Taming a Retrieval Framework to Read Images in Humanlike Manner for Augmenting Generation of MLLMs
作者: Suyang Xi, Chenxi Yang, Hong Ding, Yiqing Ni, Catherine C. Liu, Yunhao Liu, Chengqi Zhang
分类: cs.CV, cs.AI
发布日期: 2025-10-12
备注: 12 pages, 5 figures
💡 一句话要点
提出HuLiRAG框架,通过模拟人类视觉处理方式增强多模态大语言模型的生成能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉问答 检索增强生成 图像理解 空间推理
📋 核心要点
- 现有的多模态大语言模型在细粒度视觉问答中存在不足,容易产生幻觉,缺乏对局部细节的推理能力。
- HuLiRAG框架模拟人类视觉处理方式,通过“what--where--reweight”级联实现更精确的视觉信息检索和增强。
- 实验结果表明,HuLiRAG框架能够提高 grounding 的保真度和事实一致性,减少幻觉,提升多模态问答性能。
📝 摘要(中文)
多模态大语言模型(MLLM)在细粒度视觉问答中表现不佳,常常产生关于物体身份、位置和关系的幻觉,这是因为文本查询没有明确地锚定到视觉参照物上。检索增强生成(RAG)可以缓解一些错误,但它在检索和增强层面都未能与人类的处理方式对齐。具体来说,RAG只关注全局层面的图像信息,缺乏局部细节,并且限制了对细粒度交互的推理。为了克服这个限制,我们提出了Human-Like Retrieval-Augmented Generation (HuLiRAG),该框架将多模态推理分阶段进行,形成一个“what--where--reweight”的级联。首先通过开放词汇检测将查询锚定到候选参照物(what),然后利用SAM衍生的掩码在空间上解析以恢复细粒度精度(where),最后通过局部和全局对齐之间的权衡来自适应地确定优先级(reweight)。掩码引导的微调进一步将空间证据注入到生成过程中,将 grounding 从被动偏差转变为对答案公式的显式约束。大量的实验表明,这种类似人类的级联提高了 grounding 的保真度和事实一致性,同时减少了幻觉,从而推动多模态问答朝着可信推理的方向发展。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在细粒度视觉问答中存在的幻觉问题,即模型无法准确识别图像中的物体身份、位置和关系。现有检索增强生成(RAG)方法虽然能缓解部分问题,但其主要关注全局图像信息,忽略了局部细节和细粒度交互,导致 grounding 不准确。
核心思路:论文的核心思路是模拟人类的视觉处理方式,将多模态推理过程分解为三个阶段:“what(是什么)”、“where(在哪里)”和“reweight(重新加权)”。通过这种级联方式,模型能够逐步聚焦于图像中的关键区域,并结合全局信息进行更准确的推理。
技术框架:HuLiRAG框架包含以下主要模块: 1. What (开放词汇检测):使用开放词汇检测器将查询锚定到图像中的候选参照物。 2. Where (SAM掩码):利用Segment Anything Model (SAM) 生成的掩码,在空间上解析候选参照物,恢复细粒度精度。 3. Reweight (局部-全局对齐):通过权衡局部和全局对齐程度,自适应地确定候选参照物的优先级。 4. 掩码引导微调:将空间证据注入到生成过程中,将 grounding 从被动偏差转变为对答案公式的显式约束。
关键创新:HuLiRAG的关键创新在于其模拟人类视觉处理的“what--where--reweight”级联框架。与传统的RAG方法相比,HuLiRAG更加关注图像的局部细节和细粒度交互,并通过空间信息显式地约束答案生成,从而提高了 grounding 的准确性和可靠性。
关键设计: 1. 使用开放词汇检测器(如CLIP)进行“what”阶段的参照物检测。 2. 利用SAM生成高质量的物体掩码,提供精确的空间信息。 3. 设计局部-全局对齐的权衡策略,平衡局部细节和全局上下文。 4. 通过掩码引导的微调,将空间信息融入到生成模型的训练中,提升模型的 grounding 能力。
🖼️ 关键图片


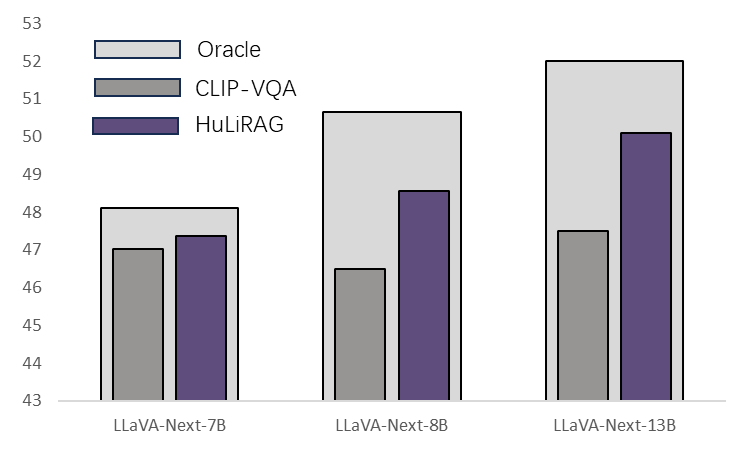
📊 实验亮点
实验结果表明,HuLiRAG框架在多项视觉问答任务中取得了显著的性能提升,有效地减少了幻觉现象,提高了 grounding 的保真度和事实一致性。具体性能数据(如准确率、F1值等)和对比基线(如传统RAG方法)的详细数值需要在论文中查找。
🎯 应用场景
HuLiRAG框架可应用于各种需要细粒度视觉理解的多模态任务,例如视觉问答、图像描述、目标定位和机器人导航。该研究有助于提升多模态大语言模型在实际应用中的可靠性和准确性,例如智能客服、自动驾驶和医疗诊断等领域。
📄 摘要(原文)
Multimodal large language models (MLLMs) often fail in fine-grained visual question answering, producing hallucinations about object identities, positions, and relations because textual queries are not explicitly anchored to visual referents. Retrieval-augmented generation (RAG) alleviates some errors, but it fails to align with human-like processing at both the retrieval and augmentation levels. Specifically, it focuses only on global-level image information but lacks local detail and limits reasoning about fine-grained interactions. To overcome this limitation, we present Human-Like Retrieval-Augmented Generation (HuLiRAG), a framework that stages multimodal reasoning as a ``what--where--reweight'' cascade. Queries are first anchored to candidate referents via open-vocabulary detection (what), then spatially resolved with SAM-derived masks to recover fine-grained precision (where), and adaptively prioritized through the trade-off between local and global alignment (reweight). Mask-guided fine-tuning further injects spatial evidence into the generation process, transforming grounding from a passive bias into an explicit constraint on answer formulation. Extensive experiments demonstrate that this human-like cascade improves grounding fidelity and factual consistency while reducing hallucinations, advancing multimodal question answering toward trustworthy reasoning.