VideoMiner: Iteratively Grounding Key Frames of Hour-Long Videos via Tree-based Group Relative Policy Optimization
作者: Xinye Cao, Hongcan Guo, Jiawen Qian, Guoshun Nan, Chao Wang, Yuqi Pan, Tianhao Hou, Xiaojuan Wang, Yutong Gao
分类: cs.CV, cs.AI
发布日期: 2025-10-07
备注: Accepted by ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出VideoMiner,通过树状结构和强化学习优化,解决长视频关键帧提取与理解难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 关键帧提取 多模态学习 强化学习 树状结构 视频摘要 大语言模型
📋 核心要点
- 现有方法在长视频理解中面临冗余信息干扰和动态适应复杂层级结构的挑战。
- VideoMiner通过迭代分割、描述和聚类视频,构建树状结构,并使用T-GRPO强化学习方法精确定位关键帧。
- 实验表明,VideoMiner在长视频理解任务中表现出色,并能自发生成推理链,提高准确性和效率。
📝 摘要(中文)
本文提出VideoMiner,旨在解决多模态大语言模型(MM-LLM)在理解长视频时面临的挑战。均匀采样帧会导致LLM被大量无关信息淹没。为了解决这个问题,VideoMiner迭代地分割、描述和聚类长视频,形成一个分层的树状结构,从而在保持时间连贯性的同时,将长视频分解为事件和帧。为了精确定位关键帧,本文引入了T-GRPO,一种基于树状结构的群体相对策略优化强化学习方法,用于指导VideoMiner的探索。T-GRPO专为树状结构设计,整合了事件级别的时空信息,并以问题为导向。实验结果表明,该方法在所有长视频理解任务中都取得了优异的性能,并揭示了一些有趣的现象,例如模型能够自发地生成推理链,以及树生长素能够动态调整扩展深度,从而提高准确性和效率。代码已公开。
🔬 方法详解
问题定义:长视频理解任务中,直接使用多模态大语言模型处理均匀采样的视频帧会引入大量冗余信息,导致模型性能下降。现有的层级关键帧提取方法虽然有所改进,但仍然难以有效缓解冗余信息干扰,并且缺乏动态适应复杂层级结构的能力。
核心思路:VideoMiner的核心思路是将长视频分解为更易于处理的层级结构,并通过强化学习方法在该结构上进行高效的关键帧选择。通过迭代地分割、描述和聚类视频,形成一个从长视频到事件再到帧的树状结构,从而降低冗余信息的影响。同时,利用树状结构的特性,设计专门的强化学习策略,以问题为导向,动态地探索和选择关键帧。
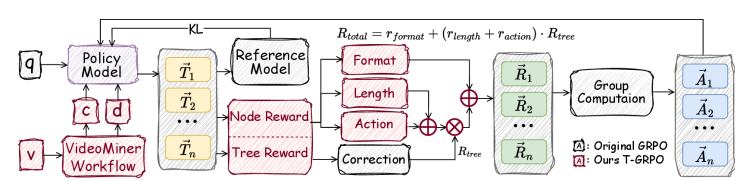
技术框架:VideoMiner的整体框架包括以下几个主要阶段:1) 视频分割:将长视频分割成多个片段。2) 视频描述:使用多模态模型为每个视频片段生成文本描述。3) 视频聚类:根据文本描述将视频片段聚类成不同的事件。4) 构建树状结构:基于分割和聚类结果,构建一个层级的树状结构,其中根节点代表整个视频,中间节点代表事件,叶子节点代表帧。5) 关键帧选择:使用T-GRPO强化学习方法,在树状结构上进行探索,选择关键帧。
关键创新:VideoMiner的关键创新在于两个方面:一是构建了基于迭代分割、描述和聚类的树状结构,有效地降低了长视频中的冗余信息;二是提出了T-GRPO强化学习方法,该方法专门为树状结构设计,能够整合事件级别的时空信息,并以问题为导向进行关键帧选择。T-GRPO与现有方法的本质区别在于,它不是直接在原始视频帧上进行选择,而是在一个结构化的表示上进行探索,从而提高了效率和准确性。
关键设计:T-GRPO的关键设计包括:1) 树状结构的构建方式,包括分割、描述和聚类的具体算法;2) 强化学习的状态表示,包括节点的时空信息和问题信息;3) 奖励函数的设计,用于指导模型选择关键帧;4) 树生长素的设计,用于动态调整树的扩展深度,平衡准确性和效率。具体的参数设置和网络结构在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VideoMiner在长视频理解任务中取得了显著的性能提升。T-GRPO强化学习方法能够自发地生成推理链,提高了模型的解释性。树生长素的设计能够动态调整树的扩展深度,在保证准确性的同时,提高了效率。具体的数据和对比结果可以在论文的实验部分找到。
🎯 应用场景
VideoMiner在视频监控、自动驾驶、智能安防、在线教育等领域具有广泛的应用前景。它可以用于自动提取视频摘要、生成视频字幕、进行视频内容分析和检索等任务,从而提高视频处理的效率和智能化水平。未来,VideoMiner还可以与其他AI技术相结合,例如与目标检测、行为识别等技术相结合,实现更高级的视频理解和应用。
📄 摘要(原文)
Understanding hour-long videos with multi-modal large language models (MM-LLMs) enriches the landscape of human-centered AI applications. However, for end-to-end video understanding with LLMs, uniformly sampling video frames results in LLMs being overwhelmed by a vast amount of irrelevant information as video length increases. Existing hierarchical key frame extraction methods improve the accuracy of video understanding but still face two critical challenges. 1) How can the interference of extensive redundant information in long videos be mitigated? 2) How can a model dynamically adapt to complex hierarchical structures while accurately identifying key frames? To address these issues, we propose VideoMiner, which iteratively segments, captions, and clusters long videos, forming a hierarchical tree structure. The proposed VideoMiner progresses from long videos to events to frames while preserving temporal coherence, effectively addressing the first challenge. To precisely locate key frames, we introduce T-GRPO, a tree-based group relative policy optimization in reinforcement learning method that guides the exploration of the VideoMiner. The proposed T-GRPO is specifically designed for tree structures, integrating spatiotemporal information at the event level while being guided by the question, thus solving the second challenge. We achieve superior performance in all long-video understanding tasks and uncover several interesting insights. Our proposed T-GRPO surprisingly incentivizes the model to spontaneously generate a reasoning chain. Additionally, the designed tree growth auxin dynamically adjusts the expansion depth, obtaining accuracy and efficiency gains. The code is publicly available at https://github.com/caoxinye/VideoMiner.