DKPMV: Dense Keypoints Fusion from Multi-View RGB Frames for 6D Pose Estimation of Textureless Objects
作者: Jiahong Chen, Jinghao Wang, Zi Wang, Ziwen Wang, Banglei Guan, Qifeng Yu
分类: cs.CV, cs.RO
发布日期: 2025-10-13
备注: 12 pages, 9 figures, submitted to ICRA 2026
💡 一句话要点
DKPMV:基于多视角RGB图像的稠密关键点融合,用于无纹理物体6D位姿估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6D位姿估计 无纹理物体 多视角RGB 稠密关键点融合 注意力机制 对称感知训练 工业机器人
📋 核心要点
- 现有方法在无纹理物体6D位姿估计中,依赖深度信息或未能充分利用多视角几何信息,导致性能受限。
- DKPMV通过多视角RGB图像进行稠密关键点融合,并设计三阶段渐进式位姿优化策略,有效利用多视角几何信息。
- 实验表明,DKPMV在ROBI数据集上超越了现有最佳多视角RGB方法,并在多数情况下优于RGB-D方法。
📝 摘要(中文)
本文提出了一种名为DKPMV的流程,仅使用多视角RGB图像作为输入,实现稠密关键点级别的融合,用于无纹理物体的6D位姿估计。由于深度信息的缺失,无纹理物体的6D位姿估计极具挑战性。现有的多视角方法要么依赖于深度数据,要么对多视角几何线索的利用不足,限制了它们的性能。DKPMV设计了一个三阶段的渐进式位姿优化策略,利用稠密的多视角关键点几何信息。为了实现有效的稠密关键点融合,我们通过注意力机制聚合和对称感知训练来增强关键点网络,提高预测精度并解决对称物体的模糊性。在ROBI数据集上的大量实验表明,DKPMV优于最先进的多视角RGB方法,甚至在大多数情况下超过了RGB-D方法。代码即将开源。
🔬 方法详解
问题定义:论文旨在解决无纹理物体的6D位姿估计问题,尤其是在深度信息缺失的情况下。现有方法要么依赖深度数据,这限制了其在仅有RGB图像场景下的应用;要么未能充分利用多视角RGB图像提供的几何信息,导致位姿估计精度不高。因此,如何仅利用多视角RGB图像实现精确的6D位姿估计是一个关键挑战。
