FG-CLIP 2: A Bilingual Fine-grained Vision-Language Alignment Model
作者: Chunyu Xie, Bin Wang, Fanjing Kong, Jincheng Li, Dawei Liang, Ji Ao, Dawei Leng, Yuhui Yin
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-10-13 (更新: 2025-10-17)
💡 一句话要点
提出FG-CLIP 2,用于提升英汉双语细粒度视觉-语言对齐能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 细粒度视觉语言对齐 双语模型 对比学习 区域文本匹配 长文本建模
📋 核心要点
- 现有视觉-语言模型在细粒度理解上存在不足,尤其是在非英语环境下,难以捕捉对象属性和空间关系等细节。
- FG-CLIP 2通过引入区域-文本匹配、长文本建模和文本内模态对比损失(TIC),增强模型对细粒度信息的理解和区分能力。
- 实验结果表明,FG-CLIP 2在多种任务和数据集上超越现有方法,并在英汉双语环境下均达到领先水平。
📝 摘要(中文)
当前模型在细粒度视觉-语言理解方面存在局限性,尤其是在非英语环境中。虽然像CLIP这样的模型在全局对齐方面表现良好,但它们在捕捉对象属性、空间关系和语言表达中的细粒度细节方面存在困难,并且对双语理解的支持有限。为了解决这些挑战,我们推出了FG-CLIP 2,这是一种旨在提升英语和中文细粒度对齐的双语视觉-语言模型。我们的方法利用丰富的细粒度监督,包括区域-文本匹配和长文本建模,以及多个判别性目标。我们进一步引入了文本内模态对比(TIC)损失,以更好地区分语义相似的文本描述。FG-CLIP 2在精心策划的大规模英语和中文数据混合集上进行训练,实现了强大的双语性能。为了实现严格的评估,我们提出了一个新的中文多模态理解基准,包括长文本检索和边界框分类。在8个任务的29个数据集上进行的大量实验表明,FG-CLIP 2优于现有方法,在两种语言中都取得了最先进的结果。我们发布了模型、代码和基准,以促进未来对双语细粒度对齐的研究。
🔬 方法详解
问题定义:现有视觉-语言模型,如CLIP,在全局对齐上表现良好,但在细粒度视觉-语言理解方面存在不足,尤其是在中文等非英语环境下。这些模型难以准确捕捉图像中对象属性、空间关系等细粒度信息,也难以区分语义相似的文本描述,限制了其在复杂场景下的应用。
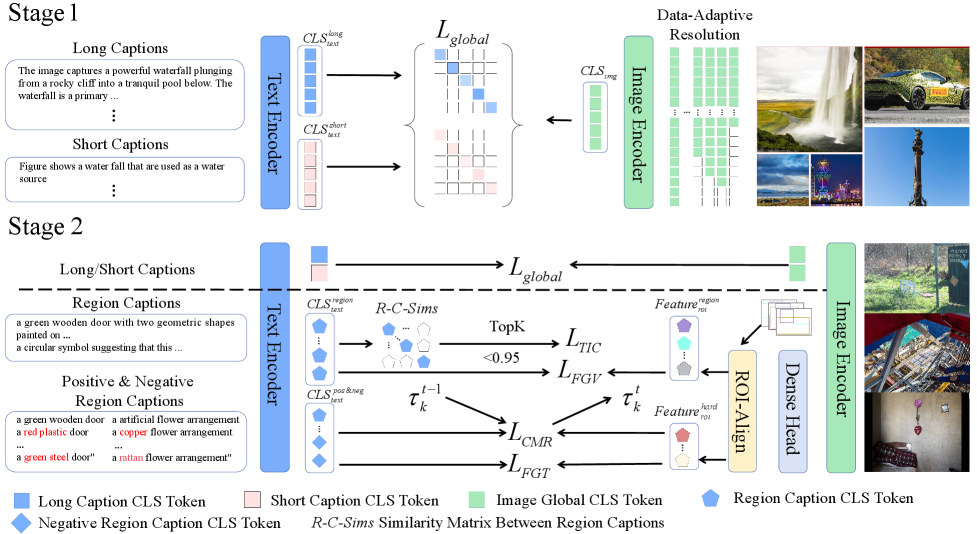
核心思路:FG-CLIP 2的核心思路是利用更丰富的细粒度监督信息,并设计专门的损失函数,来提升模型对图像和文本之间细粒度对应关系的理解能力。通过区域-文本匹配,模型能够学习图像局部区域与对应文本描述之间的关联;通过长文本建模,模型能够理解更复杂的场景描述;通过TIC损失,模型能够更好地区分语义相似的文本描述。
技术框架:FG-CLIP 2的整体框架基于CLIP模型,但进行了扩展和改进。主要包括以下模块:图像编码器、文本编码器、区域-文本匹配模块、长文本建模模块和对比学习模块。图像编码器和文本编码器负责将图像和文本转换为向量表示。区域-文本匹配模块负责学习图像局部区域与对应文本描述之间的关联。长文本建模模块负责处理复杂的场景描述。对比学习模块负责学习图像和文本之间的对齐关系。
关键创新:FG-CLIP 2的关键创新在于引入了文本内模态对比(TIC)损失。TIC损失旨在更好地区分语义相似的文本描述,从而提升模型对细微语义差异的感知能力。传统的对比学习方法通常只关注正样本和负样本之间的区分,而忽略了正样本内部的差异。TIC损失通过对比同一图像的不同文本描述,迫使模型学习更精细的语义表示。
关键设计:FG-CLIP 2的关键设计包括:1) 使用大规模英汉双语数据集进行训练,提升模型的跨语言能力;2) 引入区域-文本匹配损失,鼓励模型学习图像局部区域与对应文本描述之间的关联;3) 引入长文本建模模块,处理复杂的场景描述;4) 引入文本内模态对比(TIC)损失,更好地区分语义相似的文本描述;5) 构建新的中文多模态理解基准,用于评估模型在中文环境下的细粒度理解能力。
