FoleyGRAM: Video-to-Audio Generation with GRAM-Aligned Multimodal Encoders
作者: Riccardo Fosco Gramaccioni, Christian Marinoni, Eleonora Grassucci, Giordano Cicchetti, Aurelio Uncini, Danilo Comminiello
分类: cs.SD, cs.CV, cs.LG, cs.MM, eess.AS
发布日期: 2025-10-07
备注: Acepted at IJCNN 2025
💡 一句话要点
FoleyGRAM:利用GRAM对齐的多模态编码器实现视频到音频的生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频到音频生成 多模态融合 格拉姆矩阵 语义对齐 扩散模型
📋 核心要点
- 现有视频到音频生成方法在语义对齐和时间同步方面存在挑战,难以生成与视频内容精确匹配的音频。
- FoleyGRAM利用GRAM对齐多模态嵌入,在视频、文本和音频之间建立更强的语义关联,从而实现更精确的音频生成控制。
- 实验结果表明,FoleyGRAM在语义对齐方面优于现有方法,能够生成与视频内容更相关的音频。
📝 摘要(中文)
本文提出了一种名为FoleyGRAM的视频到音频生成新方法,该方法强调通过对齐的多模态编码器进行语义调节。FoleyGRAM建立在视频到音频生成领域的现有进展之上,利用格拉姆表示对齐度量(GRAM)来对齐视频、文本和音频模态之间的嵌入,从而实现对音频生成过程的精确语义控制。FoleyGRAM的核心是一个基于扩散的音频合成模型,该模型以GRAM对齐的嵌入和波形包络为条件,确保语义丰富性以及与相应输入视频的时间对齐。我们在Greatest Hits数据集(视频到音频模型的标准基准)上评估了FoleyGRAM。实验表明,使用GRAM对齐多模态编码器可以增强系统将生成的音频与视频内容在语义上对齐的能力,从而推进了视频到音频合成的最新技术水平。
🔬 方法详解
问题定义:视频到音频生成旨在根据给定的视频内容合成相应的音频。现有方法通常难以保证生成音频与视频内容在语义上的精确对齐,以及在时间上的同步。这导致生成的音频可能与视频场景不协调,影响用户体验。
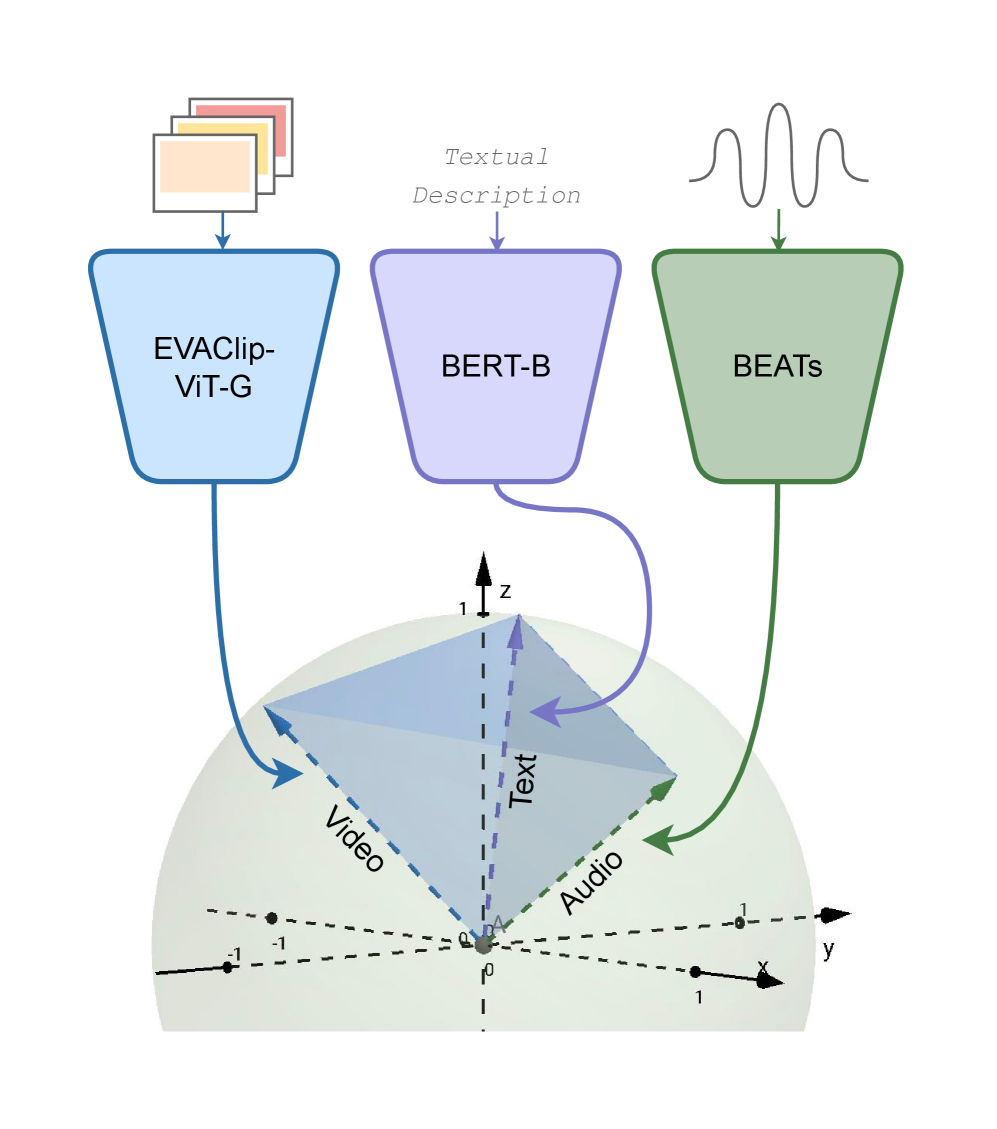
核心思路:FoleyGRAM的核心思路是利用格拉姆表示对齐度量(GRAM)来对齐不同模态(视频、文本、音频)的嵌入空间。通过最小化不同模态嵌入之间的GRAM距离,可以使它们在语义上更加一致,从而实现更精确的语义控制。这样,音频生成模型就可以更好地理解视频内容,并生成与之相关的音频。
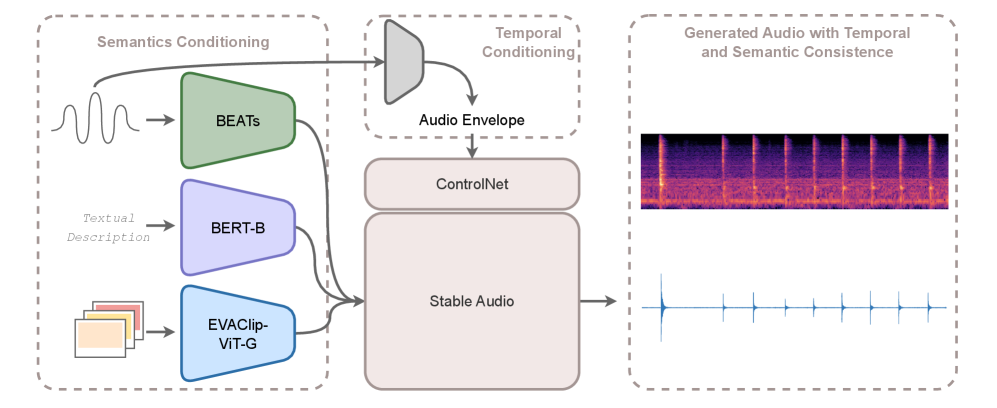
技术框架:FoleyGRAM的整体框架包括以下几个主要模块:1) 多模态编码器:用于提取视频、文本和音频的特征嵌入。2) GRAM对齐模块:利用GRAM损失函数对齐不同模态的嵌入空间。3) 基于扩散的音频合成模型:以GRAM对齐的嵌入和波形包络为条件,生成音频。该模型采用扩散模型,逐步从噪声中生成音频信号。
