DEMO: Disentangled Motion Latent Flow Matching for Fine-Grained Controllable Talking Portrait Synthesis
作者: Peiyin Chen, Zhuowei Yang, Hui Feng, Sheng Jiang, Rui Yan
分类: cs.CV, cs.AI
发布日期: 2025-10-12
备注: 5 pages
💡 一句话要点
DEMO:解耦运动潜在流匹配,实现细粒度可控的说话人像合成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 说话人像生成 音频驱动 运动解耦 流匹配 Transformer 最优传输 视频合成
📋 核心要点
- 现有音频驱动的说话人像生成方法难以实现对视频中细粒度运动的精确控制,尤其是在保持时间一致性方面面临挑战。
- DEMO通过运动自编码器构建解耦的运动潜在空间,并结合最优传输流匹配和Transformer预测器,生成平滑且可控的运动轨迹。
- 实验结果表明,DEMO在视频真实感、唇音同步和运动保真度方面均优于现有方法,证明了其有效性。
📝 摘要(中文)
音频驱动的说话人像生成技术在扩散模型推动下迅速发展,但生成具有时间一致性和细粒度运动控制的视频仍然具有挑战性。我们提出了DEMO,一个基于流匹配的生成框架,用于音频驱动的说话人像视频合成,能够实现对唇部运动、头部姿势和眼神的解耦和高保真控制。核心贡献在于一个运动自编码器,它构建了一个结构化的潜在空间,其中运动因素被独立表示并近似正交化。在这个解耦的运动空间上,我们应用基于最优传输的流匹配,并使用Transformer预测器生成以音频为条件的、时间上平滑的运动轨迹。在多个基准测试上的大量实验表明,DEMO在视频真实感、唇音同步和运动保真度方面优于现有方法。这些结果表明,将细粒度的运动解耦与基于流的生成建模相结合,为可控的说话人像视频合成提供了一种强大的新范式。
🔬 方法详解
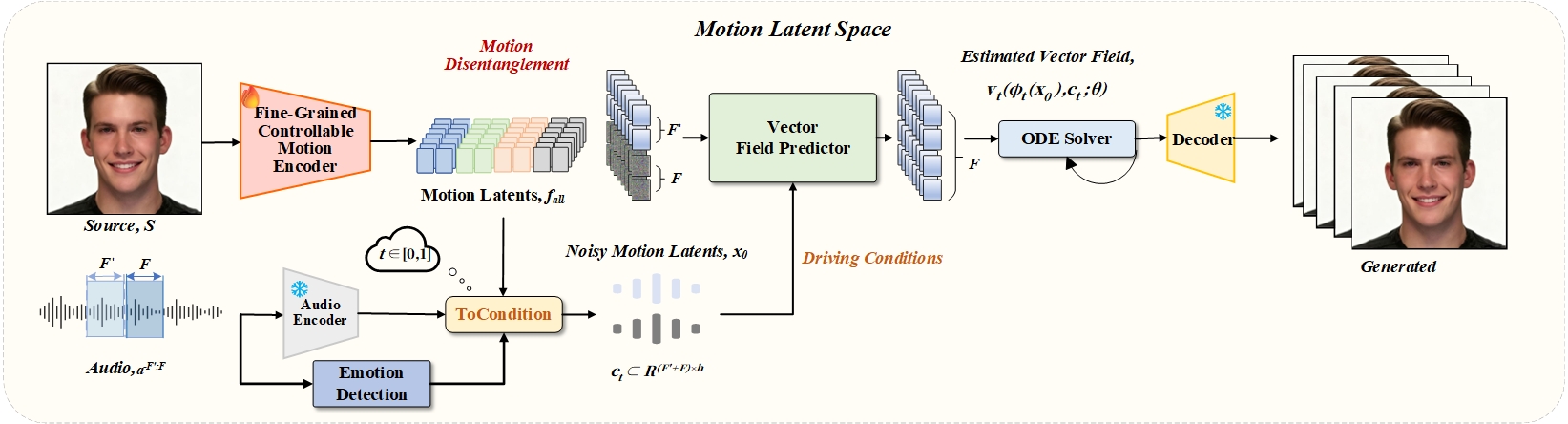
问题定义:论文旨在解决音频驱动的说话人像生成中,难以实现细粒度运动控制和时间一致性的问题。现有方法通常难以对唇部运动、头部姿势和眼神等运动因素进行独立控制,并且生成的视频在时间上可能出现不连贯的现象。
核心思路:论文的核心思路是将运动因素解耦到一个结构化的潜在空间中,然后利用流匹配模型学习从音频到解耦运动轨迹的映射。通过解耦运动因素,可以实现对每个因素的独立控制。流匹配模型能够生成时间上平滑的运动轨迹,从而保证视频的时间一致性。
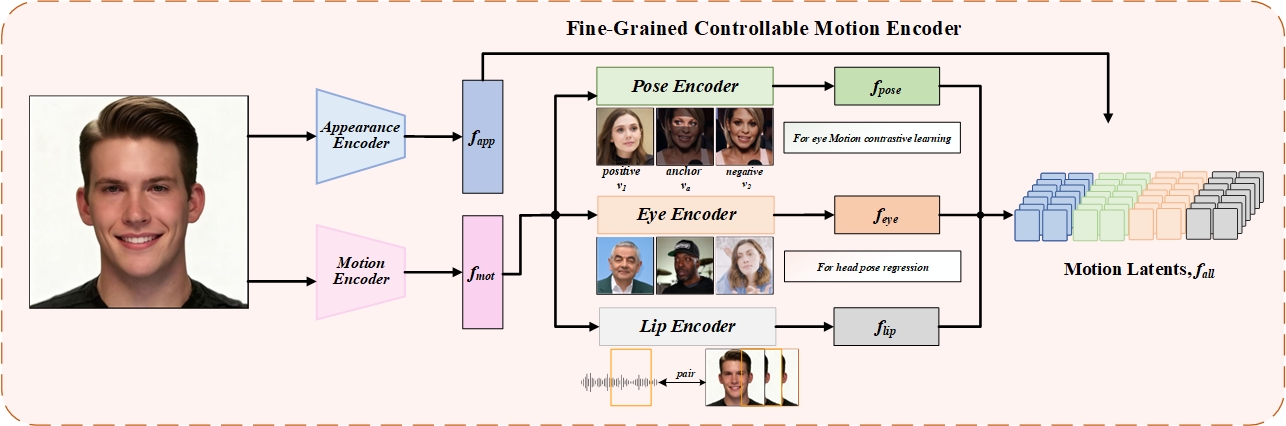
技术框架:DEMO框架主要包含两个阶段:运动自编码器训练阶段和流匹配生成阶段。在运动自编码器训练阶段,使用一个自编码器将视频帧编码到潜在空间中,并设计损失函数来鼓励潜在空间中运动因素的解耦。在流匹配生成阶段,使用一个Transformer预测器来预测以音频为条件的运动轨迹,然后使用流匹配模型将预测的运动轨迹映射到视频帧。
关键创新:该论文的关键创新在于提出了一个解耦的运动潜在空间,并将其与流匹配模型相结合。运动自编码器能够将运动因素解耦到独立的潜在维度中,从而实现对每个因素的独立控制。流匹配模型能够学习从音频到运动轨迹的平滑映射,从而保证视频的时间一致性。
