A Comparative Study of Vision Transformers and CNNs for Few-Shot Rigid Transformation and Fundamental Matrix Estimation
作者: Alon Kaya, Igal Bilik, Inna Stainvas
分类: cs.CV
发布日期: 2025-10-06
💡 一句话要点
对比ViT与CNN在少样本刚性变换和本质矩阵估计中的性能差异
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉Transformer 卷积神经网络 少样本学习 几何估计 刚性变换 本质矩阵 跨域泛化 对比学习
📋 核心要点
- 现有方法在低数据量下,难以平衡局部和全局特征,导致几何估计任务性能不佳。
- 本文对比了CNN和ViT在少样本几何估计任务中的性能,探索了不同架构的优势。
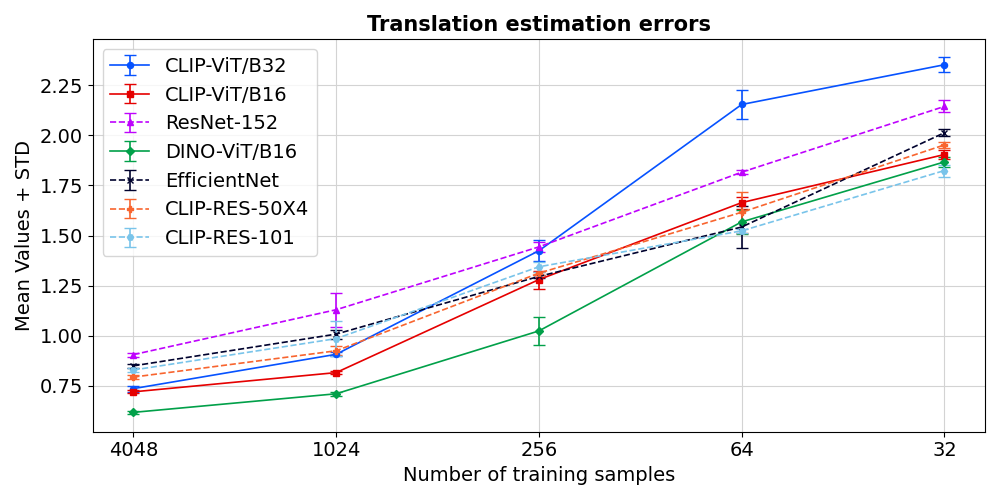
- 实验表明,ViT在大数据量下表现更优,而CNN在小数据量下通过归纳偏置实现可比性能。
📝 摘要(中文)
视觉Transformer (ViT) 和大规模卷积神经网络 (CNN) 通过预训练的特征表示重塑了计算机视觉领域,为各种任务实现了强大的迁移学习。然而,它们作为骨干架构在低数据情况下处理涉及图像形变的几何估计任务的效率仍然是一个悬而未决的问题。本文考虑了两个这样的任务:1) 估计图像对之间的2D刚性变换;2) 预测立体图像对的本质矩阵,这是自动驾驶、机器人和3D场景重建等各种应用中的重要问题。本文系统地比较了大规模CNN(ResNet、EfficientNet、CLIP-ResNet)与基于ViT的基础模型(CLIP-ViT变体和DINO)在各种数据规模设置(包括少样本场景)下的性能。这些预训练模型针对分类或对比学习进行了优化,鼓励它们主要关注高层语义。所考虑的任务需要不同地平衡局部和全局特征,这对直接采用这些模型作为骨干提出了挑战。经验比较分析表明,与从头开始训练类似,ViT在大型下游数据场景中的微调优于CNN。然而,在小数据场景中,CNN的归纳偏置和较小的容量改善了它们的性能,使其能够与ViT相匹配。此外,ViT在数据分布发生变化的跨域评估中表现出更强的泛化能力。这些结果强调了仔细选择模型架构进行微调的重要性,从而激发了未来对平衡局部和全局表示的混合架构的研究。
🔬 方法详解
问题定义:论文旨在研究在少样本学习场景下,视觉Transformer (ViT) 和卷积神经网络 (CNN) 在几何估计任务中的性能差异。具体任务包括二维刚性变换估计和本质矩阵预测。现有方法,尤其是直接应用预训练模型,难以在低数据量下平衡局部和全局特征,导致几何估计精度下降。
核心思路:论文的核心思路是通过对比实验,分析不同架构(ViT和CNN)在不同数据量下的性能表现,揭示它们在几何估计任务中的优势和劣势。通过观察它们在少样本和大数据量下的表现,以及在跨域泛化能力上的差异,从而为模型选择和架构设计提供指导。
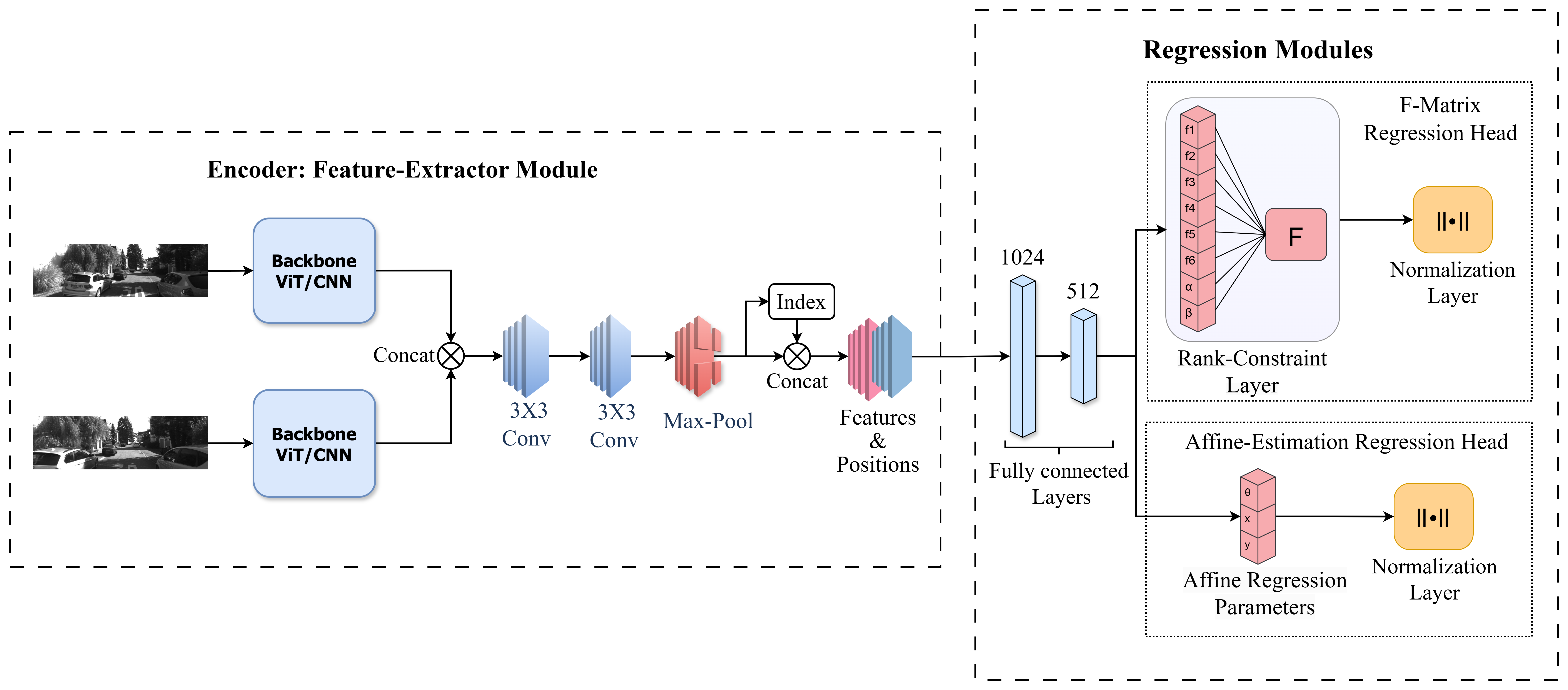
技术框架:整体框架包括以下步骤:1) 选择预训练的CNN (ResNet, EfficientNet, CLIP-ResNet) 和 ViT (CLIP-ViT, DINO) 模型作为骨干网络。2) 在二维刚性变换估计和本质矩阵预测两个任务上进行微调。3) 在不同数据量(包括少样本场景)下进行训练和测试。4) 进行跨域泛化能力评估。
关键创新:论文的关键创新在于系统性地对比了ViT和CNN在少样本几何估计任务中的性能,并揭示了它们在不同数据量和跨域泛化能力上的差异。强调了在低数据量下,CNN的归纳偏置能够使其性能与ViT相媲美,而在大数据量下,ViT则表现更优。
关键设计:论文的关键设计包括:1) 选择具有代表性的大规模预训练CNN和ViT模型。2) 使用标准的数据集和评估指标进行实验。3) 仔细控制实验变量,例如数据量和训练参数,以确保结果的可靠性。4) 采用跨域评估来测试模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在大数据量下,ViT在几何估计任务中优于CNN,但在小数据量下,CNN通过其归纳偏置可以达到与ViT相当的性能。此外,ViT在跨域评估中表现出更强的泛化能力。这些发现强调了在选择模型架构时,需要仔细考虑数据量和任务特性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人、三维场景重建等领域,尤其是在数据量有限的情况下,为选择合适的模型架构提供了理论依据。通过了解不同架构的优势和劣势,可以更好地设计和优化几何估计系统,提高其在实际应用中的性能和鲁棒性。未来的研究可以探索混合架构,结合CNN和ViT的优点,以实现更好的性能。
