Beyond Random: Automatic Inner-loop Optimization in Dataset Distillation
作者: Muquan Li, Hang Gou, Dongyang Zhang, Shuang Liang, Xiurui Xie, Deqiang Ouyang, Ke Qin
分类: cs.CV, cs.LG
发布日期: 2025-10-06 (更新: 2026-02-03)
备注: Accepted by NeurIPS 2025
💡 一句话要点
提出AT-BPTT,通过自动内循环优化提升数据集蒸馏性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 内循环优化 自动截断反向传播 梯度优化 低秩Hessian近似
📋 核心要点
- 现有数据集蒸馏方法依赖随机截断策略,忽略了神经网络在不同训练阶段的学习动态差异,导致优化效果不佳。
- AT-BPTT 框架通过概率机制选择时间步,并基于梯度变化自适应调整窗口大小,实现动态截断反向传播。
- 实验结果表明,AT-BPTT 在多个数据集上显著提升了模型准确率,并加速了内循环优化,降低了内存消耗。
📝 摘要(中文)
为了应对高效深度学习日益增长的需求,数据集蒸馏已成为一种关键技术,它能够在压缩训练数据集的同时保持模型性能。然而,现有的数据集蒸馏内循环优化方法通常依赖于随机截断策略,缺乏灵活性,并且常常产生次优结果。本文观察到神经网络在不同的训练阶段(早期、中期和晚期)表现出不同的学习动态,这使得随机截断效率低下。为了解决这个局限性,我们提出了一种新的框架——自动截断反向传播(AT-BPTT),它可以根据内在的梯度行为动态地调整截断位置和窗口大小。AT-BPTT 引入了三个关键组件:(1)一种用于阶段感知的时间步选择的概率机制;(2)一种基于梯度变化的自适应窗口大小调整策略;(3)一种用于减少计算开销的低秩 Hessian 近似。在 CIFAR-10、CIFAR-100、Tiny-ImageNet 和 ImageNet-1K 上的大量实验表明,AT-BPTT 实现了最先进的性能,与基线方法相比,平均提高了 6.16% 的准确率。此外,我们的方法将内循环优化加速了 3.9 倍,同时节省了 63% 的内存成本。
🔬 方法详解
问题定义:数据集蒸馏旨在用远小于原始数据集的合成数据集训练模型,同时保持模型性能。现有的内循环优化方法,如随机截断反向传播(Random Truncated BPTT),在训练过程中采用固定的截断位置和窗口大小,忽略了神经网络在不同训练阶段的学习动态变化,导致优化效率低下和性能瓶颈。
核心思路:AT-BPTT 的核心思路是根据神经网络在不同训练阶段的梯度行为,自适应地调整截断位置和窗口大小。通过动态地选择更有信息量的时间步进行反向传播,并根据梯度变化调整窗口大小,从而提高优化效率和模型性能。
技术框架:AT-BPTT 框架主要包含三个关键组件:1) 阶段感知的时间步选择:使用概率机制,根据当前训练阶段(早期、中期、晚期)的重要性,选择更有信息量的时间步进行反向传播。2) 自适应窗口大小调整:基于梯度变化动态调整窗口大小,当梯度变化剧烈时,增大窗口大小以捕捉更多信息;当梯度变化平缓时,减小窗口大小以减少计算量。3) 低秩 Hessian 近似:为了降低计算开销,采用低秩 Hessian 近似来估计梯度变化。
关键创新:AT-BPTT 的关键创新在于其动态调整截断位置和窗口大小的能力。与传统的随机截断方法相比,AT-BPTT 能够根据神经网络的学习动态,自适应地选择更有信息量的时间步进行反向传播,从而提高优化效率和模型性能。此外,AT-BPTT 还引入了低秩 Hessian 近似来降低计算开销,使其更适用于大规模数据集。
关键设计:AT-BPTT 使用一个概率分布来选择时间步,该概率分布根据当前训练阶段进行调整。例如,在训练初期,可能更倾向于选择较早的时间步,而在训练后期,则更倾向于选择较晚的时间步。自适应窗口大小调整策略基于梯度变化的指数移动平均,当梯度变化超过一定阈值时,窗口大小会相应增大或减小。低秩 Hessian 近似采用 Lanczos 算法来估计 Hessian 矩阵的特征值和特征向量,从而降低计算复杂度。
🖼️ 关键图片
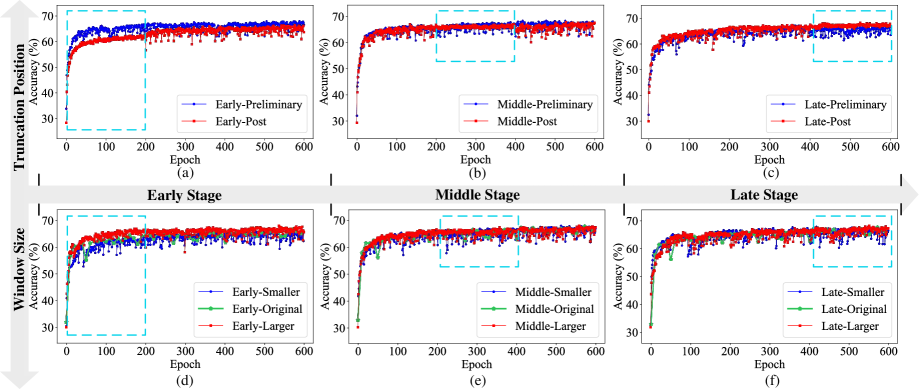


📊 实验亮点
实验结果表明,AT-BPTT 在 CIFAR-10、CIFAR-100、Tiny-ImageNet 和 ImageNet-1K 等数据集上取得了显著的性能提升,平均准确率比基线方法提高了 6.16%。此外,AT-BPTT 还将内循环优化加速了 3.9 倍,同时节省了 63% 的内存成本。这些结果表明,AT-BPTT 是一种高效且有效的内循环优化方法,可以显著提升数据集蒸馏的性能。
🎯 应用场景
AT-BPTT 在数据集蒸馏领域具有广泛的应用前景,可以用于压缩大规模数据集,加速模型训练,并降低存储成本。该方法可以应用于图像分类、目标检测、自然语言处理等多个领域,尤其适用于资源受限的场景,如移动设备和嵌入式系统。此外,AT-BPTT 的自适应优化策略也可以推广到其他深度学习任务中,例如元学习和持续学习。
📄 摘要(原文)
The growing demand for efficient deep learning has positioned dataset distillation as a pivotal technique for compressing training dataset while preserving model performance. However, existing inner-loop optimization methods for dataset distillation typically rely on random truncation strategies, which lack flexibility and often yield suboptimal results. In this work, we observe that neural networks exhibit distinct learning dynamics across different training stages-early, middle, and late-making random truncation ineffective. To address this limitation, we propose Automatic Truncated Backpropagation Through Time (AT-BPTT), a novel framework that dynamically adapts both truncation positions and window sizes according to intrinsic gradient behavior. AT-BPTT introduces three key components: (1) a probabilistic mechanism for stage-aware timestep selection, (2) an adaptive window sizing strategy based on gradient variation, and (3) a low-rank Hessian approximation to reduce computational overhead. Extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that AT-BPTT achieves state-of-the-art performance, improving accuracy by an average of 6.16% over baseline methods. Moreover, our approach accelerates inner-loop optimization by 3.9x while saving 63% memory cost.