VR-Thinker: Boosting Video Reward Models through Thinking-with-Image Reasoning
作者: Qunzhong Wang, Jie Liu, Jiajun Liang, Yilei Jiang, Yuanxing Zhang, Jinyuan Chen, Yaozhi Zheng, Xintao Wang, Pengfei Wan, Xiangyu Yue, Jiaheng Liu
分类: cs.CV
发布日期: 2025-10-12 (更新: 2025-10-15)
💡 一句话要点
提出VR-Thinker,通过图像推理增强视频奖励模型,提升长视频偏好判断。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频奖励模型 视觉推理 长视频理解 强化学习 多模态学习
📋 核心要点
- 现有视频奖励模型受限于视觉信息过载,导致细节丢失和推理幻觉,尤其是在处理长视频时。
- VR-Thinker通过引入视觉推理操作和可配置的视觉记忆窗口,使模型能够主动获取和更新视觉证据。
- 实验表明,VR-Thinker在多个视频偏好基准测试中取得了SOTA结果,尤其在长视频上提升显著。
📝 摘要(中文)
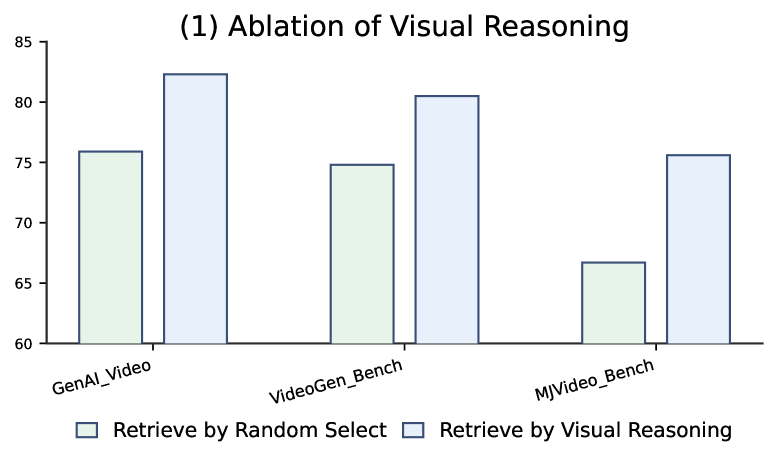
多模态奖励模型(RMs)的最新进展显著改善了视觉生成模型的后训练。然而,当前的RMs面临固有的局限性:(1)视觉输入消耗大量的上下文预算,迫使减少帧数并导致丢失细粒度细节;(2)所有视觉信息都被打包到初始提示中,加剧了思维链推理过程中的幻觉和遗忘。为了克服这些问题,我们引入了VideoReward Thinker (VR-Thinker),这是一个通过图像推理的框架,它为RM配备了视觉推理操作(例如,选择帧)和一个可配置的视觉记忆窗口。这使得RM能够在上下文限制内主动获取和更新视觉证据,从而提高推理的保真度和可靠性。我们通过强化微调管道激活视觉推理:(i)使用精选的视觉思维链数据进行冷启动,以提炼基本的推理技能和操作格式;(ii)选择每个维度和整体判断都正确的样本,然后对这些高质量的轨迹进行拒绝采样微调,以进一步增强推理;(iii)应用组相对策略优化(GRPO)来加强推理。我们的方法在视频偏好基准测试中提供了最先进的开源模型准确性,特别是对于较长的视频:一个7B VR-Thinker在VideoGen Reward上达到80.5%,在GenAI-Bench上达到82.3%,在MJ-Bench-Video上达到75.6%。这些结果验证了通过图像推理的多模态奖励建模的有效性和前景。
🔬 方法详解
问题定义:现有视频奖励模型在处理长视频时,由于视觉输入消耗大量上下文预算,导致模型被迫减少帧数,丢失细粒度细节。此外,将所有视觉信息打包到初始提示中,会加剧思维链推理过程中的幻觉和遗忘,影响判断准确性。
核心思路:VR-Thinker的核心思路是赋予奖励模型(RM)主动进行视觉推理的能力,使其能够像人类一样,在推理过程中选择性地观察和记忆关键帧,从而在有限的上下文预算下,更有效地利用视觉信息,提高推理的保真度和可靠性。
技术框架:VR-Thinker的技术框架主要包含以下几个部分:1) 视觉推理操作模块:允许RM执行诸如“选择帧”之类的操作,以主动获取视觉证据。2) 可配置的视觉记忆窗口:用于存储和更新RM在推理过程中提取的关键帧信息。3) 强化微调管道:包括冷启动、拒绝采样微调和组相对策略优化(GRPO)三个阶段,用于训练RM的视觉推理能力。
关键创新:VR-Thinker最重要的技术创新在于“thinking-with-image”的框架,它打破了传统RM将所有视觉信息一次性输入的模式,转而让RM在推理过程中主动与视觉信息交互,从而更有效地利用视觉信息。与现有方法的本质区别在于,VR-Thinker赋予了RM主动学习和推理的能力,而不是仅仅依赖于预先给定的视觉输入。
关键设计:在强化微调管道中,冷启动阶段使用精选的视觉思维链数据,以提炼基本的推理技能和操作格式。拒绝采样微调阶段选择每个维度和整体判断都正确的样本,以进一步增强推理能力。GRPO阶段则通过组相对策略优化来加强推理。具体参数设置和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片


📊 实验亮点
VR-Thinker在多个视频偏好基准测试中取得了显著的性能提升。具体来说,一个7B参数的VR-Thinker模型在VideoGen Reward上达到了80.5%的准确率,在GenAI-Bench上达到了82.3%的准确率,在MJ-Bench-Video上达到了75.6%的准确率。这些结果表明,VR-Thinker在长视频偏好判断方面具有显著优势。
🎯 应用场景
VR-Thinker可应用于视频生成模型的训练和评估,例如,用于优化文本到视频生成模型的输出质量,或用于评估不同视频生成模型的性能。此外,该方法还可扩展到其他需要视觉推理的多模态任务中,例如视频问答、视频摘要等。
📄 摘要(原文)
Recent advancements in multimodal reward models (RMs) have substantially improved post-training for visual generative models. However, current RMs face inherent limitations: (1) visual inputs consume large context budgets, forcing fewer frames and causing loss of fine-grained details; and (2) all visual information is packed into the initial prompt, exacerbating hallucination and forgetting during chain-of-thought reasoning. To overcome these issues, we introduce VideoReward Thinker (VR-Thinker), a thinking-with-image framework that equips the RM with visual reasoning operations (e.g., select frame) and a configurable visual memory window. This allows the RM to actively acquire and update visual evidence within context limits, improving reasoning fidelity and reliability. We activate visual reasoning via a reinforcement fine-tuning pipeline: (i) Cold Start with curated visual chain-of-thought data to distill basic reasoning skills and operation formatting; (ii) select samples whose per-dimension and overall judgments are all correct, then conduct Rejection sampling Fine-Tuning on these high-quality traces to further enhance reasoning; and (iii) apply Group Relative Policy Optimization (GRPO) to strengthen reasoning. Our approach delivers state-of-the-art accuracy among open-source models on video preference benchmarks, especially for longer videos: a 7B VR-Thinker achieves 80.5% on VideoGen Reward, 82.3% on GenAI-Bench, and 75.6% on MJ-Bench-Video. These results validate the effectiveness and promise of thinking-with-image multimodal reward modeling.