📄 摘要(原文)
Vision-transformers (ViTs) and large-scale convolution-neural-networks (CNNs) have reshaped computer vision through pretrained feature representations that enable strong transfer learning for diverse tasks. However, their efficiency as backbone architectures for geometric estimation tasks involving image deformations in low-data regimes remains an open question. This work considers two such tasks: 1) estimating 2D rigid transformations between pairs of images and 2) predicting the fundamental matrix for stereo image pairs, an important problem in various applications, such as autonomous mobility, robotics, and 3D scene reconstruction. Addressing this intriguing question, this work systematically compares large-scale CNNs (ResNet, EfficientNet, CLIP-ResNet) with ViT-based foundation models (CLIP-ViT variants and DINO) in various data size settings, including few-shot scenarios. These pretrained models are optimized for classification or contrastive learning, encouraging them to focus mostly on high-level semantics. The considered tasks require balancing local and global features differently, challenging the straightforward adoption of these models as the backbone. Empirical comparative analysis shows that, similar to training from scratch, ViTs outperform CNNs during refinement in large downstream-data scenarios. However, in small data scenarios, the inductive bias and smaller capacity of CNNs improve their performance, allowing them to match that of a ViT. Moreover, ViTs exhibit stronger generalization in cross-domain evaluation where the data distribution changes. These results emphasize the importance of carefully selecting model architectures for refinement, motivating future research towards hybrid architectures that balance local and global representations.