Dropping the D: RGB-D SLAM Without the Depth Sensor
作者: Mert Kiray, Alican Karaomer, Benjamin Busam
分类: cs.CV, cs.RO
发布日期: 2025-10-07 (更新: 2025-11-02)
💡 一句话要点
DropD-SLAM:无需深度传感器的单目RGB SLAM,达到RGB-D级别精度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目SLAM 深度估计 实例分割 关键点检测 RGB-D SLAM 度量尺度 实时SLAM
📋 核心要点
- 传统RGB-D SLAM依赖深度传感器,成本较高且易受环境光照影响,限制了其应用场景。
- DropD-SLAM利用预训练的深度估计、关键点检测和实例分割模型,从单目图像中恢复深度信息,替代深度传感器。
- 实验表明,DropD-SLAM在精度上可媲美甚至超越传统RGB-D SLAM,同时保持了实时性,降低了硬件成本。
📝 摘要(中文)
本文提出DropD-SLAM,一个实时的单目SLAM系统,能够在不依赖深度传感器的情况下实现RGB-D级别的精度。该系统使用三个预训练的视觉模块替代主动深度输入:单目度量深度估计器、学习的关键点检测器和实例分割网络。动态对象通过膨胀的实例掩码进行抑制,而静态关键点被赋予预测的深度值并反投影到3D空间,形成度量尺度的特征。这些特征由一个未经修改的RGB-D SLAM后端处理,用于跟踪和建图。在TUM RGB-D基准测试中,DropD-SLAM在静态序列上实现了7.4厘米的平均ATE,在动态序列上实现了1.8厘米的平均ATE,在单GPU上以22 FPS运行,匹配或超过了最先进的RGB-D方法。这些结果表明,现代预训练视觉模型可以替代主动深度传感器,作为可靠的、实时的度量尺度来源,标志着朝着更简单、更具成本效益的SLAM系统迈出了一步。
🔬 方法详解
问题定义:现有的RGB-D SLAM系统依赖于深度传感器提供深度信息,这增加了系统的成本和复杂性,并且深度传感器的性能可能受到环境光照条件的影响。因此,如何在没有深度传感器的情况下,仅使用单目图像实现高精度的SLAM是一个重要的研究问题。
核心思路:DropD-SLAM的核心思路是利用预训练的深度估计模型从单目图像中预测深度信息,并结合关键点检测和实例分割模型来提取和过滤静态场景中的特征点。通过将这些特征点反投影到3D空间,可以构建具有度量尺度的3D地图,从而实现无需深度传感器的SLAM。
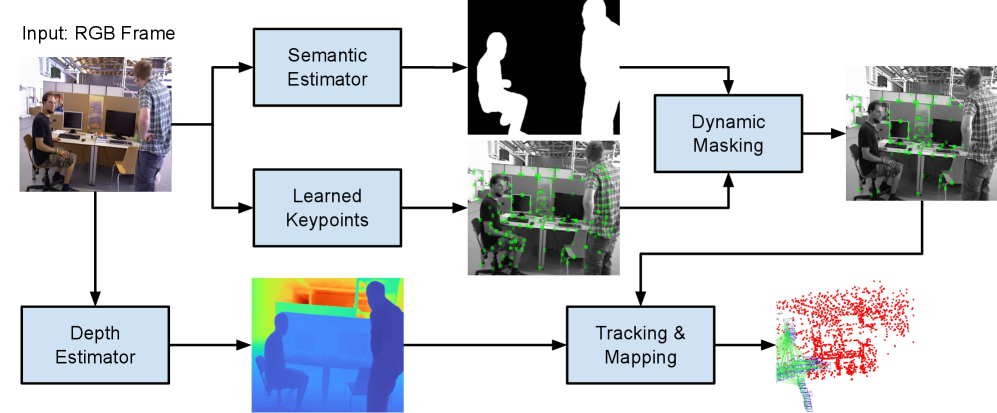
技术框架:DropD-SLAM系统主要包含以下几个模块:1) 单目深度估计模块:使用预训练的深度估计模型从单目图像中预测每个像素的深度值。2) 关键点检测模块:使用学习的关键点检测器提取图像中的关键点。3) 实例分割模块:使用实例分割网络分割图像中的对象,并使用膨胀的实例掩码抑制动态对象。4) 特征点生成模块:将静态关键点赋予预测的深度值,并反投影到3D空间,形成具有度量尺度的3D特征点。5) SLAM后端:使用一个未经修改的RGB-D SLAM后端,对生成的3D特征点进行跟踪和建图。
关键创新:DropD-SLAM的关键创新在于它成功地将预训练的视觉模型集成到SLAM系统中,以替代深度传感器。通过这种方式,系统可以在没有深度传感器的情况下实现与RGB-D SLAM相当的精度。此外,系统还采用了膨胀的实例掩码来抑制动态对象,提高了系统的鲁棒性。
关键设计:DropD-SLAM使用了预训练的单目深度估计模型,关键点检测器和实例分割网络。具体使用的模型类型和训练数据未知。实例分割掩码的膨胀大小是一个关键参数,需要根据场景中的动态对象的大小和运动速度进行调整。SLAM后端使用了未经修改的RGB-D SLAM算法,具体算法类型未知。
🖼️ 关键图片


📊 实验亮点
DropD-SLAM在TUM RGB-D基准测试中取得了显著的成果。在静态序列上,DropD-SLAM实现了7.4厘米的平均ATE,在动态序列上实现了1.8厘米的平均ATE。这些结果表明,DropD-SLAM在精度上可以与最先进的RGB-D方法相媲美,甚至在动态场景中表现更好。同时,DropD-SLAM在单GPU上以22 FPS运行,具有良好的实时性。
🎯 应用场景
DropD-SLAM具有广泛的应用前景,例如在资源受限的机器人应用中,可以降低硬件成本和功耗。在增强现实(AR)和虚拟现实(VR)领域,可以提供更轻便、更灵活的定位和建图解决方案。此外,该技术还可以应用于自动驾驶、无人机导航等领域,提高系统的环境感知能力。
📄 摘要(原文)
We present DropD-SLAM, a real-time monocular SLAM system that achieves RGB-D-level accuracy without relying on depth sensors. The system replaces active depth input with three pretrained vision modules: a monocular metric depth estimator, a learned keypoint detector, and an instance segmentation network. Dynamic objects are suppressed using dilated instance masks, while static keypoints are assigned predicted depth values and backprojected into 3D to form metrically scaled features. These are processed by an unmodified RGB-D SLAM back end for tracking and mapping. On the TUM RGB-D benchmark, DropD-SLAM attains 7.4 cm mean ATE on static sequences and 1.8 cm on dynamic sequences, matching or surpassing state-of-the-art RGB-D methods while operating at 22 FPS on a single GPU. These results suggest that modern pretrained vision models can replace active depth sensors as reliable, real-time sources of metric scale, marking a step toward simpler and more cost-effective SLAM systems.