Towards Self-Refinement of Vision-Language Models with Triangular Consistency
作者: Yunlong Deng, Guangyi Chen, Tianpei Gu, Lingjing Kong, Yan Li, Zeyu Tang, Kun Zhang
分类: cs.CV, cs.AI
发布日期: 2025-10-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于三角一致性的自精炼框架,提升视觉-语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 自精炼 三角一致性 无监督学习 指令微调
📋 核心要点
- 现有视觉-语言模型主要依赖有监督的视觉指令微调,未充分挖掘无监督指令下的自精炼潜力。
- 提出基于三角一致性的自精炼框架,通过图像-问题-答案三元组的一致性约束,实现模型自主学习。
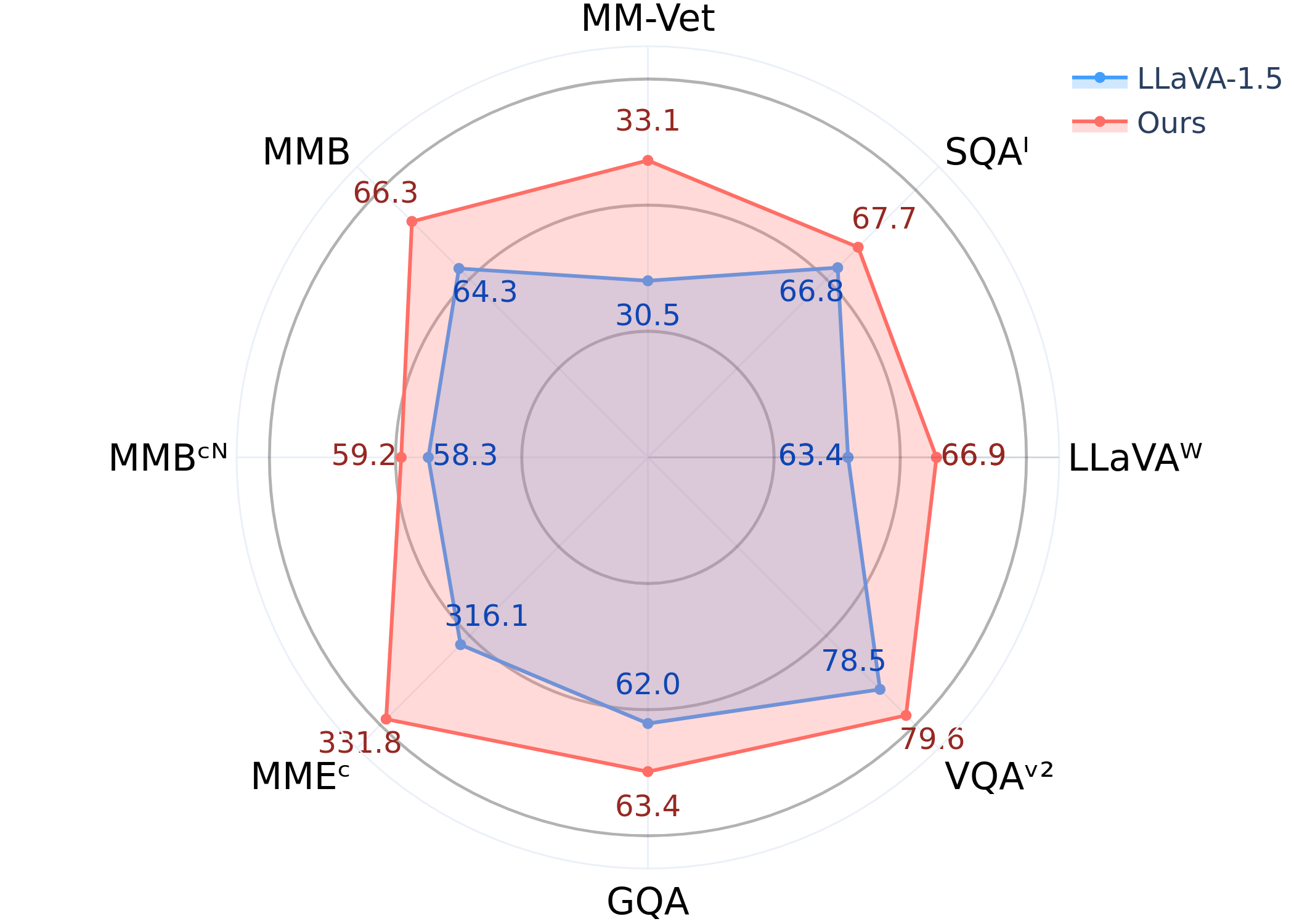
- 实验表明,该方法在LLaVA-1.5基础上,无需外部监督即可在多个基准测试中实现性能提升。
📝 摘要(中文)
本文研究了视觉-语言模型(VLMs)在无监督指令下的自精炼能力。通过图像-问题-答案三元组,VLMs集成了视觉知识和大型语言模型的分析能力。本文验证了VLMs具有内在的自精炼能力,无需外部输入即可生成高质量的监督数据,从而实现自主学习。为了激发VLMs的自精炼能力,本文提出了一种基于三角一致性原则的自精炼框架:在图像-查询-答案三角中,任何被掩盖的元素都应被一致且准确地重建。该框架包括三个步骤:(1)通过添加多任务指令微调(如image→question-answer或image-answer→question)来启用VLMs的指令生成能力。(2)从无标签图像生成图像-查询-答案三元组,并使用三角一致性原则进行过滤。(3)使用过滤后的合成数据进一步更新模型。为了研究这种自精炼能力背后的潜在机制,我们从因果角度进行了理论分析。实验表明,使用广泛认可的LLaVA-1.5作为基线,该模型可以在没有任何外部监督(如人工标注或环境反馈)的情况下,自主地在多个基准测试中实现一致的改进。我们期望这项研究对VLMs自精炼能力的见解能够激发未来对VLMs学习机制的研究。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)的训练主要依赖于人工标注的图像-问题-答案三元组数据,这种方式成本高昂且难以扩展。此外,VLMs本身所蕴含的知识和推理能力并没有得到充分利用,尤其是在缺乏人工监督的情况下,如何让VLMs自主学习和提升性能是一个重要的挑战。
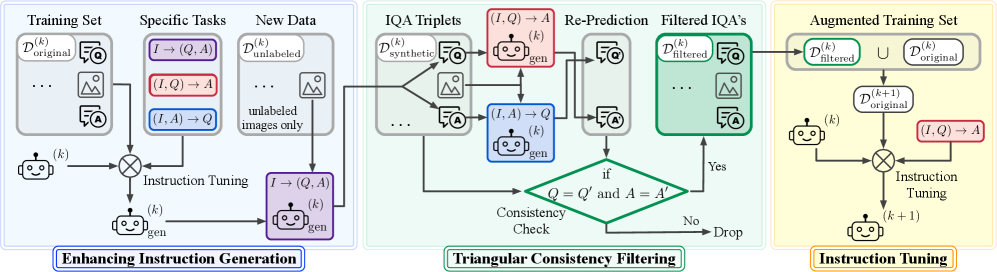
核心思路:本文的核心思路是利用VLMs自身的能力,通过自生成和自过滤的方式,构建高质量的训练数据,从而实现模型的自精炼。具体来说,通过引入三角一致性原则,即图像、问题和答案之间应该保持语义一致性,来筛选掉低质量的合成数据,保证训练的有效性。
技术框架:该自精炼框架主要包含三个阶段:1) 指令生成能力增强:通过多任务指令微调,使VLMs具备根据图像生成问题和答案的能力,或者根据图像和答案生成问题的能力。2) 数据生成与过滤:利用增强后的VLMs,从无标签图像中生成图像-问题-答案三元组,并使用三角一致性原则对生成的数据进行过滤,保留高质量的三元组。3) 模型更新:使用过滤后的合成数据,对VLMs进行进一步的训练,从而提升模型的性能。
关键创新:该方法最重要的创新点在于提出了基于三角一致性的自精炼框架,它能够有效地利用VLMs自身的知识和推理能力,在没有人工监督的情况下,实现模型的自主学习和性能提升。与传统的有监督学习方法相比,该方法降低了对人工标注数据的依赖,提高了模型的泛化能力。
关键设计:在指令生成能力增强阶段,采用了多任务学习的方式,同时训练VLMs生成问题和答案的能力。在数据过滤阶段,使用了三角一致性原则,通过比较不同生成方式得到的结果,来判断数据的质量。例如,先用图像生成问题和答案,再用图像和答案生成问题,如果两次生成的问题相似度较高,则认为该三元组数据质量较高。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于三角一致性的自精炼框架能够有效提升LLaVA-1.5模型的性能。在多个基准测试中,该模型在没有任何外部监督的情况下,实现了持续且稳定的性能提升。虽然提升幅度相对保守,但验证了VLMs在无监督条件下的自精炼潜力,为未来的研究方向提供了新的思路。
