Towards Efficient 3D Gaussian Human Avatar Compression: A Prior-Guided Framework
作者: Shanzhi Yin, Bolin Chen, Xinju Wu, Ru-Ling Liao, Jie Chen, Shiqi Wang, Yan Ye
分类: eess.IV, cs.CV, cs.MM
发布日期: 2025-10-12
备注: 10 pages, 4 figures
💡 一句话要点
提出一种先验引导的3D高斯人体Avatar高效压缩框架,实现超低码率高质量的动态人体重建。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D人体Avatar 高斯Splatting 视频压缩 人体先验 线性混合蒙皮
📋 核心要点
- 现有3D人体Avatar压缩方法在保持高质量的同时,难以实现超低比特率的压缩,限制了其在带宽受限场景下的应用。
- 该论文提出一种基于人体先验引导的3D高斯Avatar压缩框架,将Avatar的外观和时间演变解耦,分别进行高效压缩。
- 实验结果表明,该方法在主流数据集上显著优于传统编解码器和现有基于3D高斯splatting的压缩方法,实现了更好的率失真性能。
📝 摘要(中文)
本文提出了一种高效的3D人体Avatar编码框架,该框架利用紧凑的人体先验和规范到目标的转换,实现了超低比特率下高质量的3D人体Avatar视频压缩。该框架首先以无网络的方式训练一个使用铰接splatting的规范高斯Avatar,作为Avatar外观建模的基础。同时,采用人体先验模板,通过紧凑的参数化表示来捕获时间上的身体运动。这种外观和时间演变的分解最大限度地减少了冗余,从而实现了高效压缩:规范Avatar在整个序列中共享,只需要压缩一次,而时间参数(每帧仅包含94个参数)以最小的比特率传输。对于每一帧,目标人体Avatar通过线性混合蒙皮变换对规范Avatar进行变形来生成,从而促进了时间连贯的视频重建和新视角合成。实验结果表明,在主流的多视角人体视频数据集上,该方法在率失真性能方面显著优于传统的2D/3D编解码器和现有的可学习动态3D高斯splatting压缩方法,为元宇宙应用中无缝的沉浸式多媒体体验铺平了道路。
🔬 方法详解
问题定义:论文旨在解决3D人体Avatar视频在超低比特率下的高效压缩问题。现有方法,包括传统的2D/3D编解码器和新兴的基于3D高斯splatting的压缩方法,在低比特率下难以保持重建质量,或者压缩效率不高,无法满足元宇宙等应用的需求。
核心思路:论文的核心思路是将3D人体Avatar的表示解耦为静态的规范Avatar外观和动态的身体运动。规范Avatar负责捕捉人物的静态外观信息,而身体运动则通过紧凑的参数化人体先验模板来表示。这种解耦降低了时间冗余,使得只需要对规范Avatar进行一次压缩,而对时间参数进行低比特率的传输。
