ChainMPQ: Interleaved Text-Image Reasoning Chains for Mitigating Relation Hallucinations
作者: Yike Wu, Yiwei Wang, Yujun Cai
分类: cs.CV, cs.AI
发布日期: 2025-10-07
💡 一句话要点
提出ChainMPQ,通过交错文本-图像推理链缓解关系幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 关系幻觉 多模态推理 交错推理链 知识推理
📋 核心要点
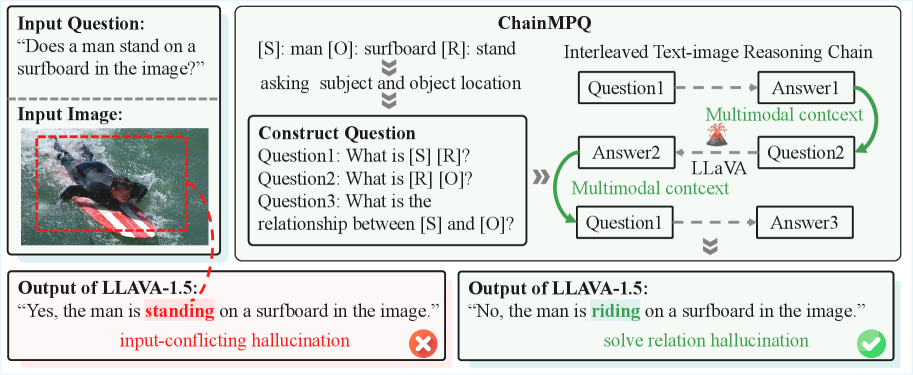
- 大型视觉语言模型存在关系幻觉问题,即错误地推断图像中对象之间的关系,降低了模型可靠性。
- ChainMPQ通过构建多视角问题,并利用图像和文本的交错推理链,逐步引导模型进行关系推理。
- 实验表明,ChainMPQ能有效减少关系幻觉,且消融实验验证了其核心模块的有效性。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)在多模态任务中表现出色,但幻觉问题仍然阻碍了它们的可靠性。在对象、属性和关系这三种幻觉类型中,关系幻觉占比最大,但受到的关注最少。为了解决这个问题,我们提出了一种名为ChainMPQ(多视角问题引导的图像和文本交错链)的免训练方法,该方法通过利用累积的文本和视觉记忆来改进LVLMs中的关系推理。ChainMPQ首先从问题中提取主语和宾语关键词,以增强相应的图像区域。然后,它构建多视角问题,重点关注关系中的三个核心组成部分:主语、宾语以及连接它们的关系。这些问题被顺序输入到模型中,来自先前步骤的文本和视觉记忆为后续步骤提供支持上下文,从而形成图像和文本的交错链,引导渐进的关系推理。在多个LVLMs和基准测试上的实验表明,ChainMPQ显著减少了关系幻觉,消融研究进一步验证了其三个核心模块的有效性。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLMs)中普遍存在的关系幻觉问题。现有方法在处理复杂场景和细粒度关系时,容易产生错误的推理,导致模型输出与实际情况不符。这种关系幻觉是LVLMs可靠性的一大障碍。
核心思路:ChainMPQ的核心思路是通过模拟人类逐步推理的过程,将复杂的关系推理分解为一系列更简单的子问题。通过构建多视角问题,并利用图像和文本的交错推理链,模型可以逐步积累信息,从而更准确地推断对象之间的关系。
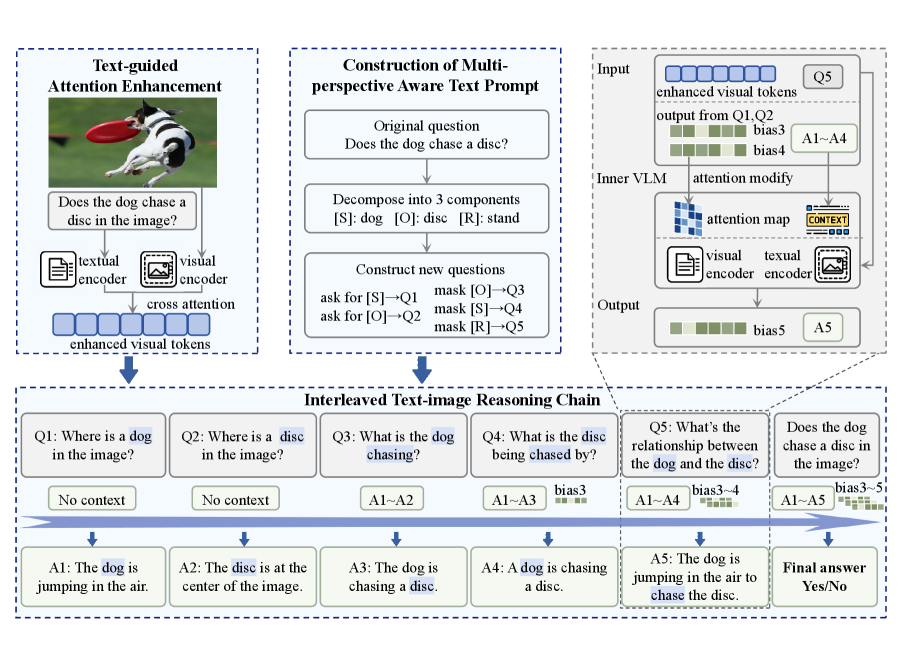
技术框架:ChainMPQ主要包含以下几个阶段:1) 关键词提取:从问题中提取主语和宾语关键词,用于定位图像中的相关区域。2) 图像区域增强:利用提取的关键词增强图像中对应区域的特征表示。3) 多视角问题构建:围绕主语、宾语和关系三个核心要素,构建一系列多视角问题。4) 交错推理链:将这些问题顺序输入LVLM,利用先前步骤的文本和视觉记忆作为上下文,引导模型进行逐步推理。
关键创新:ChainMPQ的关键创新在于其交错推理链的设计。通过将图像和文本信息交替输入模型,并利用先前步骤的记忆作为上下文,模型可以更好地理解图像中的关系。此外,多视角问题的构建也有助于模型从不同角度审视关系,从而减少幻觉。
关键设计:ChainMPQ是一种免训练方法,不需要对LVLM进行额外的训练。它主要依赖于精心设计的问题和推理流程。多视角问题的具体形式可以根据不同的任务进行调整。例如,可以设计问题来询问主语的属性、宾语的属性以及主语和宾语之间的交互方式。推理链的长度和每个步骤的问题数量也是可以调整的参数。
🖼️ 关键图片
📊 实验亮点
