HOI-R1: Exploring the Potential of Multimodal Large Language Models for Human-Object Interaction Detection
作者: Junwen Chen, Peilin Xiong, Keiji Yanai
分类: cs.CV, cs.AI
发布日期: 2025-10-07 (更新: 2026-02-01)
🔗 代码/项目: GITHUB
💡 一句话要点
HOI-R1:探索多模态大语言模型在人-物交互检测中的潜力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人-物交互检测 多模态大语言模型 强化学习 文本推理 视觉-语言模型
📋 核心要点
- 现有HOID方法依赖复杂的VLM集成,训练困难且不利于扩展。
- HOI-R1利用MLLM的推理能力,通过纯文本方式进行HOID,无需额外检测模块。
- 实验表明,HOI-R1显著提升了MLLM在HOID任务上的性能,并具有良好的泛化性。
📝 摘要(中文)
现有的人-物交互检测(HOID)方法高度依赖视觉-语言模型(VLM)的先验知识来增强交互识别能力。然而,将VLM的知识与来自目标检测器HOI实例表示连接的训练策略和模型架构具有挑战性,并且整个框架复杂,不利于进一步开发或应用。另一方面,多模态大语言模型(MLLM)在人-物交互检测中的内在推理能力尚未得到充分探索。受到最近使用强化学习(RL)方法训练MLLM的成功启发,我们提出了HOI-R1,首次探索了语言模型在HOID任务中的潜力,无需任何额外的检测模块。我们引入了一个HOI推理过程和HOID奖励函数,通过纯文本解决HOID任务。在HICO-DET上的多个开源MLLM(包括Qwen-VL系列(Qwen2.5-VL和Qwen3-VL)和Rex-Omni)的实验表明,性能得到了持续提升。特别是,HOI-R1将Qwen2.5-VL-3B的准确率提高了2倍,并具有出色的泛化能力。源代码可在https://github.com/cjw2021/HOI-R1获取。
🔬 方法详解
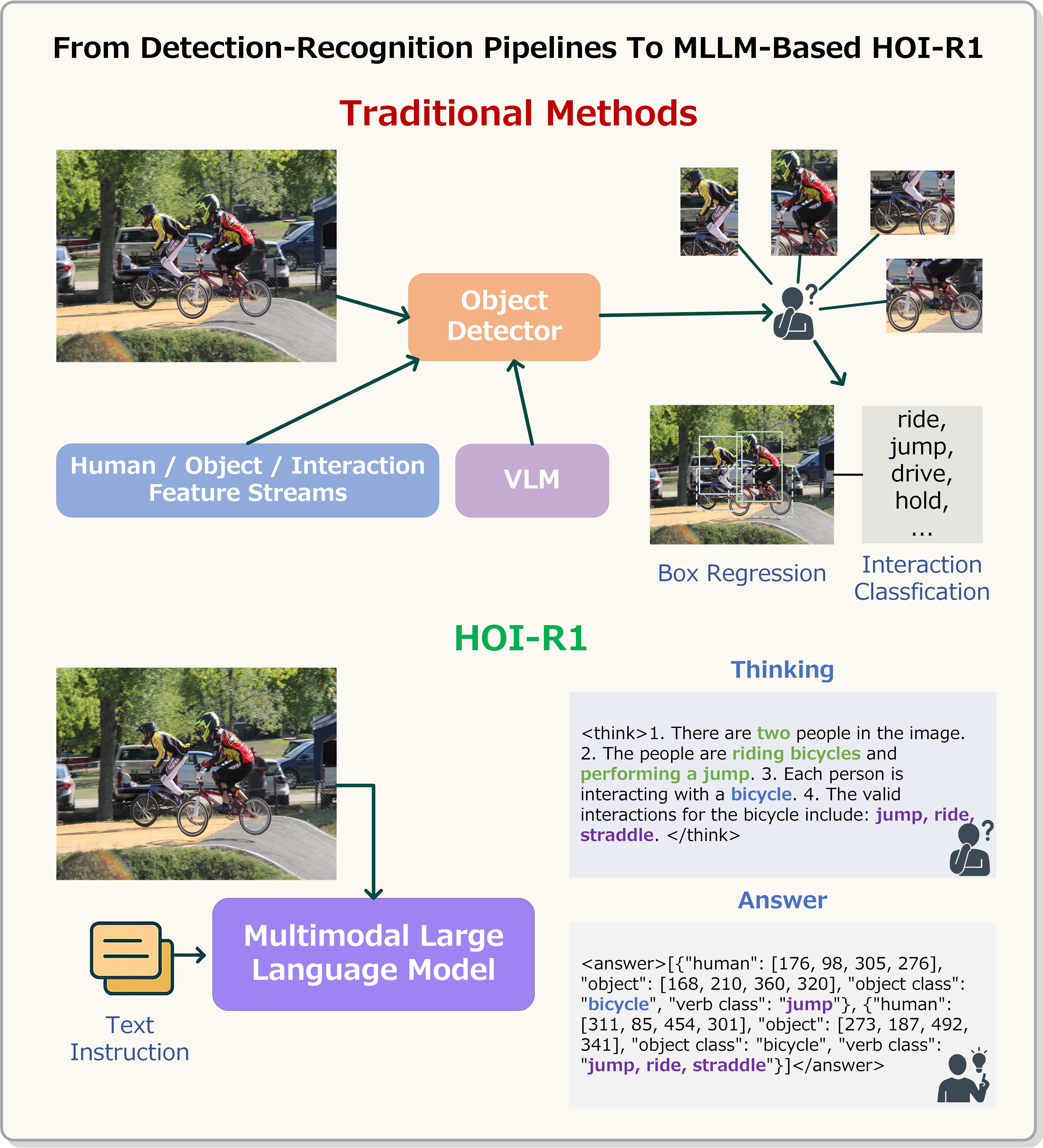
问题定义:现有HOID方法通常依赖于目标检测器和视觉-语言模型的结合,这种方法存在框架复杂、训练困难以及难以进一步开发和应用的问题。此外,如何有效地将视觉信息与语言知识融合也是一个挑战。现有方法未能充分挖掘多模态大语言模型(MLLM)本身在HOID任务中的推理能力。