🖼️ 关键图片


📊 实验亮点
FG-CLIP 2在29个数据集上的8个任务中取得了最先进的结果,证明了其在细粒度视觉-语言理解方面的优越性。特别是在中文多模态理解基准上,FG-CLIP 2显著优于现有方法,验证了其在中文环境下的有效性。模型、代码和基准的发布将促进未来对双语细粒度对齐的研究。
🎯 应用场景
FG-CLIP 2在多个领域具有广泛的应用前景,例如图像检索、视觉问答、图像描述生成、细粒度图像分类等。该模型能够提升机器人在复杂环境下的感知和理解能力,促进智能客服、智能家居等领域的发展。此外,该模型在跨语言信息检索和机器翻译等领域也具有潜在的应用价值。
📄 摘要(原文)
Fine-grained vision-language understanding requires precise alignment between visual content and linguistic descriptions, a capability that remains limited in current models, particularly in non-English settings. While models like CLIP perform well on global alignment, they often struggle to capture fine-grained details in object attributes, spatial relations, and linguistic expressions, with limited support for bilingual comprehension. To address these challenges, we introduce FG-CLIP 2, a bilingual vision-language model designed to advance fine-grained alignment for both English and Chinese. Our approach leverages rich fine-grained supervision, including region-text matching and long-caption modeling, alongside multiple discriminative objectives. We further introduce the Textual Intra-modal Contrastive (TIC) loss to better distinguish semantically similar captions. Trained on a carefully curated mixture of large-scale English and Chinese data, FG-CLIP 2 achieves powerful bilingual performance. To enable rigorous evaluation, we present a new benchmark for Chinese multimodal understanding, featuring long-caption retrieval and bounding box classification. Extensive experiments on 29 datasets across 8 tasks show that FG-CLIP 2 outperforms existing methods, achieving state-of-the-art results in both languages. We release the model, code, and benchmark to facilitate future research on bilingual fine-grained alignment.