核心思路:论文的核心思路是利用多视角RGB图像提取稠密的关键点,并通过融合这些关键点的几何信息来优化物体的6D位姿。通过设计一个渐进式的位姿优化策略,逐步提高位姿估计的精度。此外,论文还通过注意力机制和对称感知训练来增强关键点网络的性能,使其能够更准确地预测关键点,并处理对称物体的模糊性。
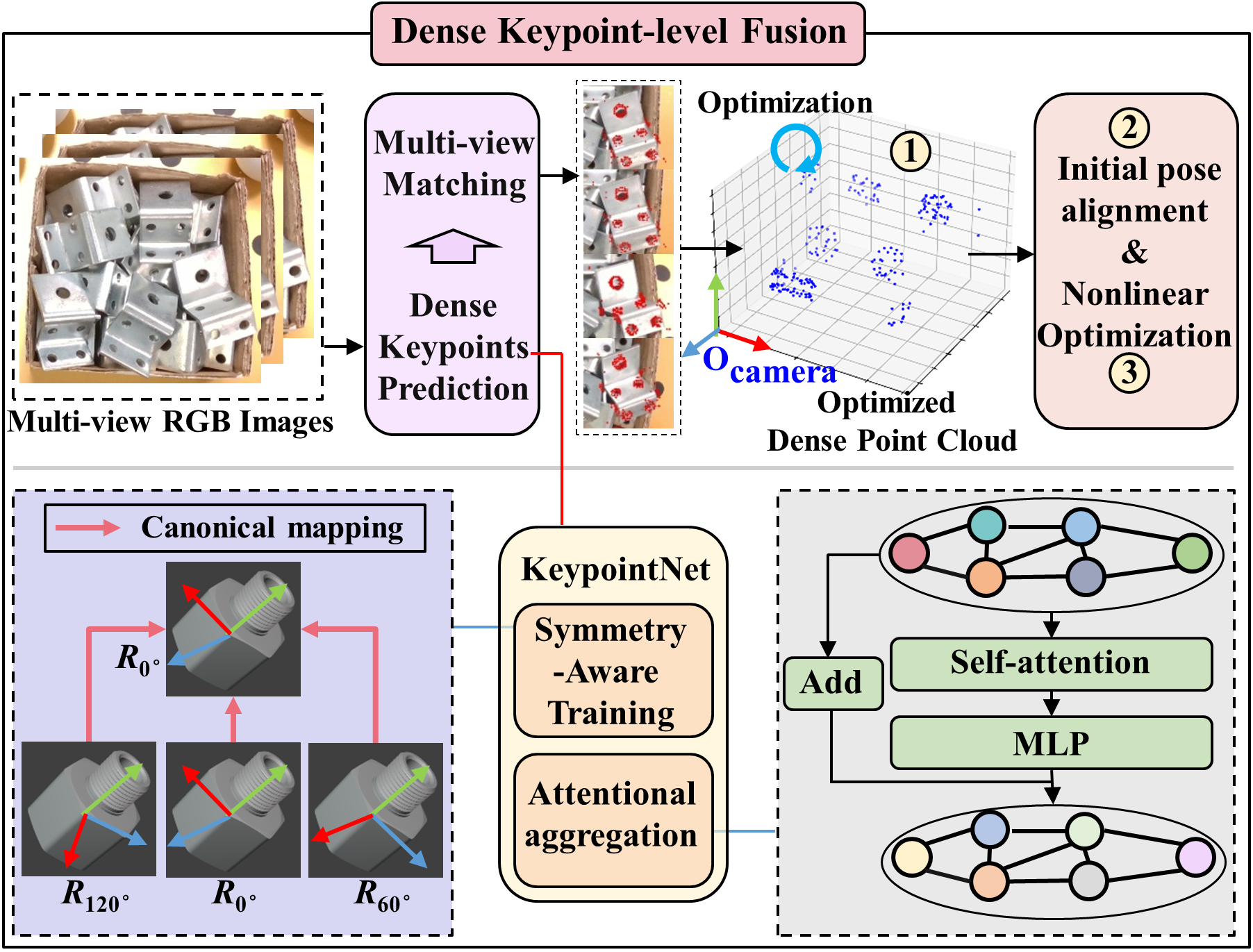
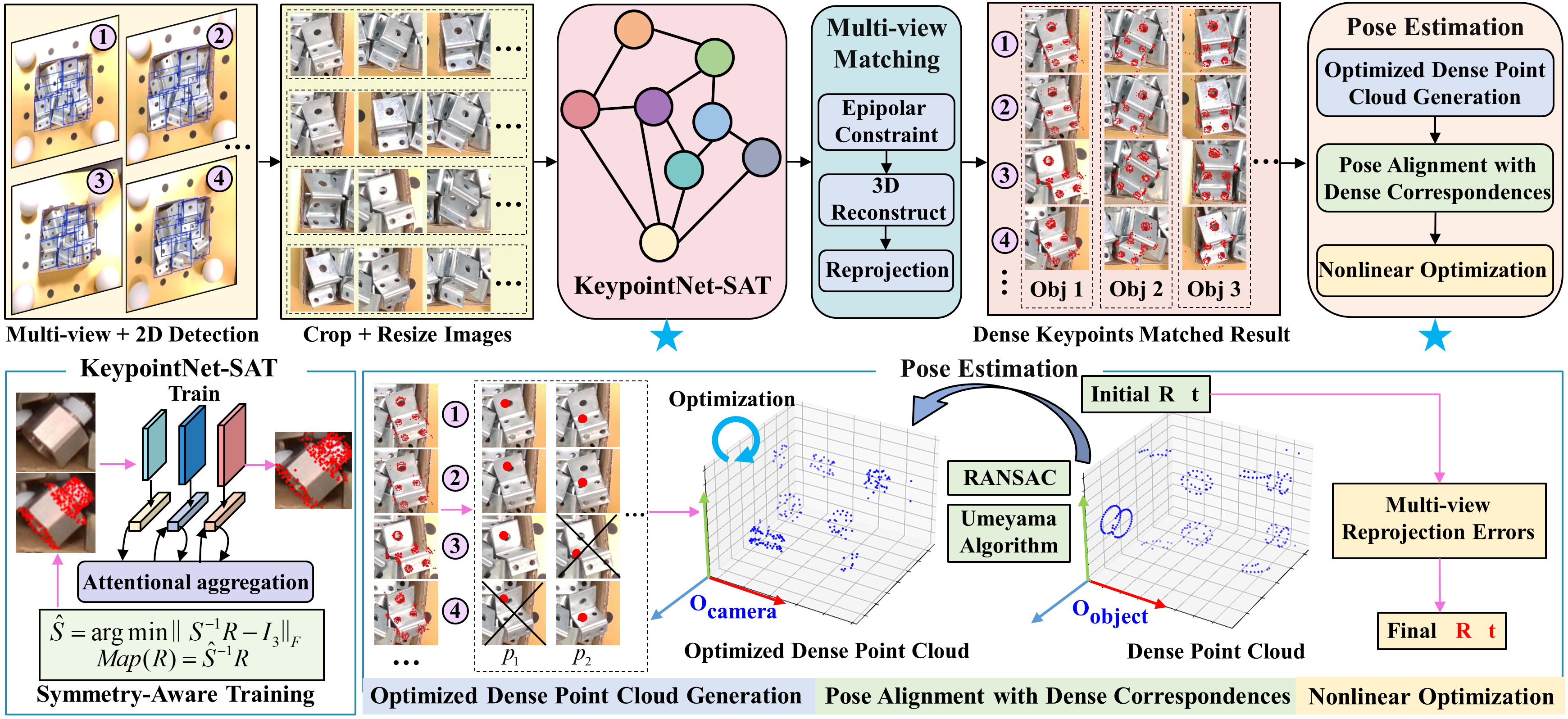
技术框架:DKPMV的整体框架包含三个主要阶段:1) 多视角关键点检测:使用改进的关键点网络从多个RGB图像中检测物体的关键点。2) 稠密关键点融合:利用多视角几何信息融合检测到的关键点,生成更准确的3D关键点位置。3) 渐进式位姿优化:通过三个阶段逐步优化物体的6D位姿,包括初始位姿估计、迭代最近点(ICP)优化和位姿细化。
关键创新:论文的关键创新在于:1) 提出了一个仅使用多视角RGB图像进行稠密关键点融合的框架,无需深度信息。2) 设计了一个三阶段的渐进式位姿优化策略,有效利用了多视角几何信息。3) 通过注意力机制聚合和对称感知训练增强了关键点网络,提高了关键点预测的准确性和鲁棒性。
关键设计:关键点网络采用了注意力机制来聚合不同视角的信息,从而提高关键点预测的准确性。对称感知训练通过引入对称损失函数,使得网络能够更好地处理对称物体的模糊性。渐进式位姿优化策略包括三个阶段:首先使用PnP算法进行初始位姿估计,然后使用ICP算法进行迭代优化,最后使用位姿细化网络进一步提高位姿精度。损失函数包括关键点预测损失、对称损失和位姿损失。
🖼️ 关键图片

📊 实验亮点
DKPMV在ROBI数据集上取得了显著的性能提升。与最先进的多视角RGB方法相比,DKPMV在6D位姿估计精度上取得了明显的优势,甚至在大多数情况下超过了RGB-D方法。例如,在某些测试场景下,DKPMV的位姿估计精度提高了5%以上。这些实验结果充分证明了DKPMV在无纹理物体6D位姿估计方面的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于工业机器人领域,例如在自动化装配、质量检测和物料搬运等任务中,机器人可以利用多视角RGB图像准确估计无纹理物体的6D位姿,从而实现精确的操作和控制。此外,该技术还可应用于增强现实、虚拟现实等领域,为用户提供更真实的交互体验。未来,该技术有望进一步拓展到自动驾驶、医疗影像分析等领域。
📄 摘要(原文)
6D pose estimation of textureless objects is valuable for industrial robotic applications, yet remains challenging due to the frequent loss of depth information. Current multi-view methods either rely on depth data or insufficiently exploit multi-view geometric cues, limiting their performance. In this paper, we propose DKPMV, a pipeline that achieves dense keypoint-level fusion using only multi-view RGB images as input. We design a three-stage progressive pose optimization strategy that leverages dense multi-view keypoint geometry information. To enable effective dense keypoint fusion, we enhance the keypoint network with attentional aggregation and symmetry-aware training, improving prediction accuracy and resolving ambiguities on symmetric objects. Extensive experiments on the ROBI dataset demonstrate that DKPMV outperforms state-of-the-art multi-view RGB approaches and even surpasses the RGB-D methods in the majority of cases. The code will be available soon.