MoMaps: Semantics-Aware Scene Motion Generation with Motion Maps
作者: Jiahui Lei, Kyle Genova, George Kopanas, Noah Snavely, Leonidas Guibas
分类: cs.CV
发布日期: 2025-10-13
备注: Accepted at ICCV 2025, project page: https://jiahuilei.com/projects/momap/
💡 一句话要点
提出基于运动图(MoMap)的语义感知场景运动生成方法,实现单图预测未来3D场景运动。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 场景运动生成 运动图 扩散模型 视频合成 3D运动预测
📋 核心要点
- 现有方法难以从单张图像预测未来3D场景运动,缺乏对语义和功能信息的有效利用。
- 提出一种基于运动图(MoMap)的表示方法,利用生成图像模型高效预测3D场景运动。
- 通过大规模真实视频数据训练扩散模型,实验证明该方法能生成合理且语义一致的3D场景运动。
📝 摘要(中文)
本文旨在解决从真实视频中学习具有语义和功能意义的3D运动先验的挑战,从而能够从单个输入图像预测未来的3D场景运动。我们提出了一种新颖的像素对齐的运动图(MoMap)表示,用于3D场景运动,它可以从现有的生成图像模型生成,以促进高效和有效的运动预测。为了学习有意义的运动分布,我们从超过50,000个真实视频中创建了一个大规模的MoMap数据库,并在此表示上训练了一个扩散模型。我们的运动生成不仅合成了3D轨迹,还为2D视频合成提出了一种新的流程:首先生成一个MoMap,然后相应地扭曲图像并完成扭曲的基于点的渲染。实验结果表明,我们的方法生成了合理且语义一致的3D场景运动。
🔬 方法详解
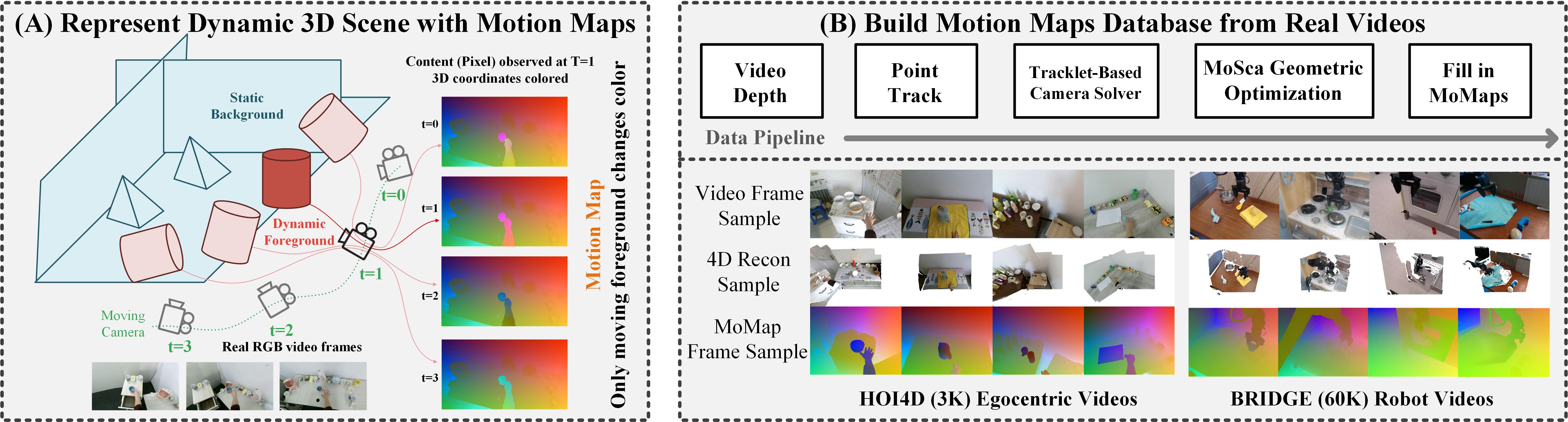
问题定义:论文旨在解决从单张图像预测未来3D场景运动的问题。现有方法难以捕捉场景中物体的语义信息和功能关系,导致预测的运动不真实或不符合物理规律。此外,直接预测3D运动轨迹计算量大,效率较低。
核心思路:论文的核心思路是引入一种新的中间表示——运动图(MoMap),将3D场景运动编码为像素对齐的运动向量场。MoMap可以从现有的生成图像模型中生成,从而利用图像生成领域的进展来促进运动预测。通过学习MoMap的分布,可以生成更真实、更符合语义的运动。
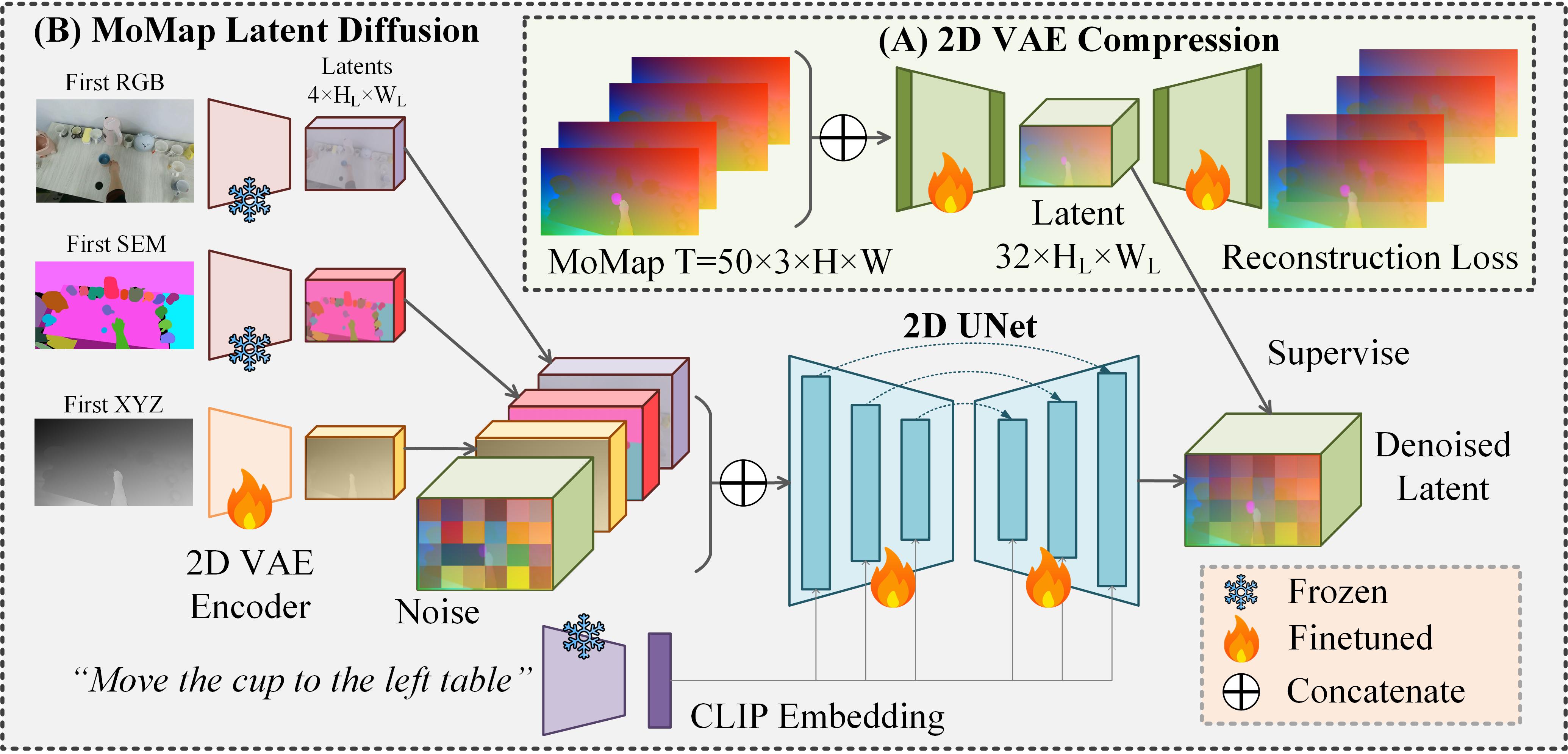
技术框架:整体框架包含以下几个主要步骤:1) 从真实视频中提取3D场景运动,并将其转换为MoMap表示。2) 构建大规模MoMap数据集。3) 在MoMap数据集上训练扩散模型,学习MoMap的生成分布。4) 给定单张输入图像,使用训练好的扩散模型生成MoMap。5) 根据生成的MoMap,扭曲输入图像,并进行基于点的渲染,生成未来的视频帧。
关键创新:最重要的技术创新点在于MoMap表示。MoMap将3D运动信息编码为像素级别的运动向量,从而可以利用现有的图像生成模型来生成运动。与直接预测3D运动轨迹相比,MoMap表示更加高效,并且更容易学习。此外,该方法还提出了一种新的2D视频合成流程,即先生成MoMap,再扭曲图像。
