Beyond the Seen: Bounded Distribution Estimation for Open-Vocabulary Learning
作者: Xiaomeng Fan, Yuchuan Mao, Zhi Gao, Yuwei Wu, Jin Chen, Yunde Jia
分类: cs.CV, cs.LG
发布日期: 2025-10-06
💡 一句话要点
提出基于有界分布估计的开放词汇学习方法,通过生成未见类数据提升泛化能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇学习 分布估计 数据生成 未见类数据 有界误差 泛化能力 后验概率 语义树
📋 核心要点
- 现有开放词汇学习方法仅利用已见类数据进行分布估计,忽略了未见类数据,导致估计误差难以控制。
- 通过生成未见类数据,论文提出了一种有界分布估计方法,从而有效控制开放词汇学习中的估计误差。
- 实验结果表明,该方法在多个数据集上显著优于现有基线方法,性能提升高达14%。
📝 摘要(中文)
开放词汇学习需要在开放环境中建模数据分布,该分布包含已见类和未见类数据。现有方法通常仅使用已见类数据估计开放环境中的分布,但由于缺乏未见类信息,估计误差难以确定。本文指出,学习超越已见类对于有界估计误差至关重要。理论上证明,通过生成未见类数据可以有效估计分布,从而限制估计误差的上界。基于此,提出一种新的开放词汇学习方法,该方法生成未见类数据以估计开放环境中的分布,包含类域数据生成流程和分布对齐算法。数据生成流程在分层语义树和从已见类数据推断的域信息的指导下生成未见类数据,从而促进准确的分布估计。利用生成的数据,分布对齐算法估计并最大化后验概率,以增强开放词汇学习中的泛化能力。在11个数据集上的大量实验表明,该方法优于基线方法高达14%,突出了其有效性和优越性。
🔬 方法详解
问题定义:开放词汇学习旨在处理包含已知类别和未知类别的数据分布建模问题。现有方法主要依赖于已知类别的数据进行分布估计,然而,由于缺乏对未知类别的考虑,导致模型在开放环境下的泛化能力受限,估计误差难以控制。这种仅基于已见类数据进行分布估计的方式,本质上无法准确反映真实的数据分布情况。
核心思路:论文的核心思路是通过生成未见类数据来弥补现有方法的不足。通过引入对未见类数据的建模,可以更全面地估计开放环境下的数据分布,从而有效地限制估计误差的上界。这种方法的核心在于模拟真实世界中可能出现的未知类别,并将其纳入模型的训练过程中,从而提高模型的鲁棒性和泛化能力。
技术框架:该方法主要包含两个核心模块:类域数据生成流程和分布对齐算法。首先,类域数据生成流程利用分层语义树和从已见类数据推断的域信息,生成具有代表性的未见类数据。然后,分布对齐算法利用生成的数据,估计并最大化后验概率,从而优化模型的参数,提高其在开放词汇学习中的泛化能力。整个框架旨在通过生成高质量的未见类数据,并将其与已见类数据进行有效整合,从而实现更准确的分布估计。
关键创新:该方法最重要的技术创新在于提出了基于数据生成的有界分布估计方法。与现有方法不同,该方法不再仅仅依赖于已见类数据,而是主动生成未见类数据,从而更全面地建模开放环境下的数据分布。这种方法有效地解决了现有方法中由于缺乏未见类信息而导致的估计误差问题,从而提高了模型的泛化能力和鲁棒性。
关键设计:类域数据生成流程的关键在于如何生成具有代表性的未见类数据。论文利用分层语义树来指导数据的生成过程,确保生成的数据在语义上具有一定的合理性。此外,论文还从已见类数据中推断域信息,并将其用于指导未见类数据的生成,从而确保生成的数据在域上与真实数据具有一定的相似性。分布对齐算法的关键在于如何有效地利用生成的数据来优化模型的参数。论文通过最大化后验概率来实现分布对齐,从而确保模型能够更好地适应开放环境下的数据分布。
🖼️ 关键图片

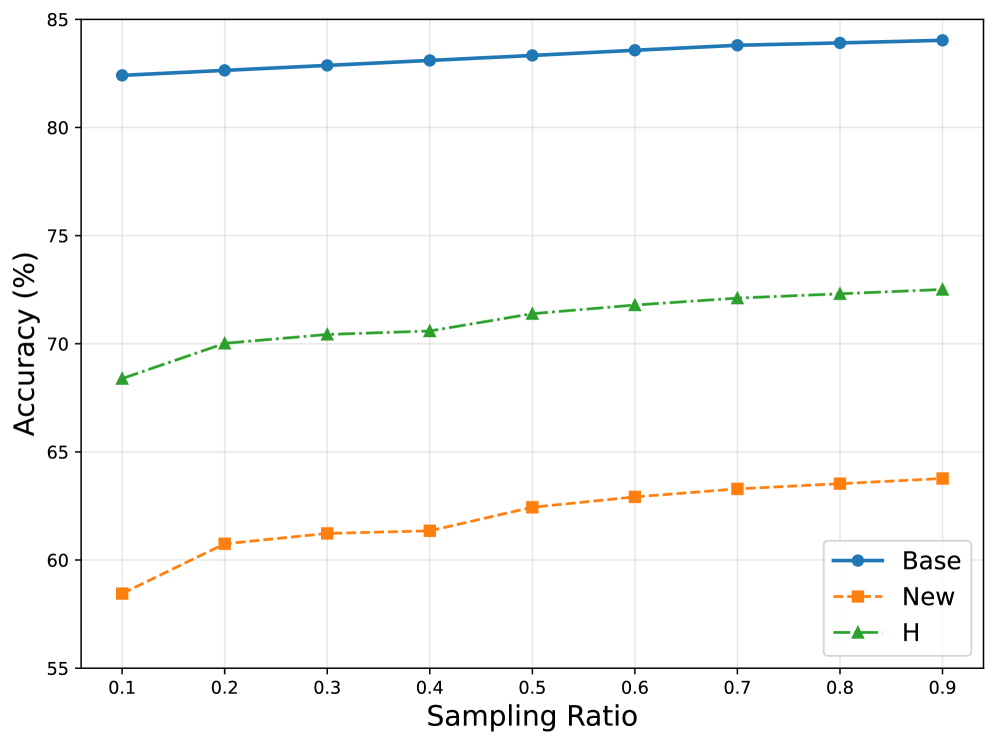

📊 实验亮点
