Object-Centric Representation Learning for Enhanced 3D Scene Graph Prediction
作者: KunHo Heo, GiHyun Kim, SuYeon Kim, MyeongAh Cho
分类: cs.CV
发布日期: 2025-10-06 (更新: 2026-02-02)
备注: Accepted by NeurIPS 2025. Code: https://github.com/VisualScienceLab-KHU/OCRL-3DSSG-Codes
🔗 代码/项目: GITHUB
💡 一句话要点
提出面向对象的表征学习方法,提升3D场景图预测精度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景图预测 对象表征学习 对比学习 图神经网络 机器人视觉
📋 核心要点
- 现有3D场景图预测方法过度依赖图神经网络,忽略了对象特征判别能力不足的问题,导致性能瓶颈。
- 论文提出解耦对象表征学习与场景图预测的对比预训练策略,并设计高判别性的对象特征编码器。
- 实验表明,该方法显著提升了对象分类和关系预测的精度,并在3DSSG数据集上超越了现有最佳方法。
📝 摘要(中文)
3D语义场景图预测旨在检测3D场景中的对象及其语义关系,是机器人和AR/VR应用的关键技术。现有研究虽已关注数据集限制并探索了包括开放词汇设置在内的多种方法,但常常未能优化对象和关系特征的表征能力,过度依赖图神经网络,而忽略了判别能力的不足。本文通过大量分析表明,对象特征的质量对整体场景图精度起着至关重要的作用。为此,我们设计了一个高判别性的对象特征编码器,并采用对比预训练策略,将对象表征学习与场景图预测解耦。该设计不仅提高了对象分类精度,还直接改善了关系预测。值得注意的是,将我们预训练的编码器插入到现有框架中时,我们观察到所有评估指标的显著性能提升。此外,现有方法尚未充分利用关系信息的集成,我们有效地结合了几何和语义特征,实现了卓越的关系预测。在3DSSG数据集上的综合实验表明,我们的方法显著优于以往的最先进方法。代码已公开。
🔬 方法详解
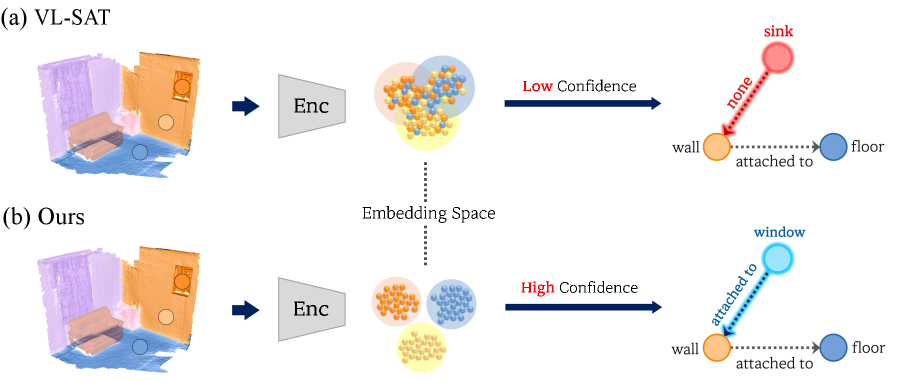
问题定义:3D场景图预测旨在从3D场景中检测物体及其语义关系。现有方法主要痛点在于对象和关系特征的表征能力不足,过度依赖图神经网络进行关系推理,而忽略了高质量对象特征的重要性,导致整体性能受限。
核心思路:论文的核心思路是将对象表征学习与场景图预测解耦。通过对比学习预训练一个高判别性的对象特征编码器,使其能够提取更具区分性的对象特征。这样,后续的场景图预测模块就可以基于更优质的对象特征进行关系推理,从而提高整体性能。
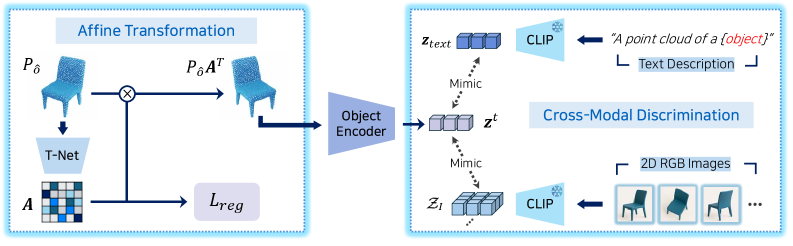
技术框架:整体框架包含两个主要阶段:1) 对象特征编码器的对比预训练阶段;2) 基于预训练编码器的场景图预测阶段。在预训练阶段,使用对比学习损失来训练对象特征编码器,使其能够区分不同的对象实例。在场景图预测阶段,将预训练的编码器集成到现有的场景图预测框架中,并利用几何和语义特征进行关系预测。
关键创新:论文的关键创新在于解耦对象表征学习与场景图预测,并采用对比学习预训练对象特征编码器。这种方法能够有效地提高对象特征的判别能力,从而改善整体的场景图预测性能。此外,论文还结合了几何和语义特征,以提高关系预测的准确性。
关键设计:论文设计了一个高判别性的对象特征编码器,具体结构未知(论文未详细描述)。对比学习损失函数的具体形式未知(论文未详细描述)。几何特征和语义特征的融合方式未知(论文未详细描述)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在3DSSG数据集上显著优于现有最佳方法。将预训练的编码器插入到现有框架中时,所有评估指标均有显著提升。具体的性能提升数据未知(论文未提供具体数值)。该方法验证了对象特征质量对场景图预测的重要性,并提供了一种有效的提升对象特征表征能力的方法。
🎯 应用场景
该研究成果可应用于机器人导航、场景理解、增强现实和虚拟现实等领域。高质量的3D场景图能够帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在AR/VR应用中,准确的场景图可以提供更逼真的沉浸式体验,并支持更丰富的交互功能。未来,该技术有望推动这些领域的发展。
📄 摘要(原文)
3D Semantic Scene Graph Prediction aims to detect objects and their semantic relationships in 3D scenes, and has emerged as a crucial technology for robotics and AR/VR applications. While previous research has addressed dataset limitations and explored various approaches including Open-Vocabulary settings, they frequently fail to optimize the representational capacity of object and relationship features, showing excessive reliance on Graph Neural Networks despite insufficient discriminative capability. In this work, we demonstrate through extensive analysis that the quality of object features plays a critical role in determining overall scene graph accuracy. To address this challenge, we design a highly discriminative object feature encoder and employ a contrastive pretraining strategy that decouples object representation learning from the scene graph prediction. This design not only enhances object classification accuracy but also yields direct improvements in relationship prediction. Notably, when plugging in our pretrained encoder into existing frameworks, we observe substantial performance improvements across all evaluation metrics. Additionally, whereas existing approaches have not fully exploited the integration of relationship information, we effectively combine both geometric and semantic features to achieve superior relationship prediction. Comprehensive experiments on the 3DSSG dataset demonstrate that our approach significantly outperforms previous state-of-the-art methods. Our code is publicly available at https://github.com/VisualScienceLab-KHU/OCRL-3DSSG-Codes.