关键创新:FoleyGRAM最重要的技术创新点在于使用GRAM对齐多模态编码器。与传统的直接拼接或注意力机制相比,GRAM能够更有效地对齐不同模态的嵌入空间,从而实现更精确的语义控制。此外,结合波形包络作为条件,可以更好地保证生成音频与视频在时间上的同步。
关键设计:GRAM损失函数被设计用来最小化不同模态嵌入之间的格拉姆矩阵的距离。音频合成模型采用扩散模型,具体结构未知。实验中使用了Greatest Hits数据集,并与现有方法进行了比较。具体的参数设置和网络结构细节在论文中应该有更详细的描述,但摘要中未提及。
🖼️ 关键图片

📊 实验亮点
FoleyGRAM在Greatest Hits数据集上进行了评估,实验结果表明,通过GRAM对齐多模态编码器,系统能够更好地将生成的音频与视频内容在语义上对齐。具体性能数据和提升幅度在摘要中未给出,需要在论文中查找。
🎯 应用场景
FoleyGRAM技术可应用于电影制作、游戏开发、虚拟现实等领域,自动生成与视频内容匹配的音效和背景音乐,提高内容创作效率和用户体验。该技术还可用于视频修复,为无声视频或音频损坏的视频生成合适的音频内容。未来,该技术有望进一步发展,实现更逼真、更智能的音频生成。
📄 摘要(原文)
In this work, we present FoleyGRAM, a novel approach to video-to-audio generation that emphasizes semantic conditioning through the use of aligned multimodal encoders. Building on prior advancements in video-to-audio generation, FoleyGRAM leverages the Gramian Representation Alignment Measure (GRAM) to align embeddings across video, text, and audio modalities, enabling precise semantic control over the audio generation process. The core of FoleyGRAM is a diffusion-based audio synthesis model conditioned on GRAM-aligned embeddings and waveform envelopes, ensuring both semantic richness and temporal alignment with the corresponding input video. We evaluate FoleyGRAM on the Greatest Hits dataset, a standard benchmark for video-to-audio models. Our experiments demonstrate that aligning multimodal encoders using GRAM enhances the system's ability to semantically align generated audio with video content, advancing the state of the art in video-to-audio synthesis.