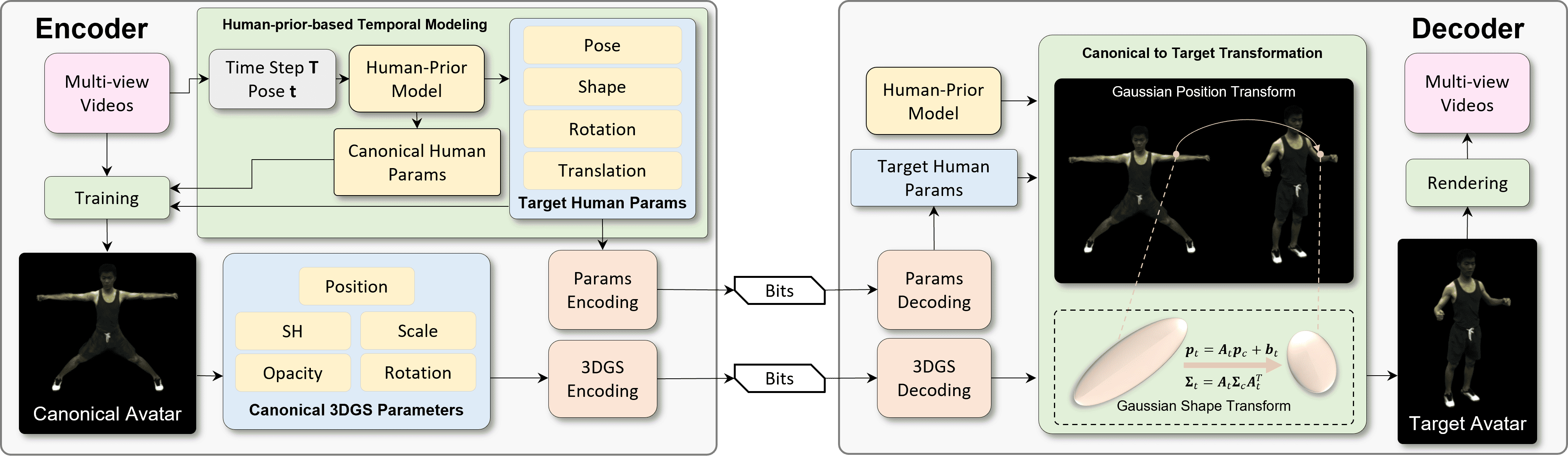
技术框架:该框架主要包含以下几个阶段:1) 训练一个规范高斯Avatar,作为Avatar外观建模的基础。2) 利用人体先验模板,通过紧凑的参数化表示来捕获时间上的身体运动。3) 对于每一帧,通过线性混合蒙皮(Linear Blend Skinning, LBS)变换对规范Avatar进行变形,生成目标人体Avatar。4) 对规范Avatar和时间参数分别进行压缩和传输。
关键创新:该方法最重要的创新点在于将3D高斯Avatar与人体先验知识相结合,实现了对Avatar外观和运动的解耦表示。这种解耦使得可以独立地对静态外观和动态运动进行压缩,从而显著提高了压缩效率。此外,使用铰接splatting以无网络的方式训练规范高斯Avatar,避免了对大量训练数据的依赖。
关键设计:论文的关键设计包括:1) 使用94个参数的人体先验模板来表示身体运动,实现了紧凑的参数化表示。2) 使用线性混合蒙皮变换将规范Avatar变形为目标Avatar,保证了时间上的连贯性。3) 规范高斯Avatar的训练采用铰接splatting方法,避免了网络训练的复杂性。4) 针对规范Avatar和时间参数,采用不同的压缩策略,以实现最佳的率失真性能。
🖼️ 关键图片
📊 实验亮点
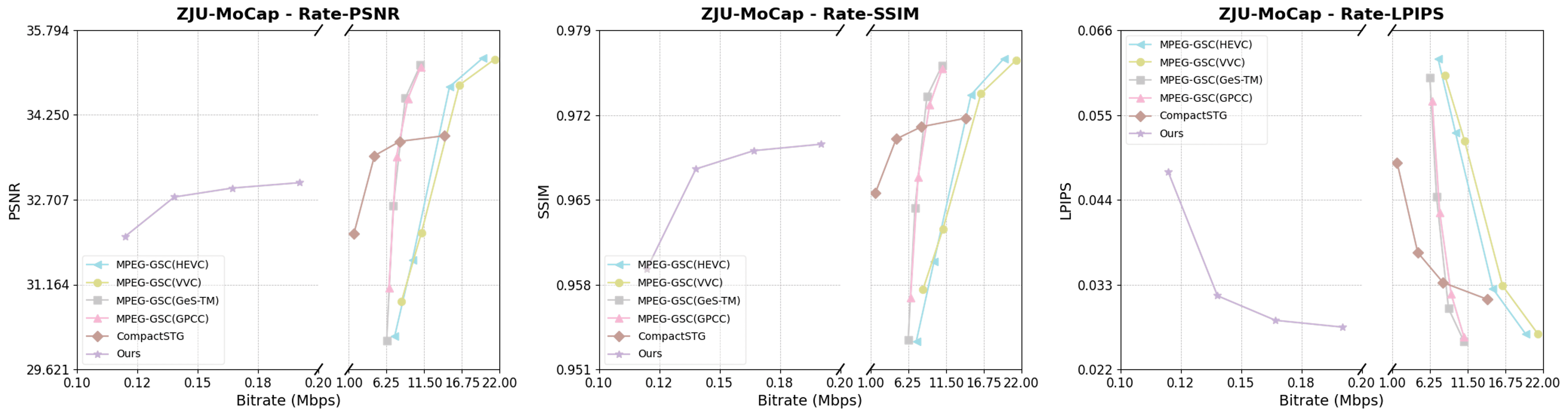
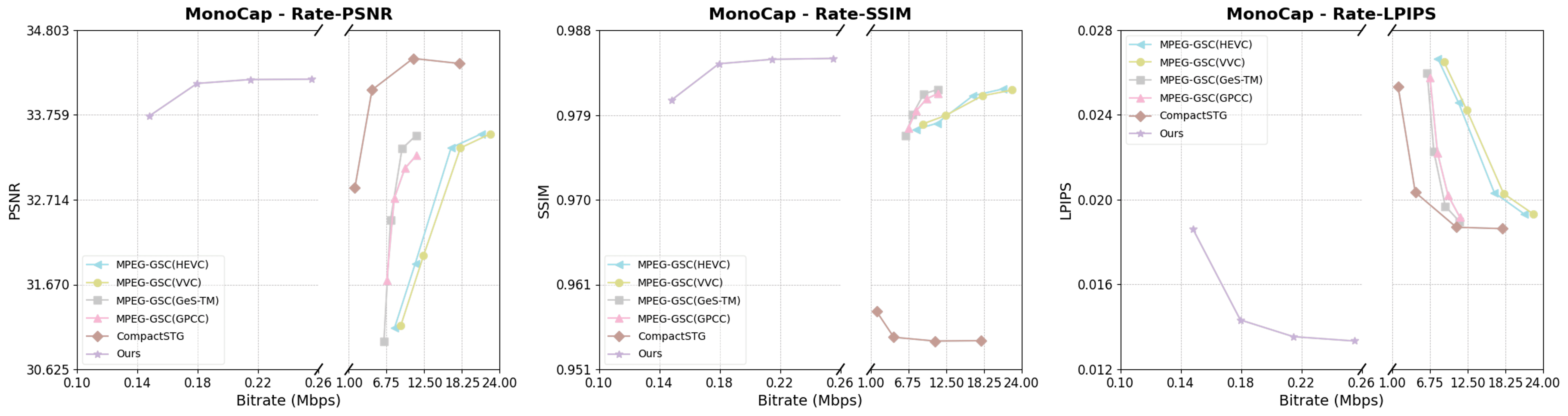
实验结果表明,该方法在主流多视角人体视频数据集上,显著优于传统的2D/3D编解码器和现有的基于3D高斯splatting的压缩方法。具体而言,该方法在率失真性能方面取得了显著提升,能够在超低比特率下保持高质量的重建效果,为实现无缝的沉浸式多媒体体验奠定了基础。
🎯 应用场景
该研究成果可广泛应用于元宇宙、虚拟现实、增强现实、远程会议、数字人等领域。通过超低比特率的3D人体Avatar视频传输,可以实现更流畅、更逼真的沉浸式体验,尤其是在带宽受限的网络环境下,具有重要的应用价值和商业前景。未来,该技术有望推动虚拟社交、在线教育、远程医疗等领域的发展。
📄 摘要(原文)
This paper proposes an efficient 3D avatar coding framework that leverages compact human priors and canonical-to-target transformation to enable high-quality 3D human avatar video compression at ultra-low bit rates. The framework begins by training a canonical Gaussian avatar using articulated splatting in a network-free manner, which serves as the foundation for avatar appearance modeling. Simultaneously, a human-prior template is employed to capture temporal body movements through compact parametric representations. This decomposition of appearance and temporal evolution minimizes redundancy, enabling efficient compression: the canonical avatar is shared across the sequence, requiring compression only once, while the temporal parameters, consisting of just 94 parameters per frame, are transmitted with minimal bit-rate. For each frame, the target human avatar is generated by deforming canonical avatar via Linear Blend Skinning transformation, facilitating temporal coherent video reconstruction and novel view synthesis. Experimental results demonstrate that the proposed method significantly outperforms conventional 2D/3D codecs and existing learnable dynamic 3D Gaussian splatting compression method in terms of rate-distortion performance on mainstream multi-view human video datasets, paving the way for seamless immersive multimedia experiences in meta-verse applications.