Teleportraits: Training-Free People Insertion into Any Scene
作者: Jialu Gao, K J Joseph, Fernando De La Torre
分类: cs.CV
发布日期: 2025-10-07
💡 一句话要点
Teleportraits:提出一种免训练的人物插入方法,实现任意场景下的人物合成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 人物插入 图像合成 扩散模型 免训练学习 自注意力机制 身份保持 场景理解
📋 核心要点
- 现有方法在人物插入任务中,通常将人物定位和个性化视为独立问题,忽略了二者关联,且依赖大量训练数据。
- Teleportraits 提出一种免训练的统一流程,利用预训练的文本到图像扩散模型,实现人物在复杂场景中的自然放置。
- 该方法结合反演技术和无分类器引导,实现全局编辑,并通过掩码引导自注意力机制,保证高质量的身份保留。
📝 摘要(中文)
本文提出了一种将人物从参考图像逼真地插入到背景场景中的方法。该任务极具挑战性,要求模型(1)确定人物的正确位置和姿势,以及(2)执行高质量的个性化,并以背景为条件。以往的方法通常将它们视为独立的问题,忽略了它们之间的相互联系,并且通常依赖于训练来实现高性能。本文介绍了一种统一的免训练流程,该流程利用预训练的文本到图像扩散模型。研究表明,扩散模型本身就具备将人物放置在复杂场景中的知识,而无需进行特定于任务的训练。通过将反演技术与无分类器引导相结合,该方法实现了可负担的全局编辑,从而将人物无缝地插入到场景中。此外,所提出的掩码引导自注意力机制可确保高质量的个性化,仅从单个参考图像中保留主体的身份、服装和身体特征。据我们所知,这是第一个以免训练的方式执行逼真的人物插入场景,并在各种复合场景图像中取得最先进的结果,在背景和主体中都具有出色的身份保留。
🔬 方法详解
问题定义:论文旨在解决将人物从参考图像逼真地插入到任意背景场景中的问题。现有方法通常需要大量训练数据,并且将人物定位和个性化视为独立问题,忽略了它们之间的相互联系,导致合成效果不佳,难以保证人物身份的一致性。
核心思路:论文的核心思路是利用预训练的文本到图像扩散模型,该模型已经具备了丰富的场景理解和生成能力。通过巧妙地利用扩散模型的先验知识,无需额外训练即可实现人物在场景中的自然放置和高质量的个性化。
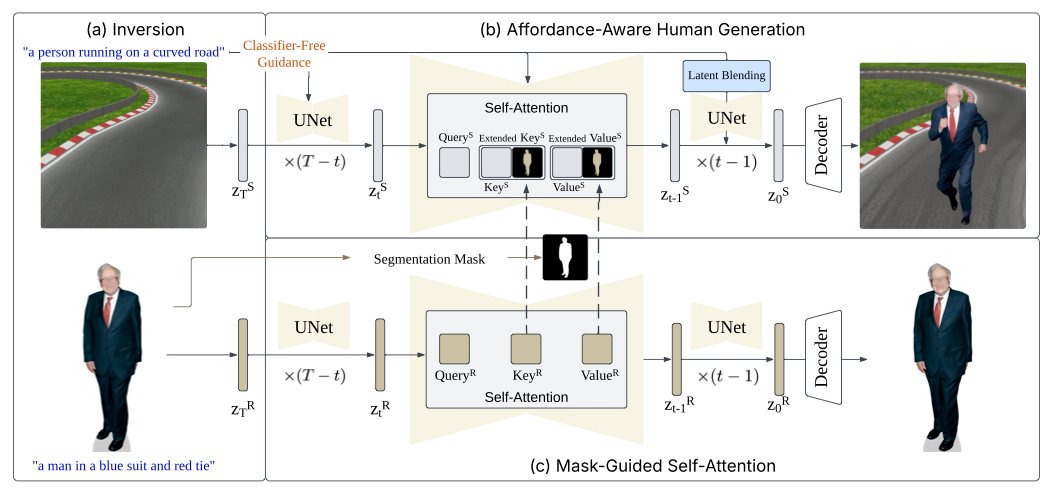
技术框架:Teleportraits 的整体流程主要包括以下几个阶段: 1. 场景反演:将目标背景场景图像反演到扩散模型的潜在空间中,得到一个潜在编码。 2. 人物定位:利用扩散模型的无分类器引导,在潜在空间中引导生成包含人物的场景,从而确定人物的位置和姿势。 3. 人物融合:使用掩码引导的自注意力机制,将参考图像中的人物特征融合到生成的场景中,同时保持人物的身份、服装和身体特征。 4. 图像生成:将修改后的潜在编码解码为最终的合成图像。
关键创新:该方法最重要的创新点在于提出了一个完全免训练的人物插入框架。与以往需要大量训练数据的方法不同,Teleportraits 充分利用了预训练扩散模型的强大生成能力,无需针对特定场景进行训练。此外,掩码引导的自注意力机制能够有效地融合人物特征,同时保持身份一致性,这也是一个重要的创新。
关键设计: * 无分类器引导:通过调整文本提示的强度,控制生成图像中人物的位置和姿势。 * 掩码引导自注意力:使用参考图像的人物掩码来引导自注意力机制,确保只有人物区域的特征被融合到生成图像中。 * 扩散模型选择:选择具有较强生成能力和场景理解能力的扩散模型,例如 Stable Diffusion。
🖼️ 关键图片

📊 实验亮点
Teleportraits 在人物插入任务上取得了最先进的结果,尤其是在身份保持方面表现出色。该方法在各种复杂的复合场景图像中,能够逼真地将人物插入到场景中,同时保持人物的身份、服装和身体特征。由于是免训练方法,Teleportraits 具有很强的泛化能力,可以应用于各种不同的场景和人物。
🎯 应用场景
该研究具有广泛的应用前景,例如虚拟现实/增强现实内容创作、电影特效制作、游戏角色定制、以及电商领域的服装搭配和虚拟试穿等。该方法无需训练的特性,降低了应用门槛,使得普通用户也能轻松地将自己或他人插入到各种场景中,创造个性化的视觉内容。未来,该技术有望进一步发展,实现更逼真、更可控的人物合成。
📄 摘要(原文)
The task of realistically inserting a human from a reference image into a background scene is highly challenging, requiring the model to (1) determine the correct location and poses of the person and (2) perform high-quality personalization conditioned on the background. Previous approaches often treat them as separate problems, overlooking their interconnections, and typically rely on training to achieve high performance. In this work, we introduce a unified training-free pipeline that leverages pre-trained text-to-image diffusion models. We show that diffusion models inherently possess the knowledge to place people in complex scenes without requiring task-specific training. By combining inversion techniques with classifier-free guidance, our method achieves affordance-aware global editing, seamlessly inserting people into scenes. Furthermore, our proposed mask-guided self-attention mechanism ensures high-quality personalization, preserving the subject's identity, clothing, and body features from just a single reference image. To the best of our knowledge, we are the first to perform realistic human insertions into scenes in a training-free manner and achieve state-of-the-art results in diverse composite scene images with excellent identity preservation in backgrounds and subjects.