When Images Speak Louder: Mitigating Language Bias-induced Hallucinations in VLMs through Cross-Modal Guidance
作者: Jinjin Cao, Zhiyang Chen, Zijun Wang, Liyuan Ma, Weijian Luo, Guojun Qi
分类: cs.CV
发布日期: 2025-10-12
💡 一句话要点
提出跨模态引导CMG方法,缓解视觉语言模型中的语言偏见导致的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态学习 幻觉缓解 跨模态引导 语言偏见
📋 核心要点
- 现有VLM易受语言偏见影响,产生与图像无关的幻觉式回复,影响多模态理解的准确性。
- 提出跨模态引导(CMG)方法,通过退化视觉-语言注意力,强调视觉信息,减少语言偏见。
- 实验表明CMG无需训练即可有效提升VLM在幻觉基准测试上的性能,并具有良好的泛化能力。
📝 摘要(中文)
视觉语言模型(VLM)在视觉和语言上下文的多模态理解方面表现出强大的能力。然而,现有的VLM常常面临严重的幻觉挑战,即VLM倾向于生成在语言上流畅但与图像无关的响应。为了解决这个问题,我们分析了语言偏见如何导致幻觉,并引入了跨模态引导(CMG),这是一种无需训练的解码方法,通过利用原始模型和视觉-语言注意力退化模型之间的输出分布差异来解决幻觉问题。在实践中,我们自适应地屏蔽所选Transformer层中最具影响力的图像token的注意力权重,以破坏视觉-语言感知作为一种具体的退化类型。这种退化诱导的解码强调了对视觉上下文的感知,从而显著减少了语言偏见,而不会损害VLM的能力。实验结果表明,CMG具有优越的优势,无需额外的条件或训练成本。我们还定量地表明,CMG可以提高不同VLM在特定于幻觉的基准测试中的性能,并有效地推广。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在生成文本时,容易受到语言偏见的影响,产生与输入图像内容无关的“幻觉”现象。这种幻觉降低了VLM在多模态任务中的可靠性,限制了其应用。现有方法通常需要额外的训练或复杂的模型结构来缓解幻觉,成本较高。
核心思路:论文的核心思路是通过引入一种跨模态引导(CMG)的解码策略,在不进行额外训练的情况下,利用视觉信息来抑制语言偏见。CMG的核心在于人为地降低VLM对视觉信息的依赖,然后通过比较原始模型和视觉信息弱化后的模型的输出分布,来引导模型更多地关注视觉内容,从而减少幻觉。
技术框架:CMG方法主要包含以下几个步骤:1) 选择Transformer模型的特定层;2) 在选定的层中,识别对输出影响最大的图像token;3) 通过自适应地屏蔽这些token的注意力权重,来降低模型对视觉信息的依赖;4) 利用原始模型和视觉信息弱化后的模型的输出分布差异,指导最终的文本生成。整个过程是一个解码阶段的策略,不需要额外的训练。
关键创新:该方法最大的创新在于提出了一种无需训练的跨模态引导策略,通过人为地引入视觉信息缺失,来迫使模型更加关注视觉内容,从而缓解语言偏见导致的幻觉。与现有方法相比,CMG不需要额外的训练数据或复杂的模型结构,具有更高的效率和通用性。
关键设计:CMG的关键设计包括:1) 如何选择Transformer层:论文可能通过实验确定哪些层对视觉-语言交互最为关键;2) 如何识别最具影响力的图像token:可能使用梯度或注意力权重等方法来评估token的重要性;3) 如何自适应地屏蔽注意力权重:可能采用动态调整屏蔽比例的策略,以平衡视觉信息和语言流畅性;4) 如何利用输出分布差异进行引导:可能使用KL散度等方法来衡量两个分布的差异,并将其作为指导信号。
🖼️ 关键图片

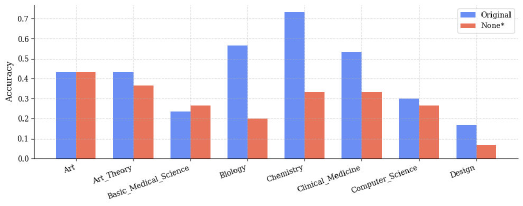

📊 实验亮点
实验结果表明,CMG方法在不进行额外训练的情况下,能够有效提升VLM在幻觉基准测试上的性能。具体而言,CMG在多个VLM模型上都取得了显著的提升,并且具有良好的泛化能力。实验结果还表明,CMG能够有效地减少语言偏见,提高模型对视觉信息的关注度。
🎯 应用场景
该研究成果可广泛应用于各种视觉语言任务,例如图像描述生成、视觉问答、视觉对话等。通过减少VLM中的幻觉现象,可以提高这些应用在实际场景中的可靠性和准确性,例如在智能客服、自动驾驶、医疗诊断等领域具有潜在的应用价值。未来,该方法可以进一步推广到其他多模态模型和任务中。
📄 摘要(原文)
Vision-Language Models (VLMs) have shown solid ability for multimodal understanding of both visual and language contexts. However, existing VLMs often face severe challenges of hallucinations, meaning that VLMs tend to generate responses that are only fluent in the language but irrelevant to images in previous contexts. To address this issue, we analyze how language bias contributes to hallucinations and then introduce Cross-Modal Guidance(CMG), a training-free decoding method that addresses the hallucinations by leveraging the difference between the output distributions of the original model and the one with degraded visual-language attention. In practice, we adaptively mask the attention weight of the most influential image tokens in selected transformer layers to corrupt the visual-language perception as a concrete type of degradation. Such a degradation-induced decoding emphasizes the perception of visual contexts and therefore significantly reduces language bias without harming the ability of VLMs. In experiment sections, we conduct comprehensive studies. All results demonstrate the superior advantages of CMG with neither additional conditions nor training costs. We also quantitatively show CMG can improve different VLM's performance on hallucination-specific benchmarks and generalize effectively.