Are Video Models Emerging as Zero-Shot Learners and Reasoners in Medical Imaging?
作者: Yuxiang Lai, Jike Zhong, Ming Li, Yuheng Li, Xiaofeng Yang
分类: cs.CV
发布日期: 2025-10-11
💡 一句话要点
视频模型展现医学影像零样本学习能力,为医学基础模型奠定基础
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像 零样本学习 视频模型 大型视觉模型 运动预测
📋 核心要点
- 现有医学影像任务依赖特定数据训练,泛化性差,缺乏跨任务统一模型。
- 利用大型视觉模型(LVM)的零样本能力,直接应用于医学影像的分割、去噪等任务。
- 实验表明,LVM在多个医学影像任务上表现出色,尤其在运动预测上超越现有方法。
📝 摘要(中文)
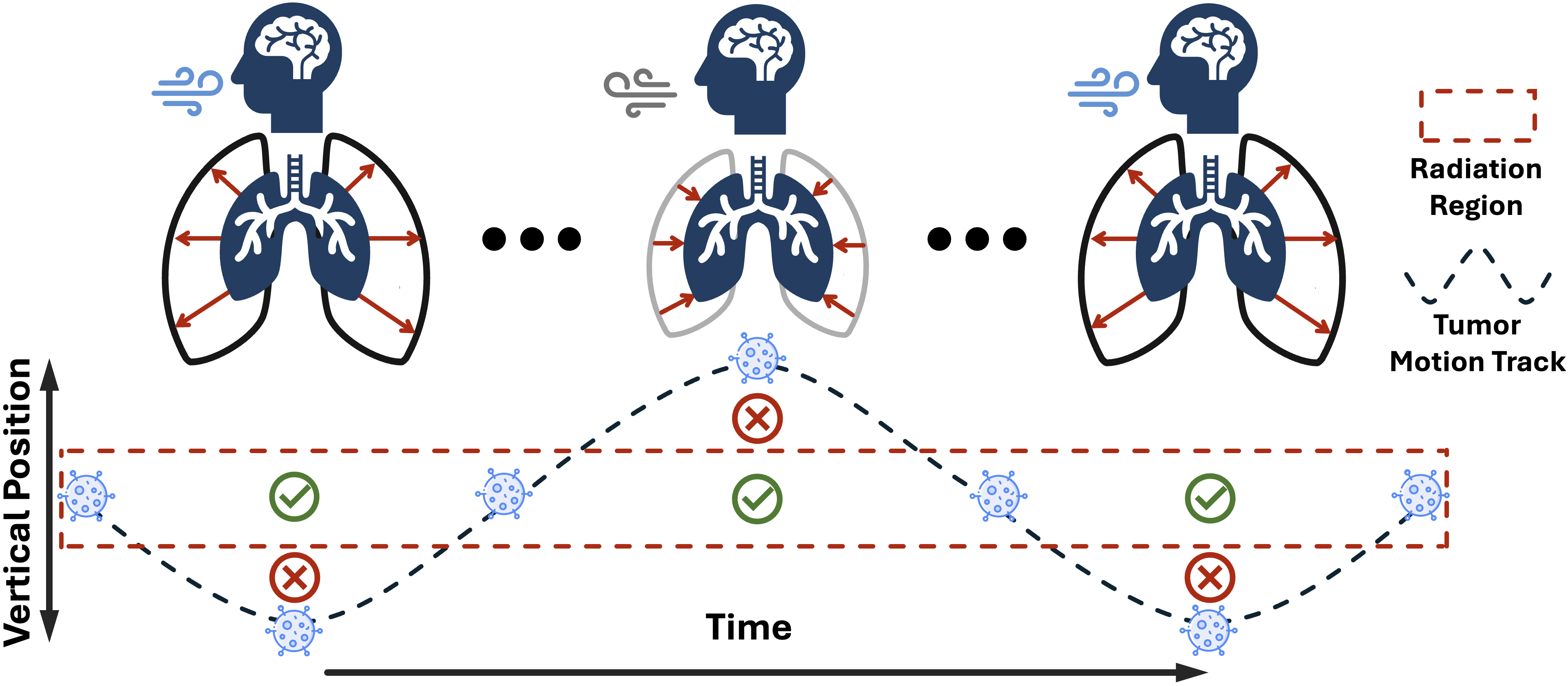
大型生成模型的最新进展表明,简单的自回归公式在适当扩展后,可以展现出强大的跨领域零样本泛化能力。受此趋势的启发,本文研究了自回归视频建模原理是否可以直接应用于医学影像任务,即使模型从未在医学数据上进行训练。具体而言,我们在器官分割、去噪、超分辨率和运动预测四个代表性任务中,以零样本方式评估了一个大型视觉模型(LVM)。令人惊讶的是,即使没有特定领域的微调,LVM也可以在CT扫描中描绘解剖结构,并在分割、去噪和超分辨率方面取得有竞争力的性能。最值得注意的是,在放射治疗运动预测中,该模型直接从4D CT扫描的先前相位预测未来的3D CT相位,产生解剖学上一致的预测,并以逼真的时间连贯性捕获患者特定的呼吸动力学。我们在来自122名患者的4D CT数据上评估了LVM,总计超过1,820个3D CT体。尽管没有事先接触过医学数据,但该模型在所有任务中均表现出强大的性能,并在运动预测中超越了基于DVF和生成模型的专业基线,实现了最先进的空间精度。这些发现揭示了医学视频建模中零样本能力的出现,并突出了通用视频模型作为统一学习器和推理器的潜力,为未来基于视频模型的医学基础模型奠定了基础。
🔬 方法详解
问题定义:论文旨在解决医学影像领域缺乏通用性强、无需大量特定数据训练的模型的问题。现有方法通常针对特定任务设计,泛化能力有限,且难以适应新的医学影像模态或疾病类型。这些方法往往需要大量的标注数据进行训练,成本高昂,且容易过拟合。
核心思路:论文的核心思路是利用大型视觉模型(LVM)在自然视频领域的强大泛化能力,将其直接应用于医学影像任务,无需进行特定领域的微调。LVM通过学习大量自然视频数据,获得了丰富的时空信息表征能力,可以将其迁移到医学影像领域,实现零样本学习。
技术框架:论文采用预训练的大型视觉模型(LVM),该模型基于自回归视频建模原理。在推理阶段,LVM接收医学影像数据作为输入,例如CT扫描图像序列,然后根据已有的图像信息预测未来的图像。整个过程无需任何针对医学影像数据的训练或微调。具体任务包括器官分割、去噪、超分辨率和运动预测。
关键创新:论文最重要的技术创新点在于证明了大型视觉模型在医学影像领域具有强大的零样本学习能力。与现有方法相比,该方法无需针对特定任务进行训练,即可在多个医学影像任务上取得有竞争力的性能。这为构建通用的医学影像基础模型提供了新的思路。
关键设计:论文的关键设计在于直接利用预训练的LVM,没有进行任何针对医学影像数据的修改或微调。在运动预测任务中,LVM接收一系列3D CT扫描图像作为输入,然后预测未来的3D CT扫描图像。模型的损失函数和网络结构等技术细节未在论文中详细描述,属于预训练LVM的固有属性。
🖼️ 关键图片

📊 实验亮点
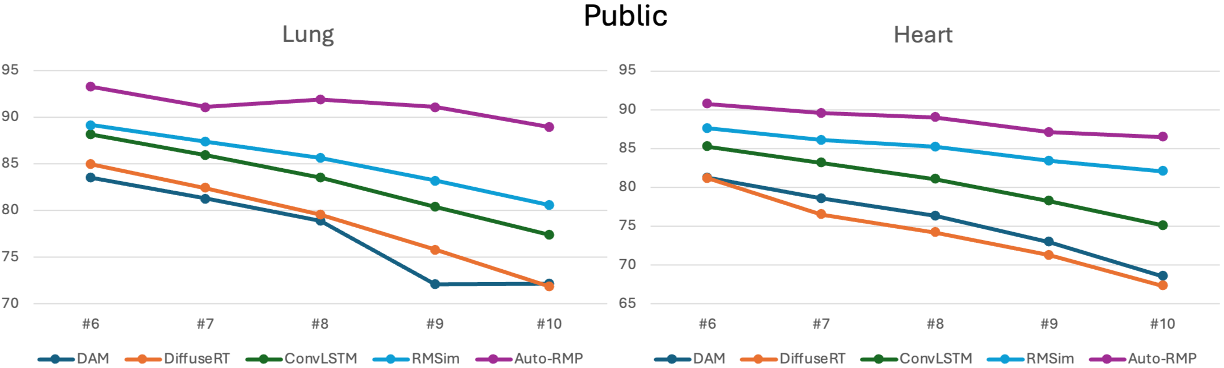
实验结果表明,LVM在器官分割、去噪和超分辨率等任务上取得了有竞争力的性能。在放射治疗运动预测任务中,LVM超越了基于DVF和生成模型的专业基线,实现了最先进的空间精度。具体而言,LVM能够准确预测患者的呼吸运动,为精确放疗提供重要支持。在122名患者的4D CT数据上进行了验证,证明了其有效性。