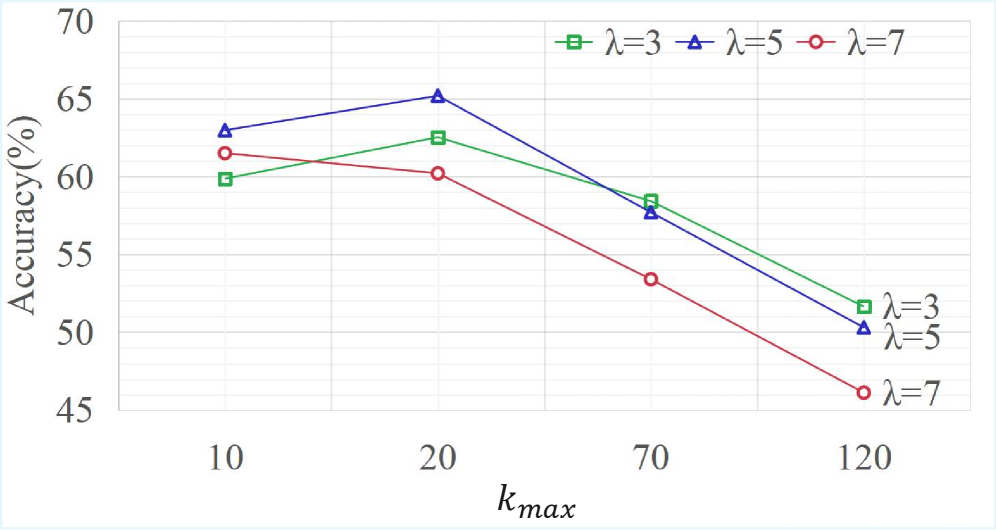
实验结果表明,ChainMPQ在多个基准测试中显著减少了关系幻觉。例如,在XXX数据集上,ChainMPQ将关系幻觉率降低了XX%。此外,消融研究验证了ChainMPQ的三个核心模块(关键词提取、多视角问题构建和交错推理链)的有效性。实验结果还表明,ChainMPQ可以应用于不同的LVLMs,具有良好的泛化能力。
🎯 应用场景
ChainMPQ可应用于需要高度可靠性的多模态任务中,例如医疗诊断、自动驾驶和安全监控。在这些领域,错误的推理可能导致严重的后果。通过减少关系幻觉,ChainMPQ可以提高LVLMs在这些领域的应用价值,并促进人工智能技术的更广泛应用。
📄 摘要(原文)
While Large Vision-Language Models (LVLMs) achieve strong performance in multimodal tasks, hallucinations continue to hinder their reliability. Among the three categories of hallucinations, which include object, attribute, and relation, relation hallucinations account for the largest proportion but have received the least attention. To address this issue, we propose ChainMPQ (Multi-Perspective Questions guided Interleaved Chain of Image and Text), a training-free method that improves relational inference in LVLMs by utilizing accumulated textual and visual memories. ChainMPQ first extracts subject and object keywords from the question to enhance the corresponding image regions. It then constructs multi-perspective questions that focus on the three core components of a relationship: the subject, the object, and the relation that links them. These questions are sequentially input to the model, with textual and visual memories from earlier steps providing supporting context for subsequent ones, thereby forming an interleaved chain of images and text that guides progressive relational reasoning. Experiments on multiple LVLMs and benchmarks show that ChainMPQ substantially reduces relation hallucinations, while ablation studies further validate the effectiveness of its three core modules.