实验结果表明,该方法在11个数据集上均取得了显著的性能提升,相较于现有基线方法,性能提升高达14%。这充分证明了该方法在开放词汇学习中的有效性和优越性。尤其是在处理包含大量未知类别的数据集时,该方法的优势更加明显。
🎯 应用场景
该研究成果可广泛应用于图像识别、自然语言处理等领域,尤其是在需要处理开放世界数据的场景下,例如智能监控、自动驾驶、机器人导航等。通过提高模型对未知类别的识别能力,可以有效提升系统的鲁棒性和可靠性,降低误判风险,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Open-vocabulary learning requires modeling the data distribution in open environments, which consists of both seen-class and unseen-class data. Existing methods estimate the distribution in open environments using seen-class data, where the absence of unseen classes makes the estimation error inherently unidentifiable. Intuitively, learning beyond the seen classes is crucial for distribution estimation to bound the estimation error. We theoretically demonstrate that the distribution can be effectively estimated by generating unseen-class data, through which the estimation error is upper-bounded. Building on this theoretical insight, we propose a novel open-vocabulary learning method, which generates unseen-class data for estimating the distribution in open environments. The method consists of a class-domain-wise data generation pipeline and a distribution alignment algorithm. The data generation pipeline generates unseen-class data under the guidance of a hierarchical semantic tree and domain information inferred from the seen-class data, facilitating accurate distribution estimation. With the generated data, the distribution alignment algorithm estimates and maximizes the posterior probability to enhance generalization in open-vocabulary learning. Extensive experiments on $11$ datasets demonstrate that our method outperforms baseline approaches by up to $14\%$, highlighting its effectiveness and superiority.