A Simple and Better Baseline for Visual Grounding
作者: Jingchao Wang, Wenlong Zhang, Dingjiang Huang, Hong Wang, Yefeng Zheng
分类: cs.CV
发布日期: 2025-10-12
备注: ICME2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于特征选择的简单高效视觉定位基线FSVG,提升精度与效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 特征选择 多模态融合 语言引导 深度学习
📋 核心要点
- 现有视觉定位方法需在多尺度图像上迭代,并缓存特征,计算开销大。
- FSVG直接封装语言和视觉模态,并行利用语言指导视觉特征提取,无需迭代。
- FSVG通过特征选择机制,仅利用语言相关的视觉特征,加速预测并提升性能。
📝 摘要(中文)
视觉定位旨在预测文本描述所指定的目标物体的位置。针对该任务,最新的研究方向侧重于仅选择与语言相关的视觉区域进行目标定位,以减少计算开销。尽管取得了令人印象深刻的性能,但它需要在不同的图像尺度上迭代执行,并且每次迭代都需要将语言特征和视觉特征存储在缓存中,从而产生额外的开销。为了简化实现,本文提出了一种基于特征选择的简单而有效的视觉定位基线,称为FSVG。具体来说,我们直接将语言和视觉模态封装到一个整体网络架构中,无需复杂的迭代过程,并并行地利用语言作为指导,促进语言模态和视觉模态之间的交互,以提取有效的视觉特征。此外,为了降低计算成本,在视觉特征学习过程中,我们引入了一种基于相似度的特征选择机制,仅利用与语言相关的视觉特征进行更快的预测。在多个基准数据集上进行的大量实验全面证实,所提出的FSVG在精度和效率之间实现了比当前最先进方法更好的平衡。
🔬 方法详解
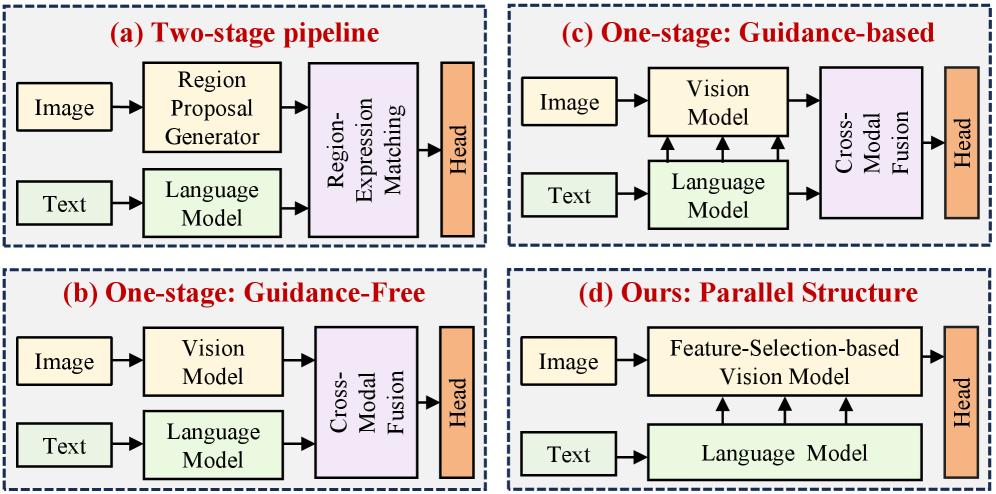
问题定义:视觉定位旨在根据给定的文本描述,在图像中找到对应目标物体的位置。现有方法,特别是那些基于特征选择的方法,虽然在精度上有所提升,但通常需要复杂的迭代过程,并在不同图像尺度上进行计算,导致计算开销显著增加,并且需要额外的缓存来存储中间特征,这限制了它们的实际应用。
核心思路:FSVG的核心思路是简化视觉定位流程,通过一个端到端的网络结构,直接将语言和视觉信息融合,避免了多尺度的迭代计算和特征缓存。它利用语言信息作为指导,在视觉特征提取过程中选择与语言相关的特征,从而减少计算量,同时保持甚至提升定位精度。
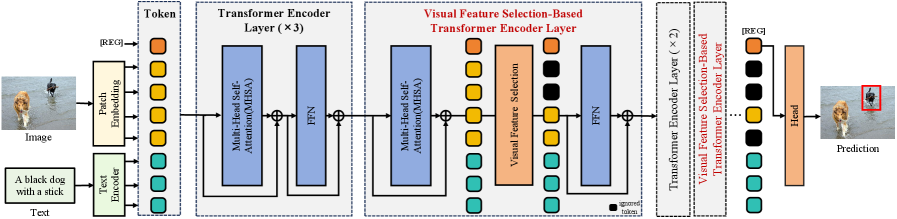
技术框架:FSVG的整体架构包含以下几个主要模块:1) 视觉特征提取模块:用于从输入图像中提取视觉特征。2) 语言特征提取模块:用于从文本描述中提取语言特征。3) 特征融合模块:将视觉特征和语言特征进行融合,实现跨模态的信息交互。4) 特征选择模块:根据语言特征,选择与语言相关的视觉特征。5) 定位预测模块:基于选择后的视觉特征,预测目标物体的位置。
关键创新:FSVG的关键创新在于其简单性和效率。它避免了复杂的迭代过程和特征缓存,而是通过一个端到端的网络结构,直接将语言和视觉信息融合。此外,它引入了基于相似度的特征选择机制,仅利用与语言相关的视觉特征进行预测,从而降低了计算成本,同时提高了定位精度。与现有方法相比,FSVG在精度和效率之间实现了更好的平衡。
关键设计:FSVG的关键设计包括:1) 并行处理语言和视觉信息,避免了串行处理带来的延迟。2) 使用相似度度量来选择与语言相关的视觉特征,例如余弦相似度。3) 损失函数的设计,可能包括定位损失(例如,IoU损失)和特征选择损失(例如,鼓励选择与语言更相关的特征)。4) 网络结构的选择,例如使用Transformer或CNN等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FSVG在多个基准数据集上取得了优异的性能,在精度和效率之间实现了更好的平衡。具体来说,FSVG在RefCOCO、RefCOCO+和G-Ref数据集上均取得了具有竞争力的结果,并且计算速度明显快于现有方法。代码已开源,方便研究人员复现和进一步研究。