关键设计:论文使用扩散模型来学习MoMap的生成分布。扩散模型是一种强大的生成模型,可以生成高质量的图像。论文使用U-Net作为扩散模型的骨干网络,并使用L1损失和感知损失来训练模型。此外,论文还设计了一种基于点的渲染方法,用于将扭曲后的图像渲染成视频帧。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够生成合理且语义一致的3D场景运动。与现有方法相比,该方法生成的运动更加真实,并且能够更好地捕捉场景中的语义信息。通过大规模数据集的训练,该方法能够生成各种各样的运动模式,包括人物行走、车辆行驶等。定性结果表明,生成的视频帧具有较高的视觉质量。
🎯 应用场景
该研究成果可应用于视频游戏、电影制作、机器人导航等领域。例如,在视频游戏中,可以利用该方法生成逼真的角色运动和场景变化,提升游戏体验。在机器人导航中,可以预测周围环境的未来运动,帮助机器人做出更安全的决策。该研究还有助于开发更智能的视频编辑工具,实现自动化的视频特效和内容生成。
📄 摘要(原文)
This paper addresses the challenge of learning semantically and functionally meaningful 3D motion priors from real-world videos, in order to enable prediction of future 3D scene motion from a single input image. We propose a novel pixel-aligned Motion Map (MoMap) representation for 3D scene motion, which can be generated from existing generative image models to facilitate efficient and effective motion prediction. To learn meaningful distributions over motion, we create a large-scale database of MoMaps from over 50,000 real videos and train a diffusion model on these representations. Our motion generation not only synthesizes trajectories in 3D but also suggests a new pipeline for 2D video synthesis: first generate a MoMap, then warp an image accordingly and complete the warped point-based renderings. Experimental results demonstrate that our approach generates plausible and semantically consistent 3D scene motion.