OmniSAT: Compact Action Token, Faster Auto Regression
作者: Huaihai Lyu, Chaofan Chen, Senwei Xie, Pengwei Wang, Xiansheng Chen, Shanghang Zhang, Changsheng Xu
分类: cs.CV, cs.RO
发布日期: 2025-10-08
💡 一句话要点
OmniSAT:紧凑动作Token,加速自回归视觉-语言-动作模型训练
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 自回归模型 动作token化 残差量化 跨具身学习
📋 核心要点
- 现有自回归VLA模型在处理长动作序列时效率较低,压缩方法又难以保证重建质量。
- 提出Omni Swift Action Tokenizer,学习紧凑且可迁移的动作表示,实现高效压缩。
- 实验表明,OmniSAT能显著缩短训练序列,加速收敛,并在真实机器人和模拟环境中提升性能。
📝 摘要(中文)
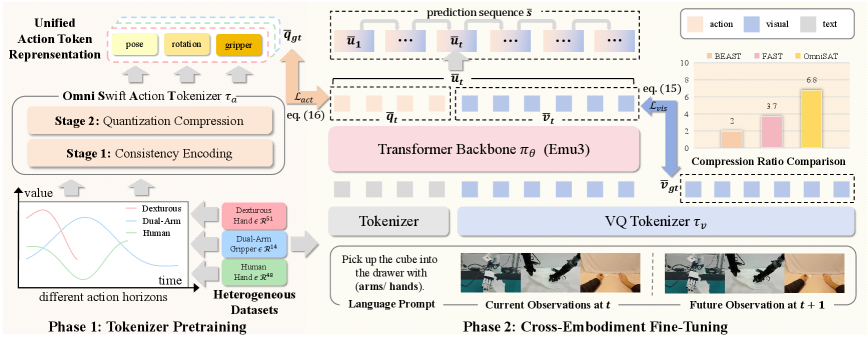
现有的视觉-语言-动作(VLA)模型主要分为基于扩散和自回归(AR)两种方法:扩散模型能够捕捉连续的动作分布,但依赖于计算量大的迭代去噪过程。相比之下,AR模型能够实现高效优化和灵活的序列构建,更适合大规模预训练。为了进一步提高AR效率,特别是在动作块导致扩展和高维序列时,之前的工作应用了熵引导和token频率技术来缩短序列长度。然而,这种压缩方法存在重建质量差或压缩效率低的问题。受此启发,我们引入了一种Omni Swift Action Tokenizer,它可以学习一种紧凑的、可迁移的动作表示。具体来说,我们首先对值范围和时间范围进行归一化,以获得与B样条编码一致的表示。然后,我们将多阶段残差量化应用于位置、旋转和夹持器子空间,为每个部分生成具有粗到细粒度的压缩离散token。经过在大型数据集Droid上进行预训练后,由此产生的离散token化将训练序列缩短了6.8倍,并降低了目标熵。为了进一步探索OmniSAT的潜力,我们开发了一种跨具身学习策略,该策略建立在统一的动作模式空间上,并联合利用机器人和人类演示。它能够实现来自异构第一人称视角视频的可扩展辅助监督。在各种真实机器人和模拟实验中,OmniSAT实现了更高的压缩率,同时保持了重建质量,从而加快了AR训练的收敛速度和模型性能。
🔬 方法详解
问题定义:现有自回归(AR)视觉-语言-动作(VLA)模型在处理长动作序列时面临效率瓶颈。直接使用原始动作数据会导致序列过长,计算复杂度高。虽然一些方法尝试通过熵引导或token频率进行压缩,但往往牺牲了动作重建的质量,或者压缩效率不高,无法有效降低训练成本。
核心思路:论文的核心思路是设计一种高效的动作token化方法,将连续的动作空间映射到离散的、紧凑的token空间。通过学习一种可迁移的动作表示,在保证重建质量的前提下,显著缩短动作序列的长度,从而加速自回归模型的训练和推理。
技术框架:OmniSAT的整体框架包含以下几个主要阶段:1) 动作数据预处理:对动作数据进行归一化,包括值范围和时间范围的归一化,以获得一致的表示。2) B-Spline编码:使用B样条编码对动作轨迹进行参数化表示。3) 多阶段残差量化:将动作空间分解为位置、旋转和夹持器子空间,并对每个子空间应用多阶段残差量化,生成离散的动作token。4) 自回归模型训练:使用生成的离散token训练自回归模型。5) 跨具身学习:利用机器人和人类演示数据进行联合训练,提升模型的泛化能力。
关键创新:OmniSAT的关键创新在于其动作token化方法,即Omni Swift Action Tokenizer。该tokenizer通过多阶段残差量化,实现了对动作空间的高效压缩,同时保留了动作的细节信息。与现有的压缩方法相比,OmniSAT能够在更高的压缩率下保持更好的重建质量。此外,跨具身学习策略也是一个创新点,它利用人类演示数据作为辅助监督,提升了模型的泛化能力。
关键设计:在多阶段残差量化中,论文针对位置、旋转和夹持器子空间分别设计了不同的量化器。量化器的数量和每个量化器的码本大小是关键的参数。此外,损失函数的设计也至关重要,需要平衡压缩率和重建质量。论文还采用了B-Spline编码来平滑动作轨迹,并使用残差量化来逐步逼近原始动作,从而提高重建精度。跨具身学习中,如何有效融合机器人和人类演示数据也是一个关键的设计问题。
🖼️ 关键图片


📊 实验亮点
OmniSAT在Droid数据集上预训练后,将训练序列缩短了6.8倍,并降低了目标熵。在真实机器人和模拟实验中,OmniSAT实现了更高的压缩率,同时保持了重建质量,从而加快了AR训练的收敛速度和模型性能。这些结果表明,OmniSAT是一种高效且有效的动作token化方法。
🎯 应用场景
OmniSAT具有广泛的应用前景,可用于机器人控制、自动化、游戏AI等领域。通过高效的动作token化,可以降低VLA模型的训练成本,加速模型部署。跨具身学习策略使得模型能够利用人类的经验,从而更好地适应复杂环境。该研究有望推动机器人自主学习和人机协作的发展。
📄 摘要(原文)
Existing Vision-Language-Action (VLA) models can be broadly categorized into diffusion-based and auto-regressive (AR) approaches: diffusion models capture continuous action distributions but rely on computationally heavy iterative denoising. In contrast, AR models enable efficient optimization and flexible sequence construction, making them better suited for large-scale pretraining. To further improve AR efficiency, particularly when action chunks induce extended and high-dimensional sequences, prior work applies entropy-guided and token-frequency techniques to shorten the sequence length. However, such compression struggled with \textit{poor reconstruction or inefficient compression}. Motivated by this, we introduce an Omni Swift Action Tokenizer, which learns a compact, transferable action representation. Specifically, we first normalize value ranges and temporal horizons to obtain a consistent representation with B-Spline encoding. Then, we apply multi-stage residual quantization to the position, rotation, and gripper subspaces, producing compressed discrete tokens with coarse-to-fine granularity for each part. After pre-training on the large-scale dataset Droid, the resulting discrete tokenization shortens the training sequence by 6.8$\times$, and lowers the target entropy. To further explore the potential of OmniSAT, we develop a cross-embodiment learning strategy that builds on the unified action-pattern space and jointly leverages robot and human demonstrations. It enables scalable auxiliary supervision from heterogeneous egocentric videos. Across diverse real-robot and simulation experiments, OmniSAT encompasses higher compression while preserving reconstruction quality, enabling faster AR training convergence and model performance.