🎯 应用场景
该研究成果可应用于多种医学影像分析任务,如辅助诊断、治疗计划制定和术后评估。通过构建通用的医学影像基础模型,可以降低模型开发成本,加速新技术的应用,并最终改善患者的诊疗效果。未来,该方法有望扩展到其他医学影像模态和疾病类型,实现更广泛的应用。
📄 摘要(原文)
Recent advances in large generative models have shown that simple autoregressive formulations, when scaled appropriately, can exhibit strong zero-shot generalization across domains. Motivated by this trend, we investigate whether autoregressive video modeling principles can be directly applied to medical imaging tasks, despite the model never being trained on medical data. Specifically, we evaluate a large vision model (LVM) in a zero-shot setting across four representative tasks: organ segmentation, denoising, super-resolution, and motion prediction. Remarkably, even without domain-specific fine-tuning, the LVM can delineate anatomical structures in CT scans and achieve competitive performance on segmentation, denoising, and super-resolution. Most notably, in radiotherapy motion prediction, the model forecasts future 3D CT phases directly from prior phases of a 4D CT scan, producing anatomically consistent predictions that capture patient-specific respiratory dynamics with realistic temporal coherence. We evaluate the LVM on 4D CT data from 122 patients, totaling over 1,820 3D CT volumes. Despite no prior exposure to medical data, the model achieves strong performance across all tasks and surpasses specialized DVF-based and generative baselines in motion prediction, achieving state-of-the-art spatial accuracy. These findings reveal the emergence of zero-shot capabilities in medical video modeling and highlight the potential of general-purpose video models to serve as unified learners and reasoners laying the groundwork for future medical foundation models built on video models.