Dream to Recall: Imagination-Guided Experience Retrieval for Memory-Persistent Vision-and-Language Navigation
作者: Yunzhe Xu, Yiyuan Pan, Zhe Liu
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-10-09
备注: 14 pages, 6 figures, 13 tables
🔗 代码/项目: GITHUB
💡 一句话要点
Memoir:提出基于想象引导的经验检索,提升记忆持久性视觉语言导航性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 记忆持久性 经验检索 世界模型 想象引导
📋 核心要点
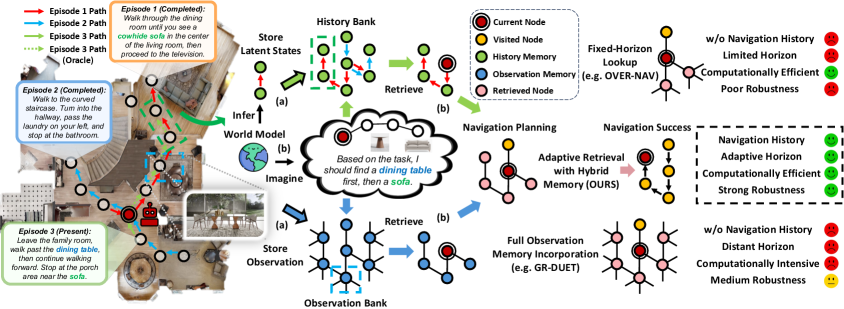
- 现有记忆持久性VLN方法缺乏有效的记忆访问机制,且忽略了导航行为模式中蕴含的决策信息。
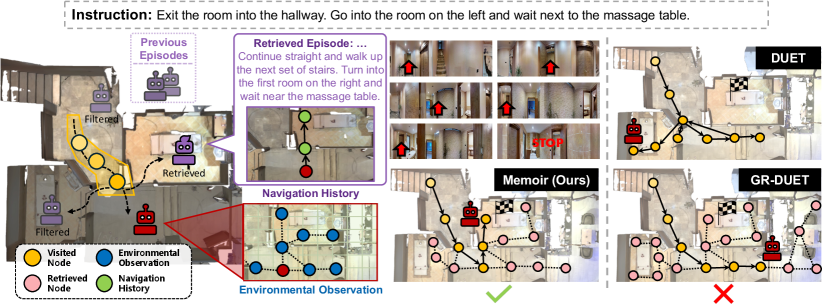
- Memoir利用语言条件的世界模型想象未来状态,作为检索查询,选择性地检索环境观察和行为历史。
- 实验表明,Memoir在多个记忆持久性VLN基准测试中显著提升了导航性能,并大幅提高了训练速度和降低了推理内存。
📝 摘要(中文)
视觉语言导航(VLN)要求智能体在环境中遵循自然语言指令,而记忆持久性变体则需要通过积累的经验逐步改进。现有的记忆持久性VLN方法面临关键限制:缺乏有效的记忆访问机制,依赖于整个记忆的整合或固定范围的查找,并且主要存储环境观察,忽略了编码有价值决策策略的导航行为模式。我们提出了Memoir,它采用想象作为由显式记忆支持的检索机制:一个世界模型想象未来的导航状态作为查询,以选择性地检索相关的环境观察和行为历史。该方法包括:1)一个语言条件的世界模型,想象未来状态,具有双重目的:编码经验以供存储和生成检索查询;2)混合视点级别记忆,将观察和行为模式锚定到视点,从而实现混合检索;3)一个经验增强的导航模型,通过专门的编码器整合检索到的知识。在具有10个不同测试场景的各种记忆持久性VLN基准上的广泛评估证明了Memoir的有效性:在所有场景中都有显着改进,在IR2R上比最佳记忆持久性基线提高了5.4%的SPL,同时训练速度提高了8.3倍,推理内存减少了74%。结果验证了对环境和行为记忆的预测性检索能够实现更有效的导航,分析表明这种想象引导的范例具有很大的提升空间(73.3% vs 93.4%上限)。代码位于https://github.com/xyz9911/Memoir。
🔬 方法详解
问题定义:现有的记忆持久性视觉语言导航(VLN)方法在利用历史经验方面存在不足。它们要么简单地将所有历史信息整合,要么采用固定范围的查找,缺乏选择性地访问和利用相关历史经验的能力。此外,现有方法主要关注环境观察,忽略了导航过程中蕴含的决策行为模式,这些模式包含了有价值的导航策略信息。
核心思路:Memoir的核心思想是利用“想象”作为一种检索机制,通过一个世界模型来预测未来的导航状态,并将这些预测的未来状态作为查询,从记忆中检索相关的环境观察和行为历史。这种基于想象的检索方式能够更有效地选择和利用历史经验,从而提升导航性能。
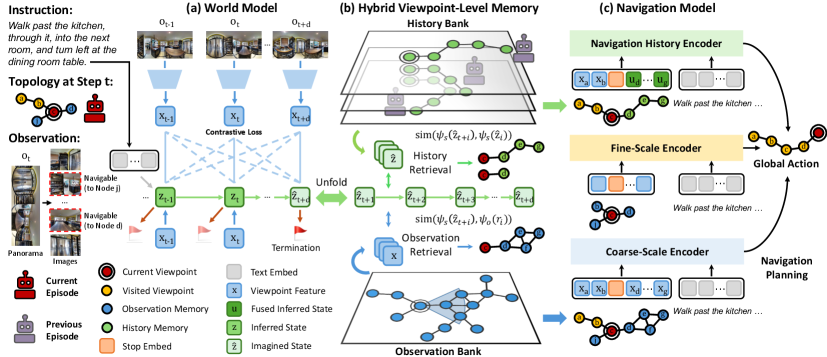
技术框架:Memoir的整体架构包含三个主要模块:1)语言条件的世界模型:该模型以语言指令为条件,预测未来的导航状态,同时用于编码经验并生成检索查询。2)混合视点级别记忆:该记忆模块将环境观察和行为模式都锚定到视点,从而实现混合检索。3)经验增强的导航模型:该模型通过专门的编码器整合检索到的知识,用于指导导航决策。
关键创新:Memoir最重要的技术创新点在于其基于想象的检索机制。与现有方法不同,Memoir不是简单地整合所有历史信息或采用固定范围的查找,而是利用世界模型预测未来状态,并将其作为查询来检索相关的历史经验。这种方式能够更有效地选择和利用历史经验,从而提升导航性能。此外,混合视点级别记忆的设计也使得Memoir能够同时检索环境观察和行为模式,从而更全面地利用历史经验。
关键设计:世界模型采用Transformer架构,以语言指令和当前状态为输入,预测未来的状态。混合视点级别记忆采用键值对存储,键为视点特征,值为环境观察和行为模式的嵌入表示。检索过程采用余弦相似度计算查询和记忆之间的相关性,并选择最相关的记忆进行整合。损失函数包括世界模型的预测损失和导航模型的导航损失。
🖼️ 关键图片
📊 实验亮点
Memoir在多个记忆持久性VLN基准测试中取得了显著的性能提升。在IR2R数据集上,Memoir比最佳记忆持久性基线提高了5.4%的SPL。此外,Memoir还大幅提高了训练速度(8.3倍)和降低了推理内存(74%)。这些结果表明,Memoir提出的基于想象引导的经验检索方法能够有效地提升导航性能,并具有较高的效率。
