GAZE:Governance-Aware pre-annotation for Zero-shot World Model Environments
作者: Leela Krishna, Mengyang Zhao, Saicharithreddy Pasula, Harshit Rajgarhia, Abhishek Mukherji
分类: cs.CV, cs.AI
发布日期: 2025-10-07
💡 一句话要点
GAZE:面向零样本世界模型的治理感知预标注流水线
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 预标注 自动化标注 多模态数据 隐私保护 数据治理 长视频处理
📋 核心要点
- 世界模型训练需要大规模、精确标注的多模态数据集,而人工标注效率低、成本高是瓶颈。
- GAZE流水线通过AI模型自动预标注,并整合隐私保护和监管链元数据,生成高质量训练数据。
- GAZE显著提升了标注效率,减少人工审核量,并生成高保真、隐私感知的数据集。
📝 摘要(中文)
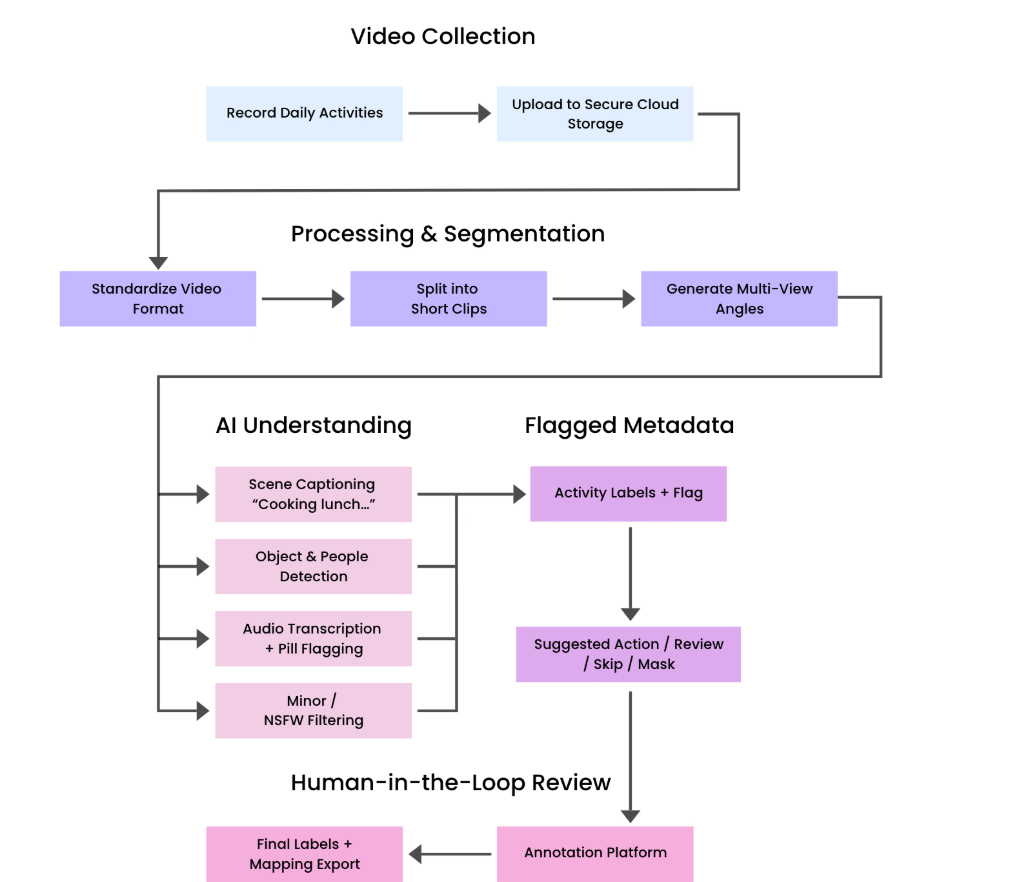
本文提出了一种名为GAZE的流水线,用于自动将原始长视频转换为富含信息的、可用于世界模型训练的标注数据。该系统首先将专有的360度视频格式标准化为标准视图并分片以进行并行处理;然后应用一系列AI模型(场景理解、目标跟踪、音频转录、PII/NSFW/未成年人检测)进行密集的、多模态的预标注;最后将这些信号整合为结构化的输出,以便快速的人工验证。GAZE工作流程显著提高了效率(每小时节省约19分钟的审核时间),并通过保守地自动跳过低显著性片段,减少了80%以上的人工审核量。该方法在提高标签密度和一致性的同时,集成了隐私保护措施和监管链元数据,从而生成可直接用于学习跨模态动态和动作条件预测的高保真、隐私感知数据集。本文详细介绍了流程编排、模型选择和数据字典,为生成高质量的世界模型训练数据提供了一个可扩展的蓝图,且不牺牲吞吐量或治理。
🔬 方法详解
问题定义:世界模型需要大量标注数据进行训练,但人工标注成本高、效率低,且难以保证数据质量和隐私安全。现有方法难以兼顾标注效率、数据质量和隐私保护。
核心思路:利用AI模型进行自动预标注,减少人工干预,提高标注效率。同时,通过隐私检测和监管链元数据,保证数据安全和可追溯性。核心在于构建一个自动化、可扩展、治理感知的标注流水线。
技术框架:GAZE流水线包含以下主要模块:1) 360度视频标准化和分片;2) AI模型预标注(场景理解、目标跟踪、音频转录、PII/NSFW/未成年人检测);3) 标注信号整合和结构化输出;4) 人工验证和修正。
关键创新:GAZE的关键创新在于:1) 自动化预标注流程,显著减少人工干预;2) 集成隐私保护和监管链元数据,保证数据安全;3) 针对世界模型训练定制的数据格式和标注规范。
关键设计:GAZE的关键设计包括:1) 针对不同模态数据选择合适的AI模型;2) 设计保守的自动跳过策略,减少人工审核量;3) 定义清晰的数据字典和标注规范,保证数据一致性;4) 采用并行处理和分布式架构,提高吞吐量。
🖼️ 关键图片

📊 实验亮点
GAZE流水线显著提高了标注效率,每小时节省约19分钟的审核时间,并减少了80%以上的人工审核量。通过自动化预标注和隐私保护,生成了高保真、隐私感知的数据集,为世界模型训练提供了有力支持。这些结果表明,GAZE是一种高效、安全、可扩展的标注解决方案。
