MSF-Mamba: Motion-aware State Fusion Mamba for Efficient Micro-Gesture Recognition
作者: Deng Li, Jun Shao, Bohao Xing, Rong Gao, Bihan Wen, Heikki Kälviäinen, Xin Liu
分类: cs.CV
发布日期: 2025-10-12 (更新: 2025-10-16)
💡 一句话要点
提出MSF-Mamba,通过运动感知状态融合提升Mamba在微手势识别中的效率与精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 微手势识别 状态空间模型 Mamba 运动感知 时空建模 中心帧差 多尺度融合
📋 核心要点
- 现有微手势识别方法难以兼顾长程时序依赖和局部时空特征,且缺乏对运动信息的有效利用。
- MSF-Mamba通过运动感知状态融合模块,将局部上下文信息融入Mamba的状态更新中,增强了局部时空建模能力。
- 实验结果表明,MSF-Mamba在微手势识别任务上取得了优于现有方法的效果,同时保持了较高的计算效率。
📝 摘要(中文)
微手势识别(MGR)旨在识别细微的人体动作,需要精确建模长程和局部时空依赖关系。卷积神经网络(CNN)擅长捕捉局部模式,但由于感受野有限,难以处理长程依赖。基于Transformer的模型通过自注意力机制解决了这个问题,但计算成本很高。最近,Mamba作为一种高效模型展现出潜力,它利用状态空间模型(SSM)实现线性时间处理。然而,直接将原始Mamba应用于MGR可能并非最优,因为它将输入视为1D序列,状态更新仅依赖于前一个状态,缺乏建模局部时空依赖的能力。此外,先前的方法缺乏运动感知的设计,这在MGR中至关重要。为了克服这些限制,我们提出了运动感知状态融合Mamba(MSF-Mamba),通过融合局部上下文相邻状态来增强Mamba的局部时空建模能力。我们的设计引入了基于中心帧差(CFD)的运动感知状态融合模块。此外,还提出了一个多尺度版本MSF-Mamba+。MSF-Mamba支持多尺度运动感知状态融合,以及自适应尺度加权模块,动态地加权不同尺度的融合状态。这些增强显式地解决了原始Mamba的局限性,通过启用运动感知的局部时空建模,使MSF-Mamba和MSF-Mamba+能够有效地捕捉MGR的细微运动线索。在两个公共MGR数据集上的实验表明,即使是轻量级版本MSF-Mamba也实现了SoTA性能,优于现有的基于CNN、Transformer和SSM的模型,同时保持了高效率。
🔬 方法详解
问题定义:微手势识别旨在识别细微的人体动作,需要精确建模长程和局部时空依赖关系。现有方法,如CNNs和Transformers,在捕捉长程依赖和局部时空特征方面存在局限性。CNNs感受野有限,难以捕捉长程依赖;Transformers计算复杂度高。Mamba虽然高效,但原始版本缺乏对局部时空信息的有效建模,且忽略了运动信息的重要性。
核心思路:论文的核心思路是通过运动感知的状态融合来增强Mamba模型,使其能够更好地捕捉微手势中的局部时空信息和运动特征。通过融合相邻状态的上下文信息,弥补Mamba在局部建模上的不足。同时,利用中心帧差(CFD)提取运动信息,并将其融入状态融合过程中,提高模型对细微运动的敏感度。
技术框架:MSF-Mamba的整体框架基于Mamba模型,并引入了运动感知状态融合模块。该模块首先利用中心帧差(CFD)提取运动信息,然后将提取的运动信息用于指导相邻状态的融合。融合后的状态被用于更新Mamba的状态,从而实现运动感知的局部时空建模。MSF-Mamba+则在MSF-Mamba的基础上,引入了多尺度状态融合和自适应尺度加权模块,进一步提升了模型的性能。
关键创新:论文的关键创新在于提出了运动感知状态融合模块,将局部时空信息和运动信息融入Mamba的状态更新过程中。与原始Mamba相比,MSF-Mamba能够更好地捕捉微手势中的细微运动特征。与现有方法相比,MSF-Mamba在保持高效率的同时,实现了更高的识别精度。
关键设计:运动感知状态融合模块的关键设计包括:1) 使用中心帧差(CFD)提取运动信息;2) 设计状态融合机制,将相邻状态的上下文信息融入当前状态;3) 在MSF-Mamba+中,使用多尺度状态融合和自适应尺度加权模块,进一步提升模型性能。具体的参数设置和网络结构细节在论文中有详细描述,但未在摘要中体现。
🖼️ 关键图片
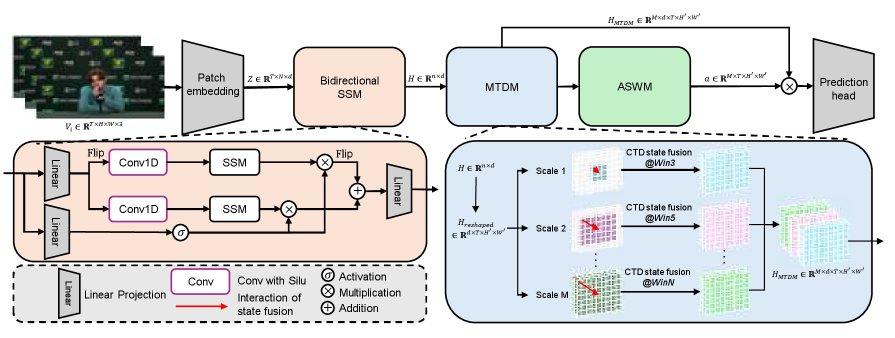

📊 实验亮点
MSF-Mamba在两个公开的微手势识别数据集上取得了SoTA性能,超越了现有的CNN、Transformer和SSM模型。即使是轻量级版本MSF-Mamba,也在保持高效率的同时,实现了显著的性能提升。具体的性能数据和提升幅度在论文中有详细描述,但摘要中未给出具体数值。
