From Programs to Poses: Factored Real-World Scene Generation via Learned Program Libraries
作者: Joy Hsu, Emily Jin, Jiajun Wu, Niloy J. Mitra
分类: cs.CV, cs.AI
发布日期: 2025-10-11
备注: NeurIPS 2025
💡 一句话要点
FactoredScenes:通过学习程序库生成可分解的真实世界场景,解决数据稀缺问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 场景生成 3D场景 程序化生成 大型语言模型 物体姿态估计
📋 核心要点
- 现有真实场景数据稀缺,难以生成具有多样物体姿态的逼真场景,阻碍了相关研究的进展。
- FactoredScenes通过学习房间布局模式和物体姿态变化,利用程序化生成方法合成逼真场景。
- 实验表明,FactoredScenes生成的场景与真实ScanNet场景难以区分,验证了其有效性。
📝 摘要(中文)
真实世界场景(如ScanNet)难以捕捉,可用数据非常有限。生成具有不同物体姿态的逼真场景仍然是一个开放且具有挑战性的任务。本文提出了FactoredScenes,一个通过利用房间的底层结构,同时学习居住场景中物体姿态的变化来合成逼真3D场景的框架。我们引入了一种分解表示,将场景分解为房间程序和物体姿态的分层组织概念。为了编码结构,FactoredScenes学习一个函数库,捕捉可重用的布局模式,从中绘制场景,然后使用大型语言模型生成由学习库正则化的高级程序。为了表示场景变化,FactoredScenes学习一个程序条件模型,以分层方式预测物体姿态,并在场景中检索和放置3D物体。我们表明,FactoredScenes生成逼真的真实世界房间,这些房间很难与真实的ScanNet场景区分开来。
🔬 方法详解
问题定义:现有方法在生成真实世界场景时,面临数据稀缺的挑战,难以捕捉场景中物体姿态的多样性。直接从有限的数据中学习生成模型,容易过拟合,导致生成结果不真实或缺乏泛化能力。因此,需要一种能够有效利用现有数据,并能生成具有真实感的场景的方法。
核心思路:FactoredScenes的核心思路是将场景分解为房间程序和物体姿态两个部分,分别进行建模。通过学习可重用的房间布局模式,并利用大型语言模型生成高级程序,从而编码场景的结构信息。同时,学习一个程序条件模型来预测物体姿态,从而捕捉场景的变化信息。这种分解表示方法能够有效利用现有数据,并生成具有真实感的场景。
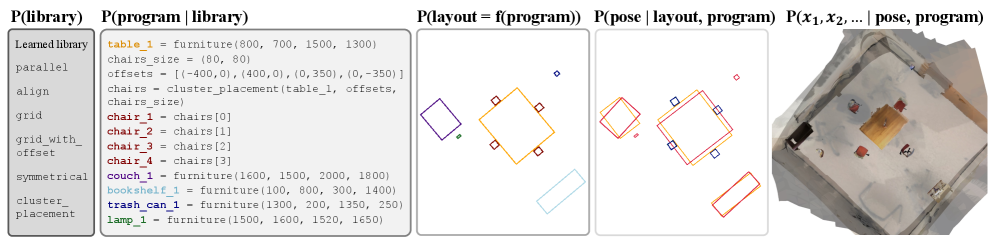
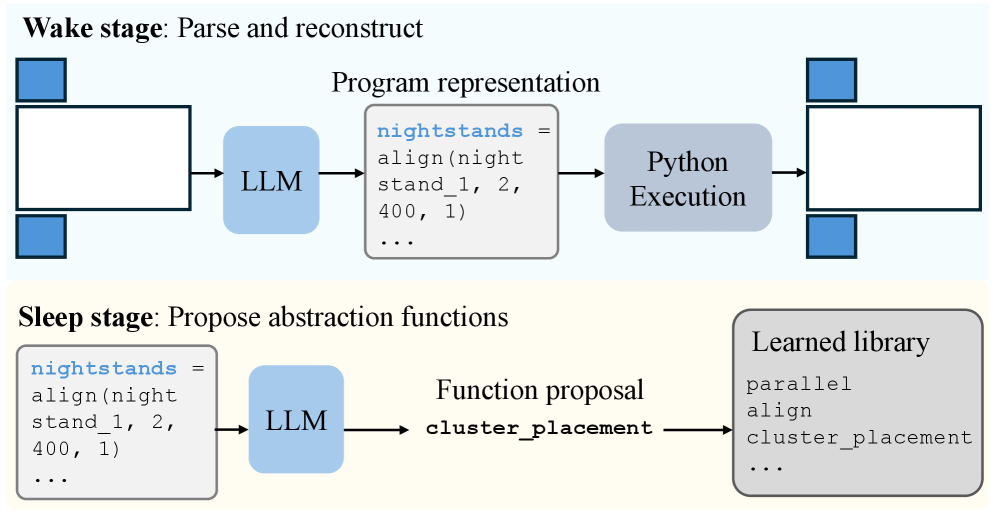
技术框架:FactoredScenes的整体框架包括以下几个主要模块:1) 房间布局模式学习模块:从现有数据中学习可重用的房间布局模式,构建函数库。2) 程序生成模块:利用大型语言模型生成高级程序,该程序描述了场景的布局结构,并受到学习到的函数库的正则化。3) 物体姿态预测模块:学习一个程序条件模型,根据生成的程序,分层预测场景中物体的姿态。4) 场景合成模块:根据预测的物体姿态,从物体库中检索并放置3D物体,最终合成完整的场景。
关键创新:FactoredScenes的关键创新在于其分解表示方法,将场景分解为房间程序和物体姿态两个部分。这种分解方法能够有效利用现有数据,并生成具有真实感的场景。此外,利用大型语言模型生成高级程序,并使用学习到的函数库进行正则化,能够保证生成程序的合理性和多样性。
