AvatarVTON: 4D Virtual Try-On for Animatable Avatars
作者: Zicheng Jiang, Jixin Gao, Shengfeng He, Xinzhe Li, Yulong Zheng, Zhaotong Yang, Junyu Dong, Yong Du
分类: cs.CV
发布日期: 2025-10-06
💡 一句话要点
AvatarVTON:提出首个用于可动画Avatar的4D虚拟试穿框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 虚拟试穿 4D建模 服装形变 光流估计 数字人
📋 核心要点
- 现有虚拟试穿方法难以处理动态服装交互,且通常依赖多视角数据或物理引擎,限制了其应用范围。
- AvatarVTON通过互易流校正器稳定Avatar拟合,并利用非线性形变器实现服装的自适应形变,从而在单视角监督下实现逼真的4D虚拟试穿。
- 实验结果表明,AvatarVTON在保真度、多样性和动态真实感方面均表现出色,为AR/VR等应用提供了新的解决方案。
📝 摘要(中文)
本文提出AvatarVTON,这是首个4D虚拟试穿框架,它仅需单张店内服装图像即可生成逼真的试穿效果,支持自由姿势控制、新视角渲染和多样化的服装选择。与现有方法不同,AvatarVTON在单视角监督下支持动态服装交互,无需多视角服装捕获或物理先验。该框架包含两个关键模块:(1)互易流校正器,一种无需先验的光流校正策略,可稳定Avatar拟合并确保时间一致性;(2)非线性形变器,将高斯图分解为视角-姿势不变和视角-姿势特定分量,从而实现自适应的非线性服装形变。为了建立4D虚拟试穿的基准,我们使用统一的模块扩展了现有的基线,以进行公平的定性和定量比较。大量实验表明,AvatarVTON实现了高保真度、多样性和动态服装真实感,非常适合AR/VR、游戏和数字人应用。
🔬 方法详解
问题定义:现有虚拟试穿方法通常需要多视角服装数据或者依赖复杂的物理引擎来模拟服装的动态行为,这限制了其在实际应用中的可行性。此外,如何保证试穿结果在不同姿势和视角下的时间一致性也是一个挑战。因此,论文旨在解决单视角条件下,可动画Avatar的4D虚拟试穿问题,即给定单张服装图像,生成Avatar在不同姿势和视角下的逼真试穿效果,并保证时间上的连贯性。
核心思路:论文的核心思路是将服装的形变分解为视角-姿势不变和视角-姿势特定的两个部分。通过学习这种分解,可以更好地控制服装的形变,使其能够适应Avatar的姿势和视角变化。同时,利用互易流校正器来稳定Avatar的拟合,从而保证时间一致性。这种设计避免了对多视角数据和物理引擎的依赖,使得在单视角条件下实现逼真的4D虚拟试穿成为可能。
技术框架:AvatarVTON框架主要包含两个模块:互易流校正器(Reciprocal Flow Rectifier)和非线性形变器(Non-Linear Deformer)。首先,互易流校正器用于校正Avatar的拟合结果,使其更加稳定和准确。然后,非线性形变器将服装的高斯图分解为视角-姿势不变和视角-姿势特定的两个分量,并根据Avatar的姿势和视角对服装进行形变。最后,将形变后的服装贴合到Avatar上,生成最终的试穿效果。
关键创新:论文的关键创新在于提出了互易流校正器和非线性形变器。互易流校正器是一种无需先验知识的光流校正策略,可以有效地稳定Avatar的拟合,保证时间一致性。非线性形变器通过将服装形变分解为视角-姿势不变和视角-姿势特定的两个分量,实现了对服装形变的精细控制,从而生成更加逼真的试穿效果。与现有方法相比,AvatarVTON无需多视角数据和物理引擎,降低了对数据的要求,提高了实用性。
关键设计:互易流校正器通过计算前向和后向光流,并利用互易一致性约束来校正光流,从而提高光流的准确性。非线性形变器使用高斯图来表示服装的形状,并通过神经网络学习视角-姿势不变和视角-姿势特定的形变参数。损失函数包括重建损失、光流损失和时间一致性损失,用于约束Avatar的拟合和服装的形变。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


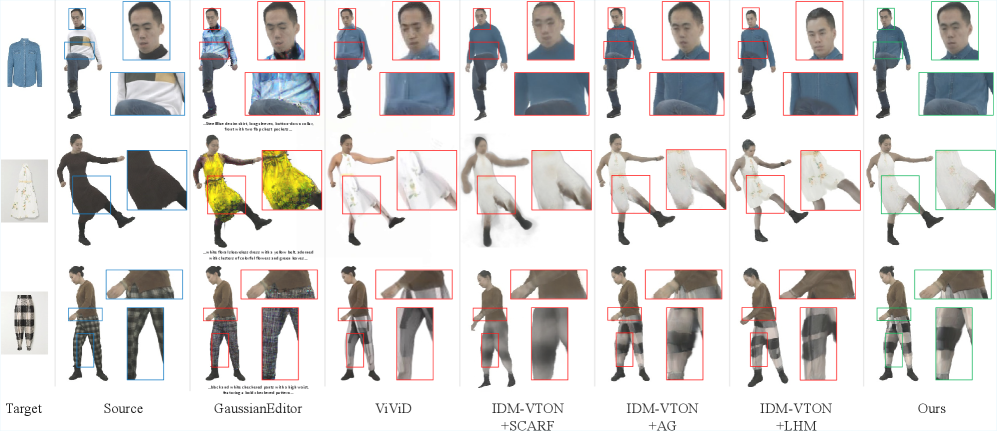
📊 实验亮点
实验结果表明,AvatarVTON在4D虚拟试穿任务上取得了显著的性能提升。与现有基线方法相比,AvatarVTON在保真度、多样性和动态真实感方面均表现出色。定性结果显示,AvatarVTON生成的试穿效果更加逼真,能够更好地模拟服装的动态行为。定量结果也表明,AvatarVTON在各项指标上均优于现有方法,证明了其有效性。
🎯 应用场景
AvatarVTON具有广泛的应用前景,包括AR/VR虚拟试穿、游戏角色定制、数字人服装设计等。用户可以通过该技术,在虚拟环境中自由尝试各种服装,无需实际购买即可体验穿搭效果。此外,该技术还可以用于生成各种风格的数字人形象,为游戏和娱乐产业提供新的内容创作方式。未来,AvatarVTON有望成为时尚产业和数字娱乐领域的重要工具。
📄 摘要(原文)
We propose AvatarVTON, the first 4D virtual try-on framework that generates realistic try-on results from a single in-shop garment image, enabling free pose control, novel-view rendering, and diverse garment choices. Unlike existing methods, AvatarVTON supports dynamic garment interactions under single-view supervision, without relying on multi-view garment captures or physics priors. The framework consists of two key modules: (1) a Reciprocal Flow Rectifier, a prior-free optical-flow correction strategy that stabilizes avatar fitting and ensures temporal coherence; and (2) a Non-Linear Deformer, which decomposes Gaussian maps into view-pose-invariant and view-pose-specific components, enabling adaptive, non-linear garment deformations. To establish a benchmark for 4D virtual try-on, we extend existing baselines with unified modules for fair qualitative and quantitative comparisons. Extensive experiments show that AvatarVTON achieves high fidelity, diversity, and dynamic garment realism, making it well-suited for AR/VR, gaming, and digital-human applications.