PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs
作者: Zixin Zhang, Kanghao Chen, Xingwang Lin, Lutao Jiang, Xu Zheng, Yuanhuiyi Lyu, Litao Guo, Yinchuan Li, Ying-Cong Chen
分类: cs.CV, cs.RO
发布日期: 2025-10-10
💡 一句话要点
PhysToolBench:首个用于评估MLLM物理工具理解能力的基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 物理工具理解 视觉问答 具身智能 基准测试 VQA数据集 工具识别
📋 核心要点
- 现有MLLM在具身智能和VLA模型中展现潜力,但对物理工具的理解程度缺乏量化评估。
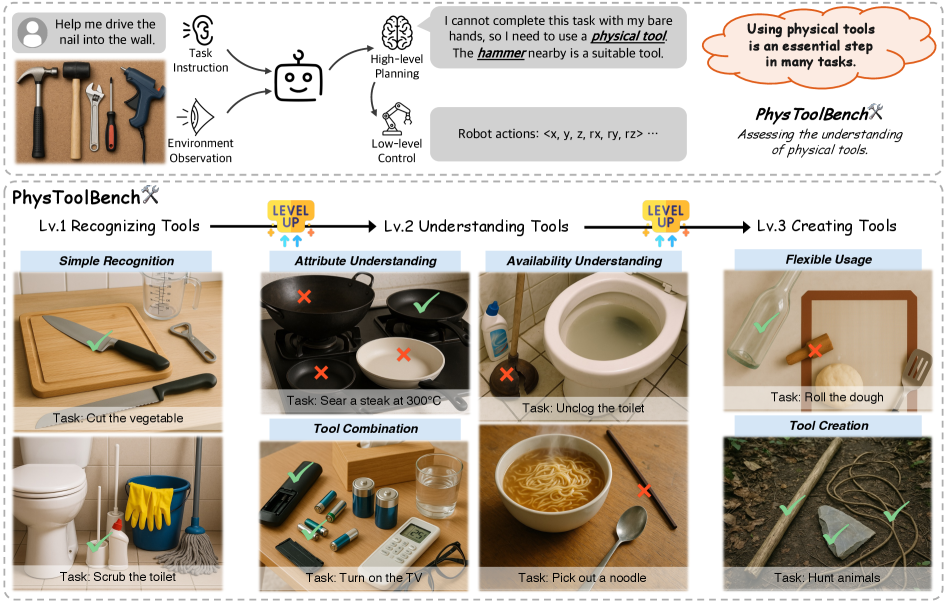
- PhysToolBench基准测试通过VQA数据集,从工具识别、理解和创造三个难度级别评估MLLM。
- 实验结果揭示了现有MLLM在工具理解方面的不足,并提出了初步的解决方案。
📝 摘要(中文)
工具的使用、理解和创造是人类智能的标志,能够实现与物理世界的复杂交互。为了使通用智能体实现真正的多功能性,必须掌握这些基本技能。虽然现代多模态大型语言模型(MLLM)利用其广泛的常识知识进行具身人工智能中的高层规划以及下游视觉-语言-动作(VLA)模型,但它们对物理工具的真正理解程度仍未量化。为了弥合这一差距,我们提出了PhysToolBench,这是第一个专门用于评估MLLM对物理工具理解能力的基准。我们的基准构建为一个视觉问答(VQA)数据集,包含1000多个图像-文本对。它评估了三个不同的难度级别:(1)工具识别:要求识别工具的主要功能。(2)工具理解:测试理解工具操作的基本原理的能力。(3)工具创造:当没有常规选项时,挑战模型利用周围物体制造新工具。我们对32个MLLM(包括专有模型、开源模型、专用具身模型和VLA中的骨干网络)的全面评估表明,工具理解方面存在重大缺陷。此外,我们提供了深入的分析并提出了初步解决方案。代码和数据集已公开。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)对物理工具理解能力缺乏有效评估的问题。现有方法无法准确衡量MLLM在工具识别、工具原理理解和工具创造方面的能力,阻碍了具身智能和视觉-语言-动作(VLA)模型的发展。
核心思路:论文的核心思路是构建一个专门的基准测试数据集PhysToolBench,该数据集包含视觉问答(VQA)形式的图像-文本对,涵盖工具识别、工具理解和工具创造三个难度级别。通过对MLLM在这些任务上的表现进行评估,可以量化其对物理工具的理解程度。
技术框架:PhysToolBench基准测试包含以下主要组成部分:1) 数据集构建:收集包含各种物理工具及其使用场景的图像,并设计相应的文本问题和答案。2) 难度分级:将问题分为工具识别、工具理解和工具创造三个难度级别,逐步考察MLLM的能力。3) 模型评估:选择一系列具有代表性的MLLM进行测试,包括专有模型、开源模型、专用具身模型和VLA骨干网络。4) 结果分析:对实验结果进行深入分析,找出MLLM在工具理解方面的优势和不足,并提出改进建议。
关键创新:该论文的关键创新在于提出了首个专门用于评估MLLM物理工具理解能力的基准测试PhysToolBench。该基准测试不仅提供了丰富的数据集,还设计了多层次的评估体系,能够全面、客观地衡量MLLM对物理工具的理解程度。
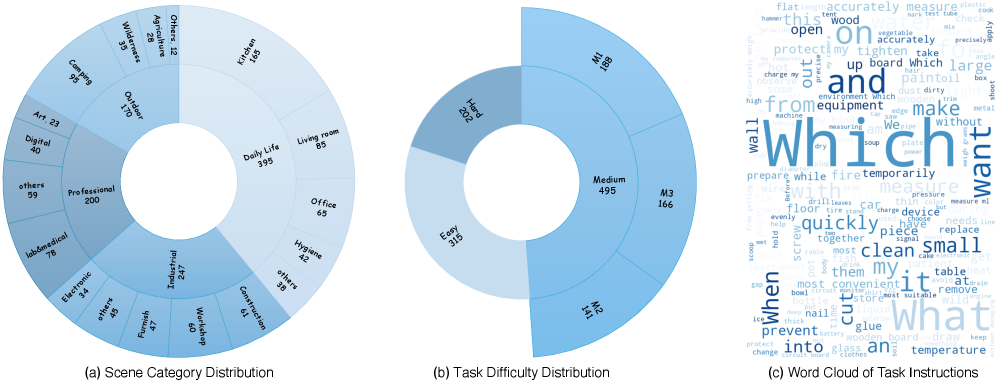
关键设计:PhysToolBench数据集包含超过1000个图像-文本对,涵盖了各种常见的物理工具。问题设计注重考察MLLM对工具功能、操作原理和创造性使用的理解。评估指标包括准确率、召回率等。论文还对不同类型的MLLM进行了详细的对比分析,并针对性地提出了改进建议。