核心思路:HOI-R1的核心思路是直接利用MLLM的语言推理能力来解决HOID任务,避免了传统方法中复杂的视觉模块和融合策略。通过将HOID任务转化为一个文本推理问题,并设计相应的奖励函数,引导MLLM学习HOI的知识。这种方法简化了整个流程,并充分利用了MLLM的潜力。
技术框架:HOI-R1的整体框架非常简洁。它主要包含以下几个阶段:1) 输入图像和相关的文本提示给MLLM;2) MLLM根据提示生成HOI描述;3) 使用HOID奖励函数评估生成的描述;4) 使用强化学习方法优化MLLM,使其能够生成更准确的HOI描述。整个过程无需额外的目标检测模块。
关键创新:HOI-R1最重要的创新点在于它首次探索了使用纯文本方式解决HOID任务的可能性,摆脱了对传统目标检测器的依赖。通过引入HOI推理过程和HOID奖励函数,有效地引导MLLM学习HOI知识,并生成准确的HOI描述。这种方法简化了HOID流程,并充分利用了MLLM的语言推理能力。
关键设计:HOI-R1的关键设计包括:1) 精心设计的文本提示,用于引导MLLM进行HOI推理;2) HOID奖励函数,用于评估MLLM生成的HOI描述的准确性。奖励函数可以根据不同的HOID指标进行设计,例如,可以考虑HOI三元组的准确性、完整性等。3) 使用强化学习算法(如PPO)优化MLLM,使其能够生成更符合要求的HOI描述。
🖼️ 关键图片

📊 实验亮点
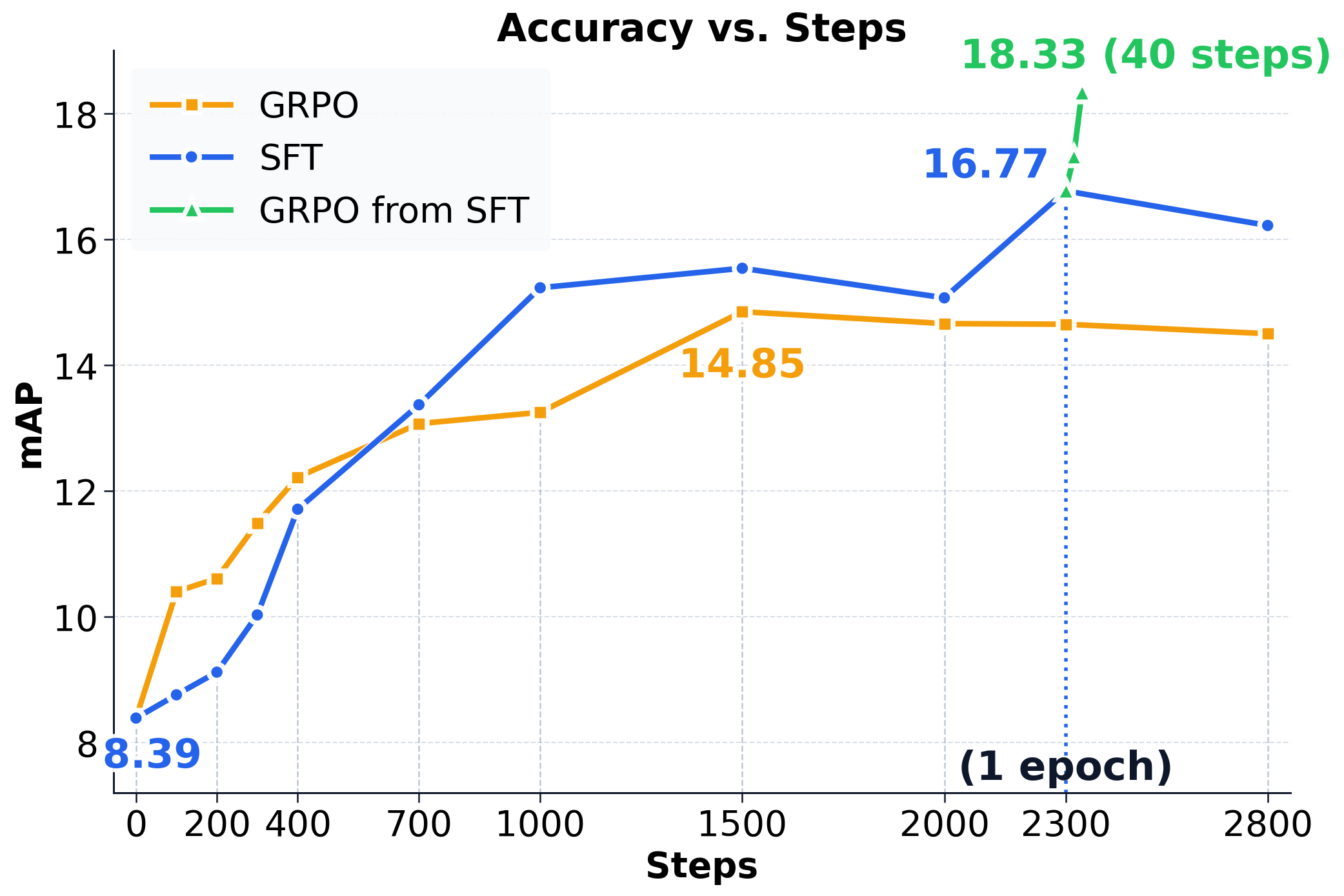
HOI-R1在HICO-DET数据集上取得了显著的性能提升。特别是,HOI-R1将Qwen2.5-VL-3B的准确率提高了2倍,并且在不同的MLLM上都表现出了一致的提升。这表明HOI-R1具有良好的泛化能力和有效性。
🎯 应用场景
HOI-R1具有广泛的应用前景,例如智能监控、人机交互、机器人导航等领域。它可以用于理解场景中人的行为和意图,从而实现更智能化的决策和控制。此外,该研究也为探索MLLM在其他视觉任务中的应用提供了新的思路。
📄 摘要(原文)
Recent human-object interaction detection (HOID) methods highly require prior knowledge from vision-language models (VLMs) to enhance the interaction recognition capabilities. The training strategies and model architectures for connecting the knowledge from VLMs to the HOI instance representations from the object detector are challenging, and the whole framework is complex for further development or application. On the other hand, the inherent reasoning abilities of multimodal large language models (MLLMs) on human-object interaction detection are under-explored. Inspired by the recent success of training MLLMs with reinforcement learning (RL) methods, we propose HOI-R1 and first explore the potential of the language model on the HOID task without any additional detection modules. We introduce an HOI reasoning process and HOID reward functions to solve the HOID task by pure text. Experiments on HICO-DET across multiple open-source MLLMs, including the Qwen-VL family (Qwen2.5-VL and Qwen3-VL) and Rex-Omni, show consistent improvements. Especially, HOI-R1 boosts Qwen2.5-VL-3B 2$\times$ accuracy with great generalization ability. The source code is available at https://github.com/cjw2021/HOI-R1.