🎯 应用场景
FSVG可应用于智能零售、自动驾驶、图像搜索、机器人导航等领域。例如,在智能零售中,可以通过文本描述快速定位商品;在自动驾驶中,可以根据语音指令定位交通标志或行人。该研究降低了视觉定位的计算成本,使其更容易部署在资源受限的设备上,具有广阔的应用前景。
📄 摘要(原文)
Visual grounding aims to predict the locations of target objects specified by textual descriptions. For this task with linguistic and visual modalities, there is a latest research line that focuses on only selecting the linguistic-relevant visual regions for object localization to reduce the computational overhead. Albeit achieving impressive performance, it is iteratively performed on different image scales, and at every iteration, linguistic features and visual features need to be stored in a cache, incurring extra overhead. To facilitate the implementation, in this paper, we propose a feature selection-based simple yet effective baseline for visual grounding, called FSVG. Specifically, we directly encapsulate the linguistic and visual modalities into an overall network architecture without complicated iterative procedures, and utilize the language in parallel as guidance to facilitate the interaction between linguistic modal and visual modal for extracting effective visual features. Furthermore, to reduce the computational cost, during the visual feature learning, we introduce a similarity-based feature selection mechanism to only exploit language-related visual features for faster prediction. Extensive experiments conducted on several benchmark datasets comprehensively substantiate that the proposed FSVG achieves a better balance between accuracy and efficiency beyond the current state-of-the-art methods. Code is available at https://github.com/jcwang0602/FSVG.