🎯 应用场景
Memoir的研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。通过利用历史经验,智能体可以更好地理解环境、预测未来状态,并做出更明智的导航决策。该研究对于提升智能体的自主性和适应性具有重要意义,并有望在实际应用中发挥重要作用。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) requires agents to follow natural language instructions through environments, with memory-persistent variants demanding progressive improvement through accumulated experience. Existing approaches for memory-persistent VLN face critical limitations: they lack effective memory access mechanisms, instead relying on entire memory incorporation or fixed-horizon lookup, and predominantly store only environmental observations while neglecting navigation behavioral patterns that encode valuable decision-making strategies. We present Memoir, which employs imagination as a retrieval mechanism grounded by explicit memory: a world model imagines future navigation states as queries to selectively retrieve relevant environmental observations and behavioral histories. The approach comprises: 1) a language-conditioned world model that imagines future states serving dual purposes: encoding experiences for storage and generating retrieval queries; 2) Hybrid Viewpoint-Level Memory that anchors both observations and behavioral patterns to viewpoints, enabling hybrid retrieval; and 3) an experience-augmented navigation model that integrates retrieved knowledge through specialized encoders. Extensive evaluation across diverse memory-persistent VLN benchmarks with 10 distinctive testing scenarios demonstrates Memoir's effectiveness: significant improvements across all scenarios, with 5.4% SPL gains on IR2R over the best memory-persistent baseline, accompanied by 8.3x training speedup and 74% inference memory reduction. The results validate that predictive retrieval of both environmental and behavioral memories enables more effective navigation, with analysis indicating substantial headroom (73.3% vs 93.4% upper bound) for this imagination-guided paradigm. Code at https://github.com/xyz9911/Memoir.