🎯 应用场景
该研究成果可广泛应用于机器人、自动驾驶、虚拟现实等领域,为这些领域的世界模型训练提供高质量、低成本的数据支持。通过自动化标注和隐私保护,可以加速相关技术的发展和应用,并降低数据安全风险。未来,该方法有望扩展到更多模态的数据标注,并应用于更广泛的人工智能任务。
📄 摘要(原文)
Training robust world models requires large-scale, precisely labeled multimodal datasets, a process historically bottlenecked by slow and expensive manual annotation. We present a production-tested GAZE pipeline that automates the conversion of raw, long-form video into rich, task-ready supervision for world-model training. Our system (i) normalizes proprietary 360-degree formats into standard views and shards them for parallel processing; (ii) applies a suite of AI models (scene understanding, object tracking, audio transcription, PII/NSFW/minor detection) for dense, multimodal pre-annotation; and (iii) consolidates signals into a structured output specification for rapid human validation. The GAZE workflow demonstrably yields efficiency gains (~19 minutes saved per review hour) and reduces human review volume by >80% through conservative auto-skipping of low-salience segments. By increasing label density and consistency while integrating privacy safeguards and chain-of-custody metadata, our method generates high-fidelity, privacy-aware datasets directly consumable for learning cross-modal dynamics and action-conditioned prediction. We detail our orchestration, model choices, and data dictionary to provide a scalable blueprint for generating high-quality world model training data without sacrificing throughput or governance.