COCO-Tree: Compositional Hierarchical Concept Trees for Enhanced Reasoning in Vision Language Models
作者: Sanchit Sinha, Guangzhi Xiong, Aidong Zhang
分类: cs.CV
发布日期: 2025-10-13
备注: EMNLP 2025 (main)
💡 一句话要点
提出COCO-Tree,利用神经符号概念树增强视觉语言模型中的组合推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 组合推理 神经符号推理 概念树 大型语言模型
📋 核心要点
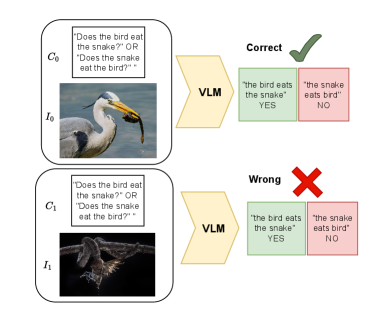
- 现有VLM在理解图像中对象、属性和关系交互的组合推理方面存在不足。
- COCO-Tree利用LLM学习的神经符号概念树增强VLM输出,提升语言推理能力。
- 实验表明,COCO-Tree在多个组合性基准测试中,性能比基线方法提升5-10%。
📝 摘要(中文)
现代视觉语言模型(VLM)在组合推理方面存在不足,难以理解图像中多个对象、属性和关系之间的交互。现有研究尝试通过改进提示结构、思维链推理等技巧来提升组合性性能。最近的研究倾向于利用训练有素的大型语言模型(LLM)来增强VLM的推理能力,以弥补VLM在语言理解方面的不足。然而,这些方法要么资源密集,要么无法提供可解释的推理过程。本文提出'COCO-Tree',一种新颖的方法,通过精心设计的、从LLM学习的神经符号概念树来增强VLM的输出,从而提高VLM的语言推理能力。COCO-Tree的受束搜索启发的推理过程提升了组合性性能,并提供了VLM预测背后的理由。在Winoground、EqBench、ColorSwap和SugarCrepe四个组合性基准测试中,对七个不同规模的开源VLM的实验结果表明,COCO-Tree在组合泛化方面比基线方法显著提高了5-10%。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)在组合推理方面的不足。现有方法,如改进prompt或利用大型语言模型(LLM),存在资源密集或缺乏可解释性的问题。VLM难以理解图像中多个对象、属性和关系之间的复杂交互,限制了其在需要组合理解的任务中的应用。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语言理解能力,生成神经符号概念树,以此来增强VLM的推理过程。通过将VLM的输出与概念树结合,COCO-Tree能够提供更结构化和可解释的推理路径,从而提升组合推理的性能。这种方法旨在弥补VLM在语言理解方面的不足,同时避免直接使用LLM进行推理带来的资源消耗。
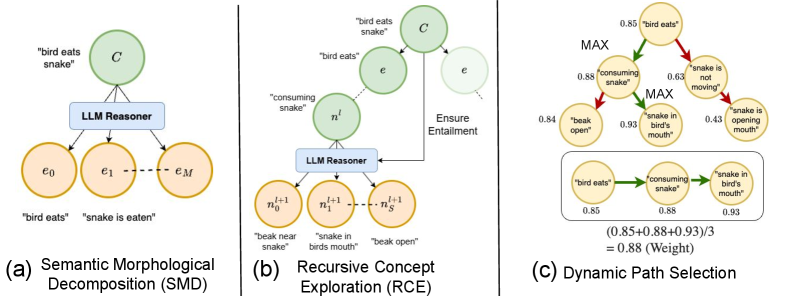
技术框架:COCO-Tree的整体框架包含以下几个主要阶段:1) VLM生成初始预测和相关信息;2) 利用LLM基于VLM的输出构建神经符号概念树,该树表示对象、属性和关系之间的层次结构;3) 使用受束搜索启发的推理过程,在概念树中搜索最佳推理路径;4) 基于最佳推理路径,修正VLM的初始预测。整个过程旨在提供一个可解释的推理链,并提高组合推理的准确性。
关键创新:COCO-Tree的关键创新在于其神经符号概念树的构建和利用方式。与传统的符号推理方法不同,COCO-Tree的概念树是从LLM中学习得到的,能够更好地适应自然语言的复杂性和模糊性。此外,受束搜索启发的推理过程允许模型探索多个可能的推理路径,从而提高鲁棒性。这种方法结合了神经模型的灵活性和符号推理的可解释性,为解决组合推理问题提供了一种新的思路。
关键设计:COCO-Tree的关键设计包括:1) 使用特定的prompt工程来指导LLM生成高质量的概念树;2) 设计合适的评分函数来评估概念树中不同推理路径的质量,该评分函数可能涉及到VLM的置信度、LLM的语言流畅度等因素;3) 采用束搜索算法来平衡搜索效率和推理质量。具体的参数设置和网络结构细节可能需要根据不同的VLM和LLM进行调整。
🖼️ 关键图片
📊 实验亮点
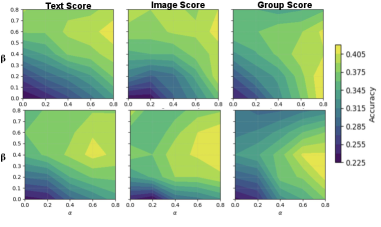
实验结果表明,COCO-Tree在Winoground、EqBench、ColorSwap和SugarCrepe四个组合性基准测试中,对七个不同规模的开源VLM进行了评估,性能比基线方法显著提高了5-10%。这些结果验证了COCO-Tree在提升组合泛化能力方面的有效性,并表明该方法具有良好的通用性和可扩展性。
🎯 应用场景
COCO-Tree可应用于需要复杂组合推理的视觉语言任务,例如图像描述生成、视觉问答、场景理解等。该方法能够提升模型在处理涉及多对象、多属性和复杂关系的场景时的性能,具有广泛的应用前景。未来,COCO-Tree可以进一步扩展到机器人导航、智能助手等领域,提升AI系统的理解和推理能力。
📄 摘要(原文)
Compositional reasoning remains a persistent weakness of modern vision language models (VLMs): they often falter when a task hinges on understanding how multiple objects, attributes, and relations interact within an image. Multiple research works have attempted to improve compositionality performance by creative tricks such as improving prompt structure, chain of thought reasoning, etc. A more recent line of work attempts to impart additional reasoning in VLMs using well-trained Large Language Models (LLMs), which are far superior in linguistic understanding than VLMs to compensate for the limited linguistic prowess of VLMs. However, these approaches are either resource-intensive or do not provide an interpretable reasoning process. In this paper, we present 'COCO-Tree' - a novel approach that augments VLM outputs with carefully designed neurosymbolic concept trees learned from LLMs to improve VLM's linguistic reasoning. COCO-Tree's beam search-inspired reasoning process boosts compositionality performance and provides a rationale behind VLM predictions. Empirical results on four compositionality benchmarks, Winoground, EqBench, ColorSwap, and SugarCrepe, in seven different open-source VLMs with varying sizes, demonstrate that COCO-Tree significantly improves compositional generalization by 5-10% over baselines.