Factuality Matters: When Image Generation and Editing Meet Structured Visuals
作者: Le Zhuo, Songhao Han, Yuandong Pu, Boxiang Qiu, Sayak Paul, Yue Liao, Yihao Liu, Jie Shao, Xi Chen, Si Liu, Hongsheng Li
分类: cs.CV
发布日期: 2025-10-06
备注: Project page: https://structvisuals.github.io
💡 一句话要点
提出StructBench基准和统一模型,解决结构化视觉内容生成与编辑中的事实性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构化视觉 图像生成 图像编辑 多模态学习 事实性 知识推理 基准测试
📋 核心要点
- 现有视觉生成模型难以处理结构化视觉内容,缺乏对组合规划、文本渲染和多模态推理的有效支持,导致生成结果的事实性不足。
- 论文提出一种统一模型,通过集成VLM和FLUX.1 Kontext,并采用三阶段训练课程,增强模型对结构化视觉内容的多模态理解和推理能力。
- 实验结果表明,该模型在StructBench基准上取得了显著的编辑性能提升,并且推理时推理能够持续提升各种架构的性能。
📝 摘要(中文)
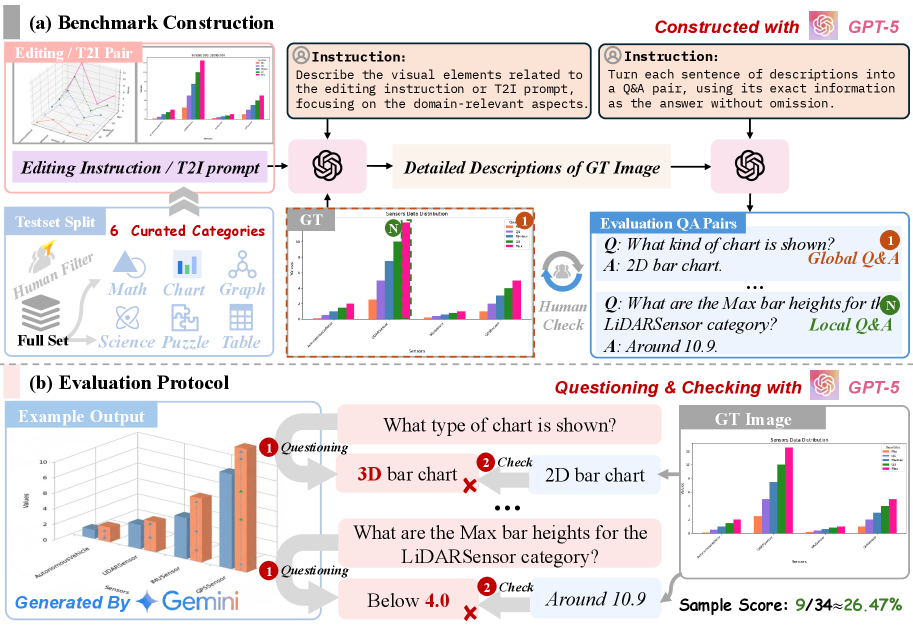
现代视觉生成模型在创建美观的自然图像方面表现出色,但在生成或编辑结构化视觉内容(如图表、示意图和数学图形)时面临挑战,这些内容需要组合规划、文本渲染和多模态推理以保证事实准确性。为了解决这个问题,我们对该领域进行了首次全面、系统的研究,包括数据构建、模型训练和评估基准。首先,我们构建了一个包含130万个高质量结构化图像对的大规模数据集,这些图像对来自可执行的绘图程序,并使用思维链推理注释进行增强。在此基础上,我们训练了一个统一模型,该模型通过轻量级连接器将VLM与FLUX.1 Kontext集成,以增强多模态理解。一个三阶段的训练课程实现了渐进式特征对齐、知识注入和推理增强生成,并在推理时通过外部推理器进一步提升。最后,我们引入了StructBench,这是一个用于生成和编辑的新基准,包含超过1700个具有挑战性的实例,以及一个配套的评估指标StructScore,它采用多轮问答协议来评估细粒度的事实准确性。对15个模型的评估表明,即使是领先的闭源系统也远未达到令人满意的水平。我们的模型获得了强大的编辑性能,并且推理时推理在各种架构中都产生了持续的收益。通过发布数据集、模型和基准,我们旨在推进结构化视觉的统一多模态基础。
🔬 方法详解