🎯 应用场景
该研究成果可应用于各种视觉-语言任务,例如图像描述、视觉问答、图像检索等。通过自精炼的方式,可以降低对人工标注数据的依赖,提高模型在实际应用中的泛化能力和鲁棒性。此外,该方法还可以用于构建更大规模、更高质量的视觉-语言数据集,推动相关领域的发展。
📄 摘要(原文)
Vision-Language Models (VLMs) integrate visual knowledge with the analytical capabilities of Large Language Models (LLMs) through supervised visual instruction tuning, using image-question-answer triplets. However, the potential of VLMs trained without supervised instruction remains largely unexplored. This study validates that VLMs possess inherent self-refinement capabilities, enabling them to generate high-quality supervised data without external inputs and thereby learn autonomously. Specifically, to stimulate the self-refinement ability of VLMs, we propose a self-refinement framework based on a Triangular Consistency principle: within the image-query-answer triangle, any masked elements should be consistently and accurately reconstructed. The framework involves three steps: (1) We enable the instruction generation ability of VLMs by adding multi-task instruction tuning like image$\rightarrow$question-answer or image-answer$\rightarrow$question. (2) We generate image-query-answer triplets from unlabeled images and use the Triangular Consistency principle for filtering. (3) The model is further updated using the filtered synthetic data. To investigate the underlying mechanisms behind this self-refinement capability, we conduct a theoretical analysis from a causal perspective. Using the widely recognized LLaVA-1.5 as our baseline, our experiments reveal that the model can autonomously achieve consistent, though deliberately modest, improvements across multiple benchmarks without any external supervision, such as human annotations or environmental feedback. We expect that the insights of this study on the self-refinement ability of VLMs can inspire future research on the learning mechanism of VLMs. Code is available at https://github.com/dengyl20/SRF-LLaVA-1.5.