CoDefend: Cross-Modal Collaborative Defense via Diffusion Purification and Prompt Optimization
作者: Fengling Zhu, Boshi Liu, Jingyu Hua, Sheng Zhong
分类: cs.CV
发布日期: 2025-10-13
💡 一句话要点
提出CoDefend,通过扩散模型净化和Prompt优化协同防御多模态大模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 对抗防御 扩散模型 图像净化 Prompt优化
📋 核心要点
- 多模态大模型易受对抗攻击,现有防御方法(如对抗训练和输入净化)存在计算成本高、泛化性差等问题。
- CoDefend提出基于监督扩散的去噪框架,利用配对数据微调扩散模型,并结合Prompt优化,增强防御能力。
- 实验表明,CoDefend显著提高了多模态任务的鲁棒性,并对未知攻击表现出良好的迁移性。
📝 摘要(中文)
多模态大型语言模型(MLLM)通过整合视觉和文本模态,在图像描述、视觉问答和跨模态推理等任务中取得了显著成功。然而,其多模态特性也使其容易受到对抗性威胁,攻击者可以扰动其中一个或两个模态,从而诱导产生有害、误导或违反策略的输出。现有的防御策略,如对抗训练和输入净化,面临着显著的局限性:对抗训练通常只提高对已知攻击的鲁棒性,同时产生高昂的计算成本,而传统的净化方法通常会降低图像质量,并且对复杂的多模态任务泛化性不足。本文侧重于防御视觉模态,因为视觉模态经常作为对抗性操纵的主要入口点。我们提出了一个基于监督扩散的去噪框架,该框架利用配对的对抗性干净图像数据集,通过定向的、特定于任务的指导来微调扩散模型。与之前的无监督净化方法(如DiffPure)不同,我们的方法实现了更高质量的重建,同时显著提高了多模态任务中的防御鲁棒性。此外,我们结合了Prompt优化作为一种补充防御机制,增强了对各种未知攻击策略的抵抗力。在图像描述和视觉问答上的大量实验表明,我们的方法不仅显著提高了鲁棒性,而且对未知的对抗性攻击表现出很强的可迁移性。这些结果突出了基于监督扩散的去噪对于多模态防御的有效性,为在现实世界应用中更可靠和安全地部署MLLM铺平了道路。
🔬 方法详解
问题定义:多模态大模型容易受到对抗攻击,攻击者可以通过对图像等视觉模态进行微小扰动,导致模型产生错误的输出。现有的防御方法,如对抗训练,计算成本高昂,且只能防御已知的攻击类型。而传统的图像净化方法,如DiffPure,在提高鲁棒性的同时,会降低图像质量,且在复杂的多模态任务中泛化能力不足。
核心思路:CoDefend的核心思路是利用监督扩散模型进行图像去噪,并结合Prompt优化来增强模型的鲁棒性。通过使用配对的对抗样本和干净样本进行训练,扩散模型可以学习到如何有效地去除对抗扰动,恢复原始图像。同时,Prompt优化可以进一步提高模型对各种攻击的抵抗能力。
技术框架:CoDefend主要包含两个阶段:基于监督扩散的图像净化和Prompt优化。在图像净化阶段,使用配对的对抗样本和干净样本训练扩散模型,使其能够将对抗样本还原为干净样本。在Prompt优化阶段,通过调整输入Prompt,进一步提高模型对对抗攻击的抵抗能力。整体流程是:对抗样本首先经过扩散模型进行净化,然后将净化后的图像和优化的Prompt输入到多模态大模型中,得到最终的输出。
关键创新:CoDefend的关键创新在于使用了监督扩散模型进行图像净化。与传统的无监督净化方法相比,监督扩散模型可以更好地学习到对抗扰动的特征,从而实现更高质量的图像重建和更强的防御能力。此外,结合Prompt优化,进一步提高了模型对各种攻击的抵抗能力。
关键设计:在扩散模型方面,使用了DDPM(Denoising Diffusion Probabilistic Models)作为基础模型,并使用配对的对抗样本和干净样本进行微调。损失函数包括重建损失和对抗损失,以确保模型能够有效地去除对抗扰动。在Prompt优化方面,使用了梯度下降法来调整Prompt,目标是最小化模型在对抗样本上的损失。
🖼️ 关键图片

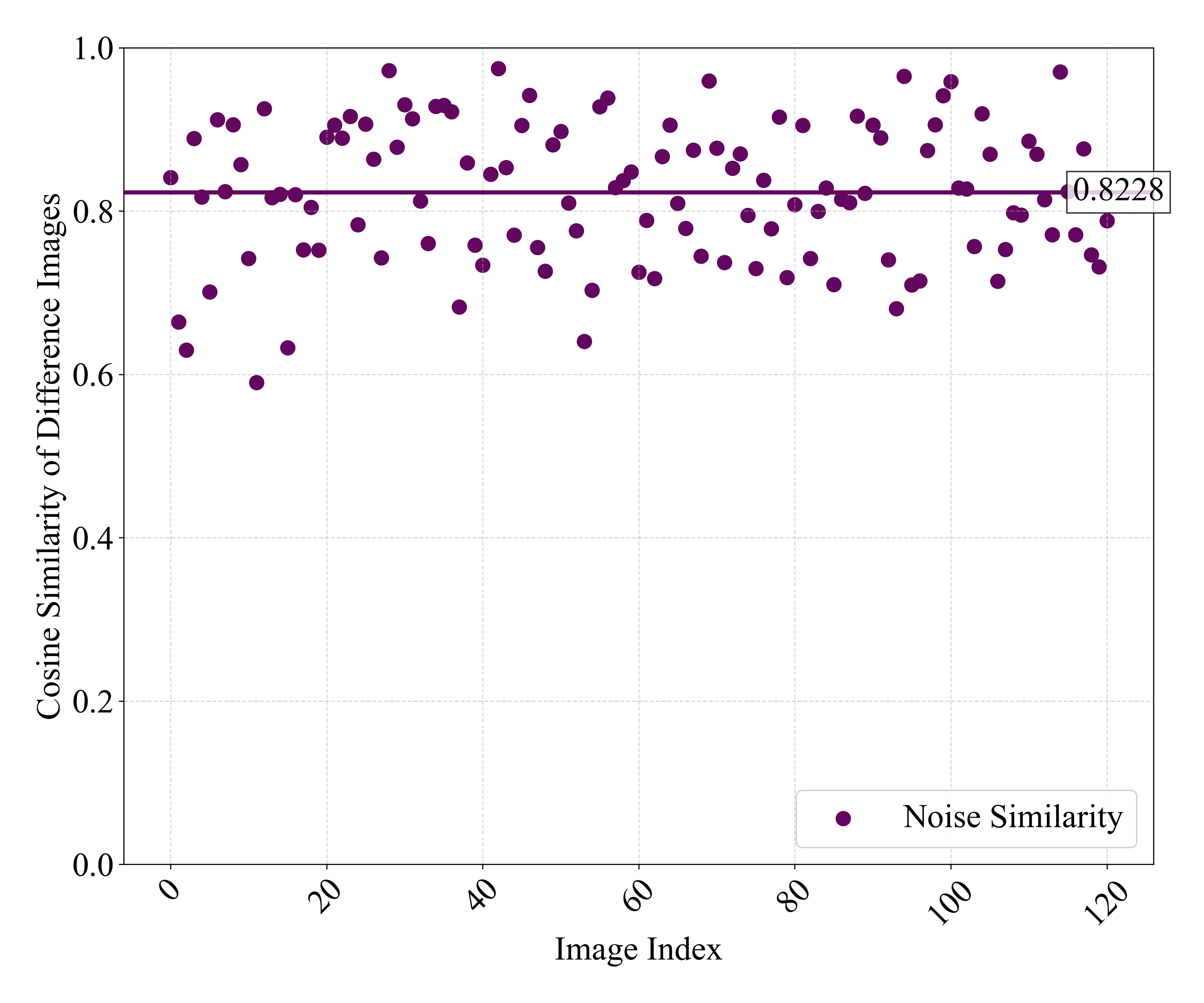
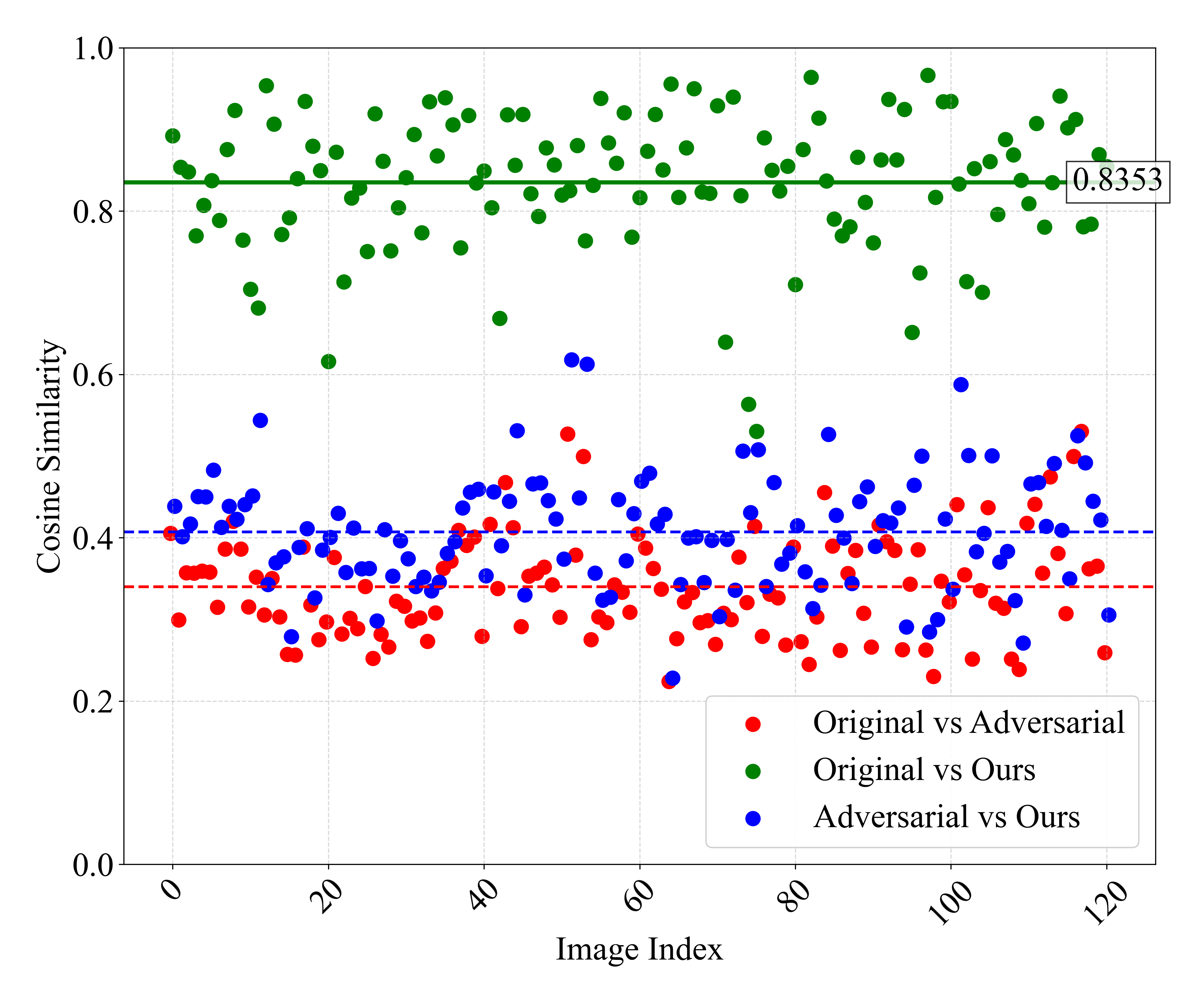
📊 实验亮点
实验结果表明,CoDefend在图像描述和视觉问答任务中显著提高了模型的鲁棒性。例如,在对抗攻击下,CoDefend可以将模型的准确率提高到接近干净样本的水平,并且对未知的对抗攻击表现出良好的迁移性。与现有的防御方法相比,CoDefend在鲁棒性和图像质量方面都取得了更好的平衡。
🎯 应用场景
CoDefend可应用于各种需要安全可靠的多模态大模型的场景,例如自动驾驶、医疗诊断、智能安防等。通过提高模型对对抗攻击的鲁棒性,可以避免因恶意攻击导致的安全事故和经济损失,保障系统的稳定运行和用户的利益。该研究为多模态大模型的安全部署提供了新的思路和方法。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved remarkable success in tasks such as image captioning, visual question answering, and cross-modal reasoning by integrating visual and textual modalities. However, their multimodal nature also exposes them to adversarial threats, where attackers can perturb either modality or both jointly to induce harmful, misleading, or policy violating outputs. Existing defense strategies, such as adversarial training and input purification, face notable limitations: adversarial training typically improves robustness only against known attacks while incurring high computational costs, whereas conventional purification approaches often suffer from degraded image quality and insufficient generalization to complex multimodal tasks. In this work, we focus on defending the visual modality, which frequently serves as the primary entry point for adversarial manipulation. We propose a supervised diffusion based denoising framework that leverages paired adversarial clean image datasets to fine-tune diffusion models with directional, task specific guidance. Unlike prior unsupervised purification methods such as DiffPure, our approach achieves higher quality reconstructions while significantly improving defense robustness in multimodal tasks. Furthermore, we incorporate prompt optimization as a complementary defense mechanism, enhancing resistance against diverse and unseen attack strategies. Extensive experiments on image captioning and visual question answering demonstrate that our method not only substantially improves robustness but also exhibits strong transferability to unknown adversarial attacks. These results highlight the effectiveness of supervised diffusion based denoising for multimodal defense, paving the way for more reliable and secure deployment of MLLMs in real world applications.