Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding
作者: Yi Xin, Qi Qin, Siqi Luo, Kaiwen Zhu, Juncheng Yan, Yan Tai, Jiayi Lei, Yuewen Cao, Keqi Wang, Yibin Wang, Jinbin Bai, Qian Yu, Dengyang Jiang, Yuandong Pu, Haoxing Chen, Le Zhuo, Junjun He, Gen Luo, Tianbin Li, Ming Hu, Jin Ye, Shenglong Ye, Bo Zhang, Chang Xu, Wenhai Wang, Hongsheng Li, Guangtao Zhai, Tianfan Xue, Bin Fu, Xiaohong Liu, Yu Qiao, Yihao Liu
分类: cs.CV
发布日期: 2025-10-07
备注: 33 pages, 13 figures, 10 tables
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Lumina-DiMOO:一种用于多模态生成与理解的Omni扩散大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态生成 扩散模型 离散扩散 文本到图像 图像编辑 图像理解 大语言模型
📋 核心要点
- 现有统一多模态模型在处理不同模态数据时效率较低,且难以支持广泛的任务。
- Lumina-DiMOO采用全离散扩散建模,统一处理多模态输入输出,提升采样效率并扩展任务范围。
- 实验表明,Lumina-DiMOO在多项基准测试中超越现有开源模型,达到SOTA性能。
📝 摘要(中文)
本文介绍Lumina-DiMOO,一个用于无缝多模态生成和理解的开源基础模型。Lumina-DiMOO通过利用完全离散的扩散建模来处理各种模态的输入和输出,从而区别于先前的统一模型。这种创新方法使Lumina-DiMOO能够实现比以前的自回归(AR)或混合AR-扩散范例更高的采样效率,并熟练地支持广泛的多模态任务,包括文本到图像生成、图像到图像生成(例如,图像编辑、主题驱动生成和图像修复等)以及图像理解。Lumina-DiMOO在多个基准测试中实现了最先进的性能,超越了现有的开源统一多模态模型。为了促进多模态和离散扩散模型研究的进一步发展,我们将我们的代码和检查点发布给社区。
🔬 方法详解
问题定义:现有统一多模态模型通常采用自回归或混合自回归-扩散范式,这些方法在处理多种模态的数据时,采样效率较低,并且难以同时支持文本到图像生成、图像到图像生成和图像理解等多种任务。因此,如何设计一个高效且通用的多模态模型,成为一个重要的挑战。
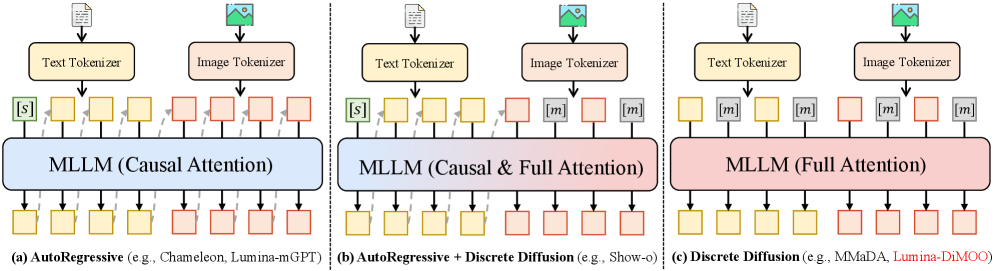
核心思路:Lumina-DiMOO的核心思路是利用完全离散的扩散建模来统一处理不同模态的输入和输出。通过将所有模态的数据都离散化,并使用扩散模型进行建模,可以实现高效的采样和生成,同时支持多种不同的多模态任务。这种方法避免了自回归模型的串行生成过程,从而提高了采样效率。
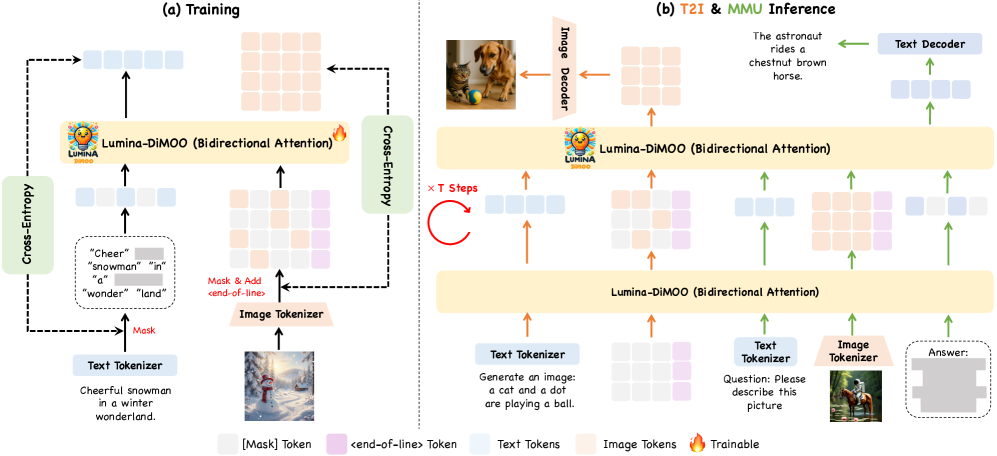
技术框架:Lumina-DiMOO的整体框架包含以下几个主要模块:1)模态编码器:将不同模态的输入数据(如文本、图像)编码成离散的表示;2)扩散模型:对离散的表示进行扩散和逆扩散过程,实现数据的生成和重建;3)模态解码器:将扩散模型生成的离散表示解码成目标模态的输出数据。整个流程通过扩散模型连接不同的模态,实现多模态的生成和理解。