问题定义:论文旨在解决现有视觉生成模型在处理结构化视觉内容(如图表、示意图、数学公式等)时,难以保证生成或编辑结果的事实准确性的问题。现有方法通常侧重于自然图像的生成,缺乏对结构化视觉内容特有的组合规划、文本渲染和多模态推理能力,导致生成结果与原始数据或指令不符。
核心思路:论文的核心思路是构建一个统一的多模态模型,该模型能够理解结构化视觉内容的内在结构和语义信息,并利用外部推理器进行推理,从而生成或编辑具有事实准确性的结构化视觉内容。通过数据增强、模型架构设计和训练策略优化,提升模型对结构化视觉内容的理解和生成能力。
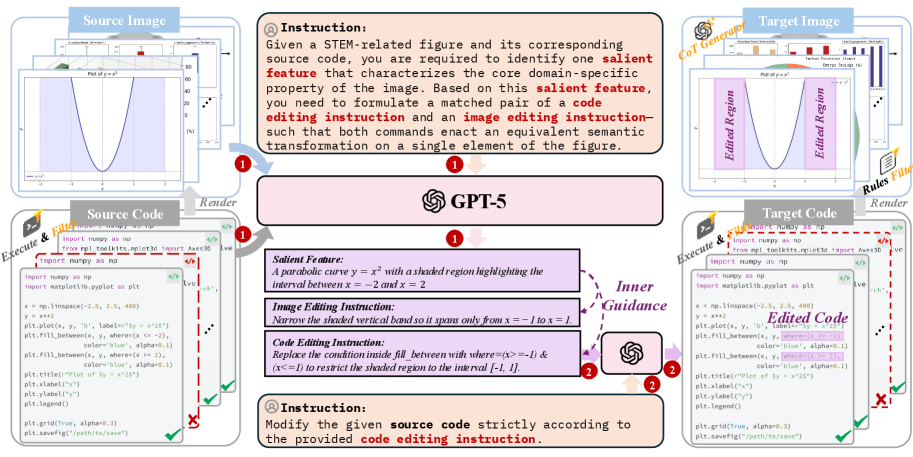
技术框架:整体框架包含数据构建、模型训练和评估基准三个主要部分。数据构建阶段,作者构建了一个包含130万个高质量结构化图像对的大规模数据集,并使用思维链推理注释进行增强。模型训练阶段,作者训练了一个统一模型,该模型通过轻量级连接器将VLM与FLUX.1 Kontext集成。评估基准阶段,作者引入了StructBench基准和StructScore评估指标。
关键创新:论文的关键创新在于:1) 首次对结构化视觉内容的生成与编辑问题进行了全面、系统的研究;2) 构建了一个大规模、高质量的结构化视觉数据集,并进行了思维链推理注释;3) 提出了一个统一的多模态模型,该模型能够有效处理结构化视觉内容,并利用外部推理器进行推理;4) 提出了StructBench基准和StructScore评估指标,用于评估模型在结构化视觉内容生成与编辑方面的性能。
关键设计:模型采用三阶段训练课程:1) 特征对齐阶段,将VLM和FLUX.1 Kontext的特征进行对齐;2) 知识注入阶段,将外部知识注入到模型中;3) 推理增强生成阶段,利用外部推理器进行推理,并生成最终结果。StructScore评估指标采用多轮问答协议,以评估模型生成结果的细粒度事实准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,论文提出的模型在StructBench基准上取得了显著的性能提升,尤其是在编辑任务上表现出色。与现有模型相比,该模型能够生成或编辑具有更高事实准确性的结构化视觉内容。此外,推理时推理能够持续提升各种架构的性能,表明了该方法的有效性和通用性。
🎯 应用场景
该研究成果可应用于自动化图表生成、科学文献编辑、教育资源创建等领域。例如,可以根据用户输入的文本描述自动生成图表,或者根据用户的编辑指令修改现有的图表,从而提高工作效率和内容质量。未来,该技术有望应用于更广泛的结构化视觉内容处理任务,例如自动生成数学公式、电路图等。
📄 摘要(原文)
While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.