-SALMONN S,通过测试时训练增强长时音频-视频流式LLM的记忆能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 流式处理 测试时训练 多模态学习 大语言模型
📋 核心要点
- 现有长时视频理解方法缺乏有效的长期记忆机制,限制了AI代理在复杂环境中的应用。
- video-SALMONN S利用测试时训练(TTT)将短期多模态信息融入模型参数,形成长期记忆。
- 实验表明,该模型在长视频理解和情景学习任务上显著优于现有流式和非流式模型。
📝 摘要(中文)
长时流式视频理解是未来AI代理的基础,但受限于低效的长期记忆。我们提出了video-SALMONN S,一种记忆增强的流式音频-视频大语言模型,能够以1 FPS和360p分辨率处理超过3小时的视频,并在相同内存预算下优于强大的非流式模型。除了token合并或下采样,video-SALMONN S首次采用测试时训练(TTT)作为视频理解的流式记忆机制。TTT持续将短期多模态表示转换为嵌入在模型参数中的长期记忆。为了改进长程依赖建模和记忆容量,我们提出了(i)具有额外长跨度预测目标的TTT_MEM层,(ii)两阶段训练方案,以及(iii)模态感知记忆读取器。我们进一步引入了视频记忆情景学习(ELViM)基准,模拟了智能体需要在数小时前观察的视频中学习的场景。在长视频基准测试中,video-SALMONN S始终优于流式和非流式基线3-7%。值得注意的是,video-SALMONN S在ELViM上实现了比强大的非流式模型高出15%的绝对精度提升,展示了从视频记忆中强大的学习能力。
🔬 方法详解
问题定义:现有方法在处理长时流式视频理解任务时,面临着长期记忆能力不足的问题。传统的token合并或下采样方法会丢失关键信息,而大型非流式模型则需要巨大的计算资源和内存,难以应用于实际场景。因此,如何有效地利用有限的内存,并从中学习和推理,是长时视频理解的关键挑战。
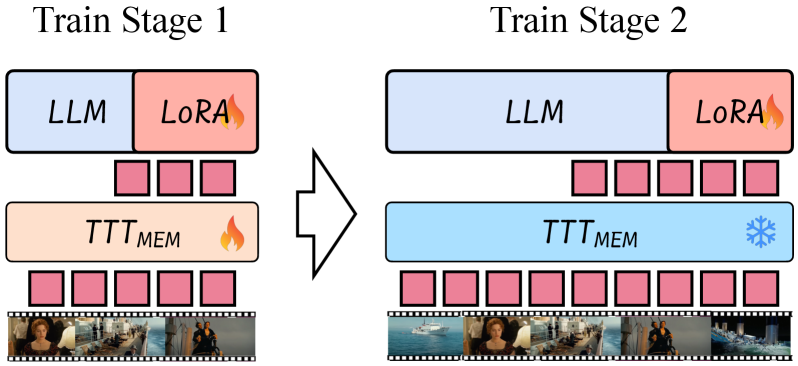
核心思路:video-SALMONN S的核心思路是利用测试时训练(TTT)作为一种流式记忆机制。TTT通过在测试阶段持续更新模型参数,将短期多模态表示转化为长期记忆,从而避免了显式地存储和检索长期记忆。这种方法能够有效地利用模型参数作为记忆载体,并在处理新视频时不断地学习和适应。
技术框架:video-SALMONN S的整体框架包括以下几个主要模块:1) 音频和视频编码器:将原始音频和视频数据编码为多模态特征表示。2) TTT_MEM层:该层是核心创新,通过额外的长跨度预测目标,增强了模型对长程依赖的建模能力。3) 模态感知记忆读取器:根据不同模态的重要性,自适应地读取长期记忆。4) 两阶段训练方案:首先进行预训练,然后进行测试时训练,以提高模型的泛化能力和适应性。
关键创新:最重要的技术创新点是测试时训练(TTT)作为流式记忆机制的应用,以及TTT_MEM层的设计。TTT允许模型在处理视频流的同时不断学习和更新,从而有效地利用有限的内存。TTT_MEM层通过额外的长跨度预测目标,进一步增强了模型对长程依赖的建模能力。
关键设计:TTT_MEM层的关键设计包括:1) 长跨度预测目标:鼓励模型预测更长时间跨度内的事件,从而增强其长期记忆能力。2) 模态感知记忆读取器:根据不同模态的重要性,自适应地调整读取权重,从而提高模型的性能。3) 两阶段训练方案:首先使用大量数据进行预训练,然后使用测试时训练进行微调,以提高模型的泛化能力和适应性。
🖼️ 关键图片


📊 实验亮点
video-SALMONN S在长视频基准测试中,性能优于流式和非流式基线3-7%。在ELViM基准测试中,video-SALMONN S实现了比强大的非流式模型高出15%的绝对精度提升,证明了其强大的从视频记忆中学习的能力。这些结果表明,该模型在长时视频理解和情景学习任务上具有显著优势。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、机器人导航等领域。通过对长时间视频流的理解和学习,AI系统能够更好地感知环境、预测事件,并做出更合理的决策。例如,在智能监控中,系统可以自动检测异常行为并发出警报;在自动驾驶中,系统可以预测行人和车辆的运动轨迹,从而提高安全性。
📄 摘要(原文)
Long-duration streaming video understanding is fundamental for future AI agents, yet remains limited by ineffective long-term memory. We introduce video-SALMONN S, a memory-enhanced streaming audio-visual large language model that processes over 3-hour videos at 1 FPS and 360p resolution, outperforming strong non-streaming models under the same memory budget. In addition to token merging or downsampling, video-SALMONN S is the first to employ test-time training (TTT) as a streaming memory mechanism for video understanding. TTT continuously transforms short-term multimodal representations into long-term memory embedded in model parameters. To improve long-range dependency modeling and memory capacity, we propose (i) a TTT_MEM layer with an additional long-span prediction objective, (ii) a two-stage training scheme, and (iii) a modality-aware memory reader. We further introduce the Episodic Learning from Video Memory (ELViM) benchmark, simulating agent-like scenarios where models must learn from videos observed hours earlier. video-SALMONN S consistently outperforms both streaming and non-streaming baselines by 3-7% on long video benchmarks. Notably, video-SALMONN S achieves a 15% absolute accuracy improvement over strong non-streaming models on ELViM, demonstrating strong learning abilities from video memory.