关键创新:Lumina-DiMOO最重要的技术创新点在于其采用了完全离散的扩散建模方法。与现有的自回归或混合自回归-扩散模型相比,Lumina-DiMOO能够更高效地处理多模态数据,并且能够支持更广泛的任务。此外,该模型的设计也更加简洁和统一,易于扩展和改进。
关键设计:Lumina-DiMOO的关键设计包括:1)使用VQ-VAE等技术将图像等连续数据离散化;2)采用Transformer架构作为扩散模型的骨干网络,用于学习数据之间的依赖关系;3)设计合适的损失函数,用于训练扩散模型,例如交叉熵损失或负对数似然损失;4)通过调整扩散过程的步数和噪声水平,控制生成数据的质量和多样性。
🖼️ 关键图片

📊 实验亮点
Lumina-DiMOO在多个基准测试中取得了最先进的性能,超越了现有的开源统一多模态模型。具体而言,在文本到图像生成任务中,Lumina-DiMOO在FID和IS等指标上均优于其他开源模型。在图像编辑和图像修复等任务中,Lumina-DiMOO也展现出了强大的性能和泛化能力。
🎯 应用场景
Lumina-DiMOO具有广泛的应用前景,包括但不限于:图像编辑、主题驱动生成、图像修复、文本到图像生成、视觉内容创作、多模态人机交互等。该模型可以用于开发更智能的图像处理工具、更自然的对话系统,以及更具创造力的内容生成平台。未来,Lumina-DiMOO有望成为多模态人工智能领域的重要基石。
📄 摘要(原文)
We introduce Lumina-DiMOO, an open-source foundational model for seamless multi-modal generation and understanding. Lumina-DiMOO sets itself apart from prior unified models by utilizing a fully discrete diffusion modeling to handle inputs and outputs across various modalities. This innovative approach allows Lumina-DiMOO to achieve higher sampling efficiency compared to previous autoregressive (AR) or hybrid AR-Diffusion paradigms and adeptly support a broad spectrum of multi-modal tasks, including text-to-image generation, image-to-image generation (e.g., image editing, subject-driven generation, and image inpainting, etc.), as well as image understanding. Lumina-DiMOO achieves state-of-the-art performance on multiple benchmarks, surpassing existing open-source unified multi-modal models. To foster further advancements in multi-modal and discrete diffusion model research, we release our code and checkpoints to the community. Project Page: https://synbol.github.io/Lumina-DiMOO.