关键设计:在房间布局模式学习模块中,使用了聚类算法来提取可重用的布局模式。在程序生成模块中,使用了Transformer模型作为大型语言模型。在物体姿态预测模块中,使用了分层预测方法,首先预测物体的大致位置,然后逐步细化姿态。损失函数包括重建损失和对抗损失,用于保证生成场景的真实感。
🖼️ 关键图片

📊 实验亮点
FactoredScenes生成的场景在视觉上与真实的ScanNet场景难以区分,表明其能够生成高度逼真的场景。通过与现有方法进行对比,FactoredScenes在场景真实感和多样性方面均取得了显著提升。此外,实验还验证了分解表示方法的有效性,表明其能够有效利用现有数据,并生成具有真实感的场景。
🎯 应用场景
FactoredScenes可应用于虚拟现实、游戏开发、机器人仿真等领域。通过生成逼真的3D场景,可以为用户提供沉浸式的体验,为游戏开发者提供丰富的资源,为机器人研究者提供真实的训练环境。此外,该方法还可以用于数据增强,扩充现有数据集,提高模型的泛化能力。未来,该方法有望应用于自动驾驶、智能家居等领域。
📄 摘要(原文)
Real-world scenes, such as those in ScanNet, are difficult to capture, with highly limited data available. Generating realistic scenes with varied object poses remains an open and challenging task. In this work, we propose FactoredScenes, a framework that synthesizes realistic 3D scenes by leveraging the underlying structure of rooms while learning the variation of object poses from lived-in scenes. We introduce a factored representation that decomposes scenes into hierarchically organized concepts of room programs and object poses. To encode structure, FactoredScenes learns a library of functions capturing reusable layout patterns from which scenes are drawn, then uses large language models to generate high-level programs, regularized by the learned library. To represent scene variations, FactoredScenes learns a program-conditioned model to hierarchically predict object poses, and retrieves and places 3D objects in a scene. We show that FactoredScenes generates realistic, real-world rooms that are difficult to distinguish from real ScanNet scenes.