Injecting Frame-Event Complementary Fusion into Diffusion for Optical Flow in Challenging Scenes
作者: Haonan Wang, Hanyu Zhou, Haoyue Liu, Luxin Yan
分类: cs.CV
发布日期: 2025-10-12
💡 一句话要点
提出Diff-ABFlow,融合帧-事件互补信息,解决恶劣场景光流估计难题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 光流估计 扩散模型 事件相机 帧事件融合 恶劣环境 运动估计 计算机视觉
📋 核心要点
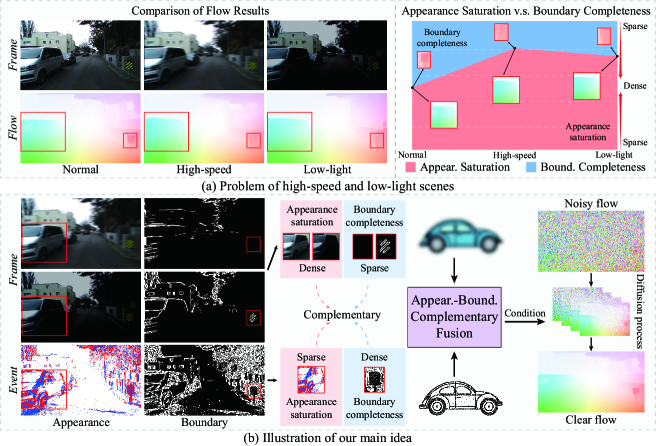
- 传统光流方法在高速和低光照等恶劣环境下,因图像模糊和光照不足而失效,严重影响特征匹配。
- Diff-ABFlow利用扩散模型学习噪声流到清晰流的映射,避免了对恶化视觉特征的依赖,实现更鲁棒的光流估计。
- 该方法融合了帧相机提供的密集表观信息和事件相机提供的精确边界信息,互补各自的优势。
📝 摘要(中文)
光流估计在常规场景中取得了显著成果,但在高速和低光照等具有挑战性的场景中,由于运动模糊和光照不足,面临着严峻的挑战。这些条件导致纹理减弱和噪声放大,并降低了帧相机的外观饱和度和边界完整性,而这些对于运动特征匹配至关重要。在退化场景中,帧相机由于成像时间长和动态范围低,提供密集的表观饱和度,但边界完整性稀疏。相比之下,事件相机提供稀疏的表观饱和度,但其短成像时间和高动态范围产生密集的边界完整性。传统方法利用特征融合或领域自适应来引入事件信息以改善边界完整性。然而,表观特征仍然恶化,严重影响了大多数采用的判别模型(学习从视觉特征到运动场的映射)和生成模型(基于给定的视觉特征生成运动场)。因此,我们引入扩散模型,学习从噪声流到清晰流的映射,这不受恶化的视觉特征的影响。因此,我们提出了一种新颖的光流估计框架Diff-ABFlow,该框架基于扩散模型,具有帧-事件外观-边界融合。
🔬 方法详解
问题定义:论文旨在解决在具有挑战性的场景(如高速运动和低光照)下,传统光流估计方法由于运动模糊、光照不足等问题导致的性能下降。现有方法依赖于帧相机提供的视觉特征,但在这些场景下,帧相机的图像质量会严重降低,导致特征匹配困难,进而影响光流估计的准确性。
核心思路:论文的核心思路是利用扩散模型学习从噪声光流到清晰光流的映射,从而避免直接依赖于恶化的视觉特征。同时,结合帧相机和事件相机的互补信息:帧相机提供密集的表观信息,而事件相机提供精确的边界信息。通过融合这两种信息,可以提高光流估计的鲁棒性和准确性。
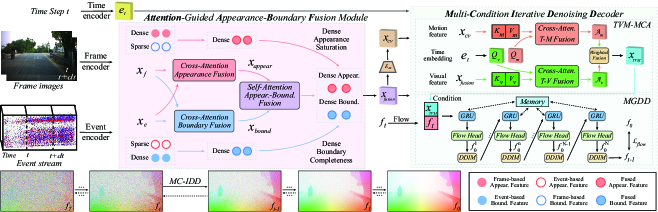
技术框架:Diff-ABFlow框架主要包含以下几个模块:1) 帧特征提取模块:提取帧图像的视觉特征。2) 事件特征提取模块:提取事件数据的边界特征。3) 特征融合模块:将帧特征和事件特征进行融合,得到融合后的特征表示。4) 扩散模型:利用融合后的特征作为条件,通过扩散过程将噪声光流逐步去噪,最终得到清晰的光流估计。
关键创新:该论文的关键创新在于:1) 将扩散模型引入光流估计任务,使其能够从噪声中恢复光流,从而避免对恶化视觉特征的依赖。2) 提出了一种帧-事件外观-边界融合方法,充分利用了两种传感器的互补信息,提高了光流估计的准确性和鲁棒性。
关键设计:论文中可能包含以下关键设计:1) 特征融合策略:如何有效地融合帧特征和事件特征,例如使用注意力机制或可学习的融合权重。2) 扩散模型的结构:选择合适的扩散模型架构,例如U-Net结构,并设计合适的噪声调度策略。3) 损失函数:设计合适的损失函数来训练扩散模型,例如L1损失或L2损失,以及可能的感知损失或对抗损失。
🖼️ 关键图片

📊 实验亮点
论文提出的Diff-ABFlow在具有挑战性的场景下,光流估计精度显著优于现有方法。具体性能提升数据未知,但摘要强调了该方法在恶劣环境下的鲁棒性,表明其在运动模糊和低光照等情况下,能够提供更准确的光流估计结果。与传统方法相比,Diff-ABFlow能够更好地处理恶化的视觉特征,从而提高光流估计的准确性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、视频监控等领域。在这些应用中,传感器常常需要在恶劣环境下工作,例如高速运动或低光照条件。Diff-ABFlow能够在这种环境下提供更准确的光流估计,从而提高系统的性能和可靠性。未来,该方法还可以扩展到其他运动估计任务,例如三维重建和视觉SLAM。
📄 摘要(原文)
Optical flow estimation has achieved promising results in conventional scenes but faces challenges in high-speed and low-light scenes, which suffer from motion blur and insufficient illumination. These conditions lead to weakened texture and amplified noise and deteriorate the appearance saturation and boundary completeness of frame cameras, which are necessary for motion feature matching. In degraded scenes, the frame camera provides dense appearance saturation but sparse boundary completeness due to its long imaging time and low dynamic range. In contrast, the event camera offers sparse appearance saturation, while its short imaging time and high dynamic range gives rise to dense boundary completeness. Traditionally, existing methods utilize feature fusion or domain adaptation to introduce event to improve boundary completeness. However, the appearance features are still deteriorated, which severely affects the mostly adopted discriminative models that learn the mapping from visual features to motion fields and generative models that generate motion fields based on given visual features. So we introduce diffusion models that learn the mapping from noising flow to clear flow, which is not affected by the deteriorated visual features. Therefore, we propose a novel optical flow estimation framework Diff-ABFlow based on diffusion models with frame-event appearance-boundary fusion.