🎯 应用场景
该研究成果可应用于人机交互、医疗健康、安全监控等领域。例如,在智能家居中,可以通过识别用户的微手势来实现对设备的控制;在医疗领域,可以用于辅助诊断帕金森等疾病;在安全监控领域,可以用于检测异常行为。
📄 摘要(原文)
Micro-gesture recognition (MGR) targets the identification of subtle and fine-grained human motions and requires accurate modeling of both long-range and local spatiotemporal dependencies. While CNNs are effective at capturing local patterns, they struggle with long-range dependencies due to their limited receptive fields. Transformer-based models address this limitation through self-attention mechanisms but suffer from high computational costs. Recently, Mamba has shown promise as an efficient model, leveraging state space models (SSMs) to enable linear-time processing However, directly applying the vanilla Mamba to MGR may not be optimal. This is because Mamba processes inputs as 1D sequences, with state updates relying solely on the previous state, and thus lacks the ability to model local spatiotemporal dependencies. In addition, previous methods lack a design of motion-awareness, which is crucial in MGR. To overcome these limitations, we propose motion-aware state fusion mamba (MSF-Mamba), which enhances Mamba with local spatiotemporal modeling by fusing local contextual neighboring states. Our design introduces a motion-aware state fusion module based on central frame difference (CFD). Furthermore, a multiscale version named MSF-Mamba+ has been proposed. Specifically, MSF-Mamba supports multiscale motion-aware state fusion, as well as an adaptive scale weighting module that dynamically weighs the fused states across different scales. These enhancements explicitly address the limitations of vanilla Mamba by enabling motion-aware local spatiotemporal modeling, allowing MSF-Mamba and MSF-Mamba to effectively capture subtle motion cues for MGR. Experiments on two public MGR datasets demonstrate that even the lightweight version, namely, MSF-Mamba, achieves SoTA performance, outperforming existing CNN-, Transformer-, and SSM-based models while maintaining high efficiency.