🖼️ 关键图片
📊 实验亮点
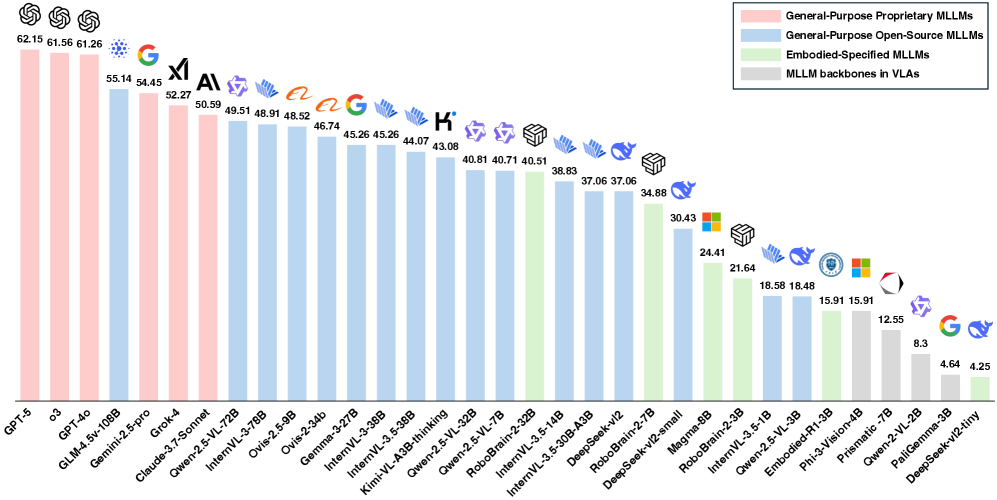
对32个MLLM的评估显示,模型在工具理解方面存在显著不足。PhysToolBench的评估结果为后续研究提供了重要的参考,并为改进MLLM的工具理解能力指明了方向。该基准测试的发布将促进相关领域的发展。
🎯 应用场景
该研究成果可应用于机器人、智能家居、自动驾驶等领域,提升智能体与物理环境的交互能力。通过提高MLLM对工具的理解能力,可以使智能体更好地完成各种任务,例如物体操作、场景理解和问题解决,从而实现更智能、更高效的人机协作。
📄 摘要(原文)
The ability to use, understand, and create tools is a hallmark of human intelligence, enabling sophisticated interaction with the physical world. For any general-purpose intelligent agent to achieve true versatility, it must also master these fundamental skills. While modern Multimodal Large Language Models (MLLMs) leverage their extensive common knowledge for high-level planning in embodied AI and in downstream Vision-Language-Action (VLA) models, the extent of their true understanding of physical tools remains unquantified. To bridge this gap, we present PhysToolBench, the first benchmark dedicated to evaluating the comprehension of physical tools by MLLMs. Our benchmark is structured as a Visual Question Answering (VQA) dataset comprising over 1,000 image-text pairs. It assesses capabilities across three distinct difficulty levels: (1) Tool Recognition: Requiring the recognition of a tool's primary function. (2) Tool Understanding: Testing the ability to grasp the underlying principles of a tool's operation. (3) Tool Creation: Challenging the model to fashion a new tool from surrounding objects when conventional options are unavailable. Our comprehensive evaluation of 32 MLLMs-spanning proprietary, open-source, specialized embodied, and backbones in VLAs-reveals a significant deficiency in tool understanding. Furthermore, we provide an in-depth analysis and propose preliminary solutions. Code and dataset are publicly available.