Gaze on the Prize: Shaping Visual Attention with Return-Guided Contrastive Learning
作者: Andrew Lee, Ian Chuang, Dechen Gao, Kai Fukazawa, Iman Soltani
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-10-09 (更新: 2025-12-12)
备注: Project page: https://andrewcwlee.github.io/gaze-on-the-prize
💡 一句话要点
提出基于回报引导对比学习的视觉注意力机制,提升强化学习样本效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉强化学习 注意力机制 对比学习 自监督学习 回报引导
📋 核心要点
- 视觉强化学习中,智能体常因图像数据中无关像素而浪费资源,导致学习效率低下。
- 论文提出Gaze on the Prize框架,利用回报差异引导注意力机制,聚焦任务相关特征。
- 实验表明,该方法显著提升样本效率,并在复杂任务中超越基线方法,无需调整算法或超参数。
📝 摘要(中文)
视觉强化学习(RL)智能体必须基于高维图像数据进行学习,而其中只有一小部分像素与任务相关。这迫使智能体在不相关的特征上浪费探索和计算资源,导致样本效率低下和学习不稳定。为了解决这个问题,受到人类视觉注视的启发,我们引入了“Gaze on the Prize”框架。该框架通过一个可学习的注视注意力机制(Gaze)来增强视觉RL,该机制由来自智能体追求更高回报的经验的自监督信号引导。我们的关键见解是,回报差异揭示了什么最重要:如果两个相似的表征产生不同的结果,那么它们的不同特征很可能与任务相关,并且注视应该相应地关注它们。这是通过回报引导的对比学习来实现的,该学习训练注意力以区分与成功和失败相关的特征。我们根据它们的回报差异将相似的视觉表征分组为正例和负例,并使用生成的标签来构建对比三元组。这些三元组提供了训练信号,该信号教导注意力机制为与不同结果相关的状态生成可区分的表征。我们的方法在样本效率方面实现了高达2.52倍的改进,并且可以解决来自ManiSkill3基准测试中的具有挑战性的任务,而基线算法无法学习,而无需修改底层算法或超参数。
🔬 方法详解
问题定义:视觉强化学习智能体在处理高维图像输入时,面临着大量与任务无关的像素信息干扰,导致智能体需要花费大量的探索和计算资源来学习哪些特征是真正重要的。现有的方法通常难以有效地从高维图像中提取关键信息,导致样本效率低下,学习过程不稳定。
核心思路:论文的核心思路是模仿人类的视觉注视机制,设计一个可学习的注意力机制,使其能够根据智能体获得的奖励差异来聚焦于图像中与任务相关的特征。通过对比学习,区分导致成功和失败的关键视觉特征,从而引导智能体更有效地学习。
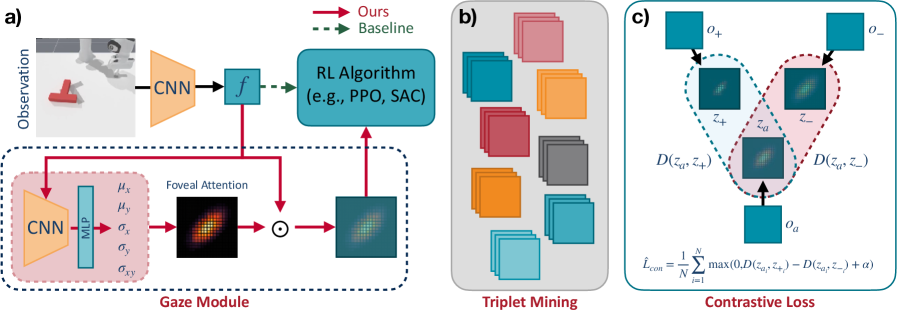
技术框架:整体框架包括一个视觉强化学习智能体和一个可学习的注视注意力机制(Gaze)。智能体与环境交互,收集经验数据。Gaze模块接收智能体的视觉表征作为输入,并输出一个注意力权重,用于聚焦于图像中的关键区域。然后,智能体基于加权后的视觉信息进行决策。Gaze模块通过回报引导的对比学习进行训练。
关键创新:最重要的技术创新点在于利用回报差异来指导注意力机制的学习。传统的注意力机制通常依赖于人工标注或预训练模型,而该方法通过智能体自身的经验来学习哪些特征与任务成功相关,从而实现自监督学习。这种方法能够更有效地适应不同的任务和环境。
关键设计:关键设计包括:1) 使用对比学习构建三元组,其中正例是具有相似视觉表征但获得较高回报的状态,负例是具有相似视觉表征但获得较低回报的状态。2) 使用InfoNCE损失函数来训练Gaze模块,使其能够区分正例和负例。3) Gaze模块的网络结构可以采用卷积神经网络或Transformer等模型,具体结构根据任务的复杂程度进行选择。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在ManiSkill3基准测试中取得了显著的性能提升,样本效率最高提升了2.52倍。此外,该方法还成功解决了基线算法无法学习的具有挑战性的任务,证明了其在复杂环境中的有效性。值得注意的是,该方法在提升性能的同时,无需修改底层算法或超参数。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、游戏AI等领域。通过提升视觉强化学习的样本效率,可以降低训练成本,加速智能体在复杂环境中的学习过程。未来,该方法有望扩展到其他模态的数据,例如语音和文本,从而实现更通用的智能体学习框架。
📄 摘要(原文)
Visual Reinforcement Learning (RL) agents must learn to act based on high-dimensional image data where only a small fraction of the pixels is task-relevant. This forces agents to waste exploration and computational resources on irrelevant features, leading to sample-inefficient and unstable learning. To address this, inspired by human visual foveation, we introduce Gaze on the Prize. This framework augments visual RL with a learnable foveal attention mechanism (Gaze), guided by a self-supervised signal derived from the agent's experience pursuing higher returns (the Prize). Our key insight is that return differences reveal what matters most: If two similar representations produce different outcomes, their distinguishing features are likely task-relevant, and the gaze should focus on them accordingly. This is realized through return-guided contrastive learning that trains the attention to distinguish between the features relevant to success and failure. We group similar visual representations into positives and negatives based on their return differences and use the resulting labels to construct contrastive triplets. These triplets provide the training signal that teaches the attention mechanism to produce distinguishable representations for states associated with different outcomes. Our method achieves up to 2.52x improvement in sample efficiency and can solve challenging tasks from the ManiSkill3 benchmark that the baseline fails to learn, without modifying the underlying algorithm or hyperparameters.