关键设计:运动自编码器使用VAE结构,并引入了对抗损失和互信息最小化损失来鼓励潜在空间的解耦。流匹配模型使用最优传输作为匹配目标,并使用Transformer作为预测器。损失函数包括流匹配损失、对抗损失和重构损失。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DEMO在多个基准测试中均优于现有方法。在视频真实感方面,DEMO的FID得分显著低于其他方法。在唇音同步方面,DEMO的LSE-D得分也优于其他方法。此外,DEMO还能够实现对运动因素的精细控制,例如独立调整头部姿势和眼神。
🎯 应用场景
该研究成果可应用于虚拟形象定制、视频会议、游戏开发、电影制作等领域。通过DEMO,用户可以根据音频输入,生成具有逼真表情和动作的说话人像视频,并对视频中的运动因素进行精细控制。这项技术有望提升人机交互的自然性和表现力,并为内容创作提供更多可能性。
📄 摘要(原文)
Audio-driven talking-head generation has advanced rapidly with diffusion-based generative models, yet producing temporally coherent videos with fine-grained motion control remains challenging. We propose DEMO, a flow-matching generative framework for audio-driven talking-portrait video synthesis that delivers disentangled, high-fidelity control of lip motion, head pose, and eye gaze. The core contribution is a motion auto-encoder that builds a structured latent space in which motion factors are independently represented and approximately orthogonalized. On this disentangled motion space, we apply optimal-transport-based flow matching with a transformer predictor to generate temporally smooth motion trajectories conditioned on audio. Extensive experiments across multiple benchmarks show that DEMO outperforms prior methods in video realism, lip-audio synchronization, and motion fidelity. These results demonstrate that combining fine-grained motion disentanglement with flow-based generative modeling provides a powerful new paradigm for controllable talking-head video synthesis.