ArchitectHead: Continuous Level of Detail Control for 3D Gaussian Head Avatars
作者: Peizhi Yan, Rabab Ward, Qiang Tang, Shan Du
分类: cs.CV
发布日期: 2025-10-07
💡 一句话要点
ArchitectHead:提出首个支持连续细节层次控制的3D高斯头部头像框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 头部头像 细节层次控制 UV特征场 神经渲染
📋 核心要点
- 现有的基于3D高斯溅射的头像通常依赖数万个高斯点,训练后高斯数量固定,无法灵活调整细节层次。
- ArchitectHead的核心在于将3D高斯参数化到2D UV特征空间,并使用UV特征场编码潜在特征,通过解码器生成3D高斯属性。
- 实验表明,该方法在最高细节层次下达到SOTA质量,在较低细节层次下保持接近SOTA的性能,同时显著提升了渲染速度。
📝 摘要(中文)
本文提出名为“ArchitectHead”的框架,用于创建支持连续细节层次(LOD)控制的3D高斯头部头像,这是首个此类框架。核心思想是将高斯参数化到2D UV特征空间中,并提出由多层可学习特征图组成的UV特征场来编码其潜在特征。一个轻量级的基于神经网络的解码器将这些潜在特征转换为用于渲染的3D高斯属性。ArchitectHead通过在所需分辨率下动态重采样UV特征场的特征图来控制高斯数量,从而实现高效且连续的LOD控制,无需重新训练。实验结果表明,ArchitectHead在最高LOD下实现了自重演和跨身份重演任务中最先进的(SOTA)质量,同时在较低LOD下保持接近SOTA的性能。在最低LOD下,我们的方法仅使用6.2%的高斯,质量适度下降(L1 Loss +7.9%,PSNR --0.97%,SSIM --0.6%,LPIPS Loss +24.1%),渲染速度几乎翻倍。
🔬 方法详解
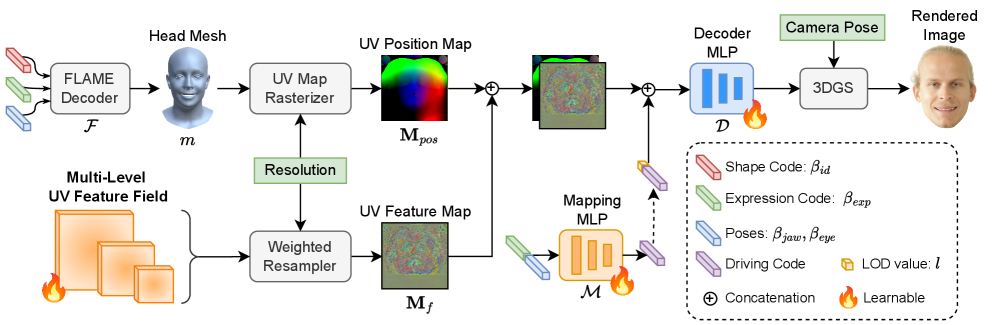
问题定义:现有基于3D高斯溅射的头部头像方法,其高斯数量在训练后固定,无法根据实际应用需求调整细节层次(LOD),难以在渲染效率和视觉质量之间取得平衡。这限制了其在需要不同LOD的应用场景中的使用。
核心思路:论文的核心思路是将3D高斯的属性映射到2D UV特征空间,并使用可学习的UV特征场来编码这些属性。通过在不同分辨率下对UV特征场进行采样,可以动态地控制高斯点的数量,从而实现连续的LOD控制。这种设计避免了重新训练的需要,并允许在运行时调整LOD。
技术框架:ArchitectHead框架主要包含以下几个模块:1) UV特征场:由多层可学习的特征图组成,用于编码3D高斯属性的潜在特征。2) UV参数化:将3D高斯点映射到2D UV空间。3) 解码器:一个轻量级的神经网络,将UV特征场中采样的特征解码为3D高斯属性,如位置、颜色、不透明度等。4) 渲染器:使用解码后的3D高斯属性进行渲染。
关键创新:该论文的关键创新在于提出了基于UV特征场的连续LOD控制方法。与现有方法相比,该方法无需重新训练即可实现LOD的动态调整,并且能够实现连续的LOD控制,而不仅仅是离散的几个级别。此外,将3D高斯属性映射到2D UV空间,使得可以使用卷积神经网络等成熟的技术来学习和编码这些属性。
关键设计:UV特征场由多层特征图组成,每一层对应不同的分辨率。解码器是一个轻量级的MLP网络,输入是UV特征场中采样的特征向量,输出是3D高斯属性。损失函数包括L1损失、PSNR、SSIM和LPIPS损失,用于优化UV特征场和解码器。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ArchitectHead在最高LOD下实现了SOTA的自重演和跨身份重演质量。在最低LOD下,仅使用6.2%的高斯点,质量仅有适度下降(L1 Loss +7.9%,PSNR -0.97%,SSIM -0.6%,LPIPS Loss +24.1%),但渲染速度几乎翻倍。这表明该方法能够在显著降低计算成本的同时,保持较好的视觉质量。
🎯 应用场景
ArchitectHead具有广泛的应用前景,例如在虚拟现实、增强现实、视频会议、游戏等领域,可以根据设备的计算能力和网络带宽动态调整头部头像的细节层次,从而在保证视觉质量的同时,提高渲染效率和用户体验。该技术还可以用于创建高度逼真的数字替身,用于社交互动和内容创作。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) has enabled photorealistic and real-time rendering of 3D head avatars. Existing 3DGS-based avatars typically rely on tens of thousands of 3D Gaussian points (Gaussians), with the number of Gaussians fixed after training. However, many practical applications require adjustable levels of detail (LOD) to balance rendering efficiency and visual quality. In this work, we propose "ArchitectHead", the first framework for creating 3D Gaussian head avatars that support continuous control over LOD. Our key idea is to parameterize the Gaussians in a 2D UV feature space and propose a UV feature field composed of multi-level learnable feature maps to encode their latent features. A lightweight neural network-based decoder then transforms these latent features into 3D Gaussian attributes for rendering. ArchitectHead controls the number of Gaussians by dynamically resampling feature maps from the UV feature field at the desired resolutions. This method enables efficient and continuous control of LOD without retraining. Experimental results show that ArchitectHead achieves state-of-the-art (SOTA) quality in self and cross-identity reenactment tasks at the highest LOD, while maintaining near SOTA performance at lower LODs. At the lowest LOD, our method uses only 6.2\% of the Gaussians while the quality degrades moderately (L1 Loss +7.9\%, PSNR --0.97\%, SSIM --0.6\%, LPIPS Loss +24.1\%), and the rendering speed nearly doubles.