Vlaser: Vision-Language-Action Model with Synergistic Embodied Reasoning
作者: Ganlin Yang, Tianyi Zhang, Haoran Hao, Weiyun Wang, Yibin Liu, Dehui Wang, Guanzhou Chen, Zijian Cai, Junting Chen, Weijie Su, Wengang Zhou, Yu Qiao, Jifeng Dai, Jiangmiao Pang, Gen Luo, Wenhai Wang, Yao Mu, Zhi Hou
分类: cs.CV
发布日期: 2025-10-13 (更新: 2026-01-27)
💡 一句话要点
提出Vlaser,通过协同具身推理弥合VLM推理与VLA策略学习的鸿沟。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 具身推理 机器人控制 领域自适应 Transformer
📋 核心要点
- 现有方法未能有效衔接VLM推理与VLA策略学习,阻碍了端到端机器人控制的发展。
- Vlaser通过协同具身推理,将高层次的视觉语言推理与低层次的机器人控制相结合。
- Vlaser在多个具身推理任务上达到SOTA,并在机器人控制基准测试中表现出色。
📝 摘要(中文)
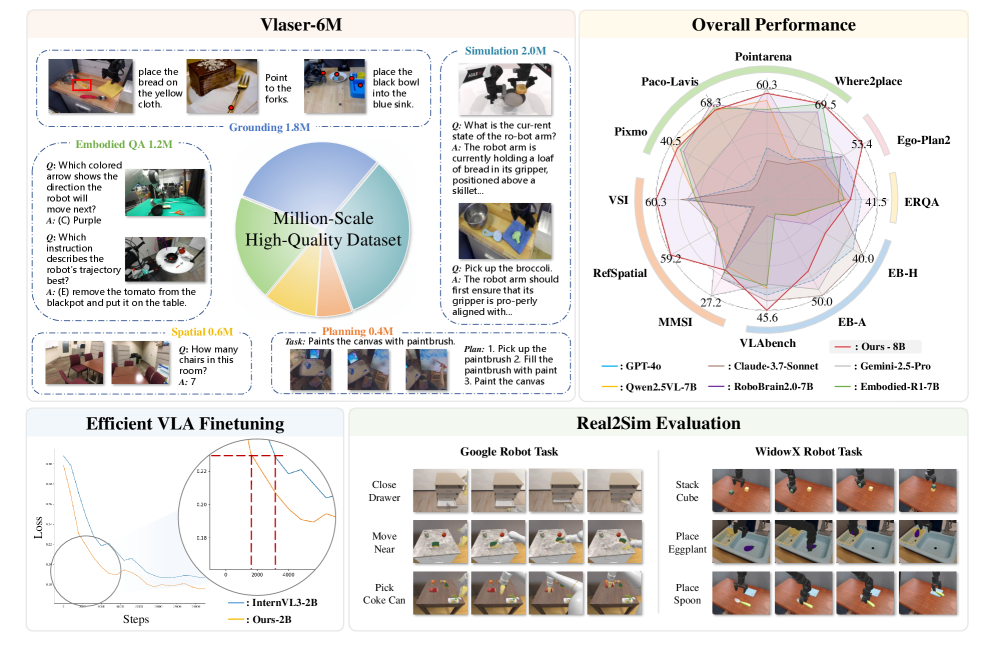
本文旨在弥合基于视觉-语言模型(VLM)的推理与视觉-语言-动作(VLA)策略学习之间的关键差距,提出了Vlaser,一个具有协同具身推理能力的视觉-语言-动作模型。Vlaser是一个基础的视觉-语言模型,旨在将高层次推理与具身智能体的低层次控制相结合。基于高质量的Vlaser-6M数据集,Vlaser在一系列具身推理基准测试中取得了最先进的性能,包括空间推理、具身定位、具身问答和任务规划。此外,本文系统地研究了不同的VLM初始化如何影响监督VLA微调,为缓解互联网规模预训练数据与具身特定策略学习数据之间的领域转移提供了新的见解。基于这些见解,该方法在WidowX基准测试中取得了最先进的结果,并在Google Robot基准测试中取得了具有竞争力的性能。
🔬 方法详解
问题定义:现有方法在将预训练的视觉-语言模型(VLM)应用于机器人控制时,往往忽略了VLM推理与VLA策略学习之间的gap。直接将VLM应用于VLA任务会导致性能下降,因为互联网规模的预训练数据与机器人控制所需的具身环境数据存在显著的领域差异。因此,如何有效地利用VLM的推理能力来指导VLA策略学习是一个关键问题。
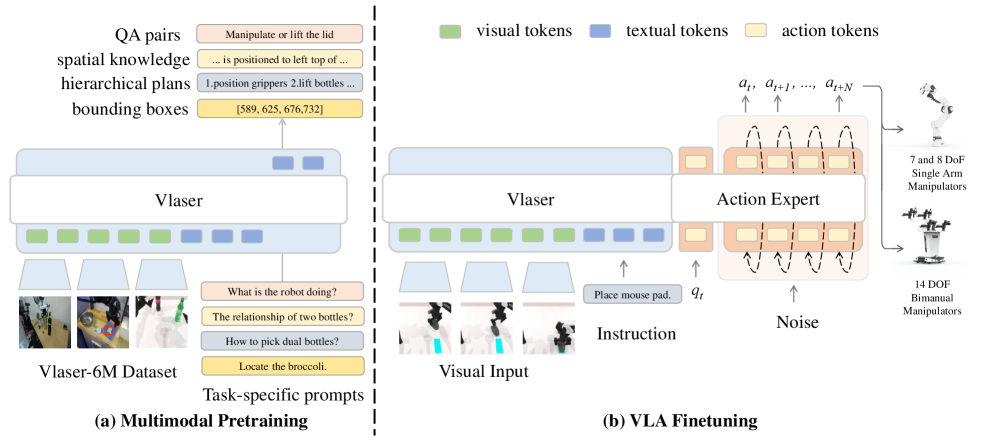
核心思路:Vlaser的核心思路是构建一个能够进行协同具身推理的VLA模型,从而弥合VLM推理与VLA策略学习之间的鸿沟。具体来说,Vlaser通过一个统一的框架,将高层次的视觉-语言推理与低层次的机器人控制相结合,使得模型能够更好地理解环境,并做出相应的动作。
技术框架:Vlaser的整体架构包含视觉编码器、语言编码器、动作解码器以及一个协同推理模块。视觉编码器负责提取环境的视觉特征,语言编码器负责理解用户的指令,动作解码器负责生成机器人的控制指令。协同推理模块则负责将视觉特征、语言指令和历史动作信息进行融合,从而进行高层次的推理和决策。整个流程是端到端可训练的。
关键创新:Vlaser的关键创新在于其协同具身推理能力。传统的VLA模型通常只关注低层次的控制,而忽略了高层次的推理。Vlaser通过引入协同推理模块,使得模型能够更好地理解环境和用户的意图,从而做出更合理的动作。此外,Vlaser还提出了一个Vlaser-6M数据集,用于训练和评估模型的具身推理能力。
关键设计:Vlaser的关键设计包括:1)使用Transformer作为视觉和语言编码器的骨干网络;2)设计了一个多模态融合模块,用于融合视觉、语言和动作信息;3)采用了一种基于强化学习的训练方法,用于优化模型的策略;4)Vlaser-6M数据集包含了大量的具身推理场景,用于训练和评估模型的性能。
🖼️ 关键图片

📊 实验亮点
Vlaser在多个具身推理基准测试中取得了最先进的性能,包括空间推理、具身定位、具身问答和任务规划。在WidowX基准测试中,Vlaser取得了SOTA结果,并在Google Robot基准测试中取得了具有竞争力的性能。此外,论文还深入研究了不同VLM初始化对VLA微调的影响,为缓解领域偏移提供了新的见解。
🎯 应用场景
Vlaser具有广泛的应用前景,可应用于家庭服务机器人、工业自动化、医疗辅助等领域。例如,在家庭环境中,Vlaser可以帮助机器人理解用户的指令,完成诸如清洁、整理等任务。在工业自动化领域,Vlaser可以帮助机器人进行复杂的装配和检测工作。在医疗辅助领域,Vlaser可以帮助医生进行远程手术和康复训练。Vlaser的出现将极大地提高机器人的智能化水平,并为人类带来更多的便利。
📄 摘要(原文)
While significant research has focused on developing embodied reasoning capabilities using Vision-Language Models (VLMs) or integrating advanced VLMs into Vision-Language-Action (VLA) models for end-to-end robot control, few studies directly address the critical gap between upstream VLM-based reasoning and downstream VLA policy learning. In this work, we take an initial step toward bridging embodied reasoning with VLA policy learning by introducing Vlaser - a Vision-Language-Action Model with synergistic embodied reasoning capability, which is a foundational vision-language model designed to integrate high-level reasoning with low-level control for embodied agents. Built upon the high-quality Vlaser-6M dataset, Vlaser achieves state-of-the-art performance across a range of embodied reasoning benchmarks - including spatial reasoning, embodied grounding, embodied QA, and task planning. Furthermore, we systematically examine how different VLM initializations affect supervised VLA fine-tuning, offering novel insights into mitigating the domain shift between internet-scale pre-training data and embodied-specific policy learning data. Based on these insights, our approach achieves state-of-the-art results on the WidowX benchmark and competitive